 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATT-CR: Adaptive Triangular Transformer for Cloud Removal
Jun 04, 2026Cloud removal aims to accurately reconstruct the ground objects obscured by clouds in remote sensing images. Existing Transformer-based methods utilizing self-attention have shown impressive results by effectively modeling long-range dependencies in cloudy images. However, they suffer from the following issues: 1) the high computational complexity of self-attention limits scalability; 2) treating both cloudy and clean pixels as valid within the attention computation brings disturbances in subsequent layers, leading to suboptimal performance. To address these challenges, we propose the Adaptive Triangular Transformer for Cloud Removal (ATT-CR), a model that effectively reduces computational costs and mitigates interference from cloudy pixels. Specifically, it consists of two core components: Triangular Attention (TAN) and Feature Selected Gating Module (FSGM). TAN employs lower and upper triangular matrices to approximate Softmax attention with O(N) computational complexity, significantly reducing the computational costs. The FSGM, on the other hand, integrates with TAN to adaptively distinguish between cloudy and clean features, which minimizes the introduction of invalid information into subsequent layers. Extensive experiments on cloud removal benchmarks demonstrate that ATT-CR delivers superior performance compared to existing methods.
Think before Go: Hierarchical Reasoning for Image-goal Navigation
Apr 19, 2026Image-goal navigation steers an agent to a target location specified by an image in unseen environments. Existing methods primarily handle this task by learning an end-to-end navigation policy, which compares the similarities of target and observation images and directly predicts the actions. However, when the target is distant or lies in another room, such methods fail to extract informative visual cues, leading the agent to wander around. Motivated by the human cognitive principle that deliberate, high-level reasoning guides fast, reactive execution in complex tasks, we propose Hierarchical Reasoning Navigation (HRNav), a framework that decomposes image-goal navigation into high-level planning and low-level execution. In high-level planning, a vision-language model is trained on a self-collected dataset to generate a short-horizon plan, such as whether the agent should walk through the door or down the hallway. This downgrades the difficulty of the long-horizon task, making it more amenable to the execution part. In low-level execution, an online reinforcement learning policy is utilized to decide actions conditioned on the short-horizon plan. We also devise a novel Wandering Suppression Penalty (WSP) to further reduce the wandering problem. Together, these components form a hierarchical framework for Image-Goal Navigation. Extensive experiments in both simulation and real-world environments demonstrate the superiority of our method.
Dual-Anchoring: Addressing State Drift in Vision-Language Navigation
Apr 19, 2026Vision-Language Navigation(VLN) requires an agent to navigate through 3D environments by following natural language instructions. While recent Video Large Language Models(Video-LLMs) have largely advanced VLN, they remain highly susceptible to State Drift in long scenarios. In these cases, the agent's internal state drifts away from the true task execution state, leading to aimless wandering and failure to execute essential maneuvers in the instruction. We attribute this failure to two distinct cognitive deficits: Progress Drift, where the agent fails to distinguish completed sub-goals from remaining ones, and Memory Drift, where the agent's history representations degrade, making it lose track of visited landmarks. In this paper, we propose a Dual-Anchoring Framework that explicitly anchors the instruction progress and history representations. First, to address progress drift, we introduce Instruction Progress Anchoring, which supervises the agent to generate structured text tokens that delineate completed versus remaining sub-goals. Second, to mitigate memory drift, we propose Memory Landmark Anchoring, which utilizes a Landmark-Centric World Model to retrospectively predict object-centric embeddings extracted by the Segment Anything Model, compelling the agent to explicitly verify past observations and preserve distinct representations of visited landmarks. Facilitating this framework, we curate two extensive datasets: 3.6 million samples with explicit progress descriptions, and 937k grounded landmark data for retrospective verification. Extensive experiments in both simulation and real-world environments demonstrate the superiority of our method, achieving a 15.2% improvement in Success Rate and a remarkable 24.7% gain on long-horizon trajectories. To facilitate further research, we will release our code, data generation pipelines, and the collected datasets.
HiMemVLN: Enhancing Reliability of Open-Source Zero-Shot Vision-and-Language Navigation with Hierarchical Memory System
Mar 16, 2026LLM-based agents have demonstrated impressive zero-shot performance in vision-language navigation (VLN) tasks. However, most zero-shot methods primarily rely on closed-source LLMs as navigators, which face challenges related to high token costs and potential data leakage risks. Recent efforts have attempted to address this by using open-source LLMs combined with a spatiotemporal CoT framework, but they still fall far short compared to closed-source models. In this work, we identify a critical issue, Navigation Amnesia, through a detailed analysis of the navigation process. This issue leads to navigation failures and amplifies the gap between open-source and closed-source methods. To address this, we propose HiMemVLN, which incorporates a Hierarchical Memory System into a multimodal large model to enhance visual perception recall and long-term localization, mitigating the amnesia issue and improving the agent's navigation performance. Extensive experiments in both simulated and real-world environments demonstrate that HiMemVLN achieves nearly twice the performance of the open-source state-of-the-art method. The code is available at https://github.com/lvkailin0118/HiMemVLN.
Semantic-aware Representation Learning for Homography Estimation
Jul 18, 2024



Homography estimation is the task of determining the transformation from an image pair. Our approach focuses on employing detector-free feature matching methods to address this issue. Previous work has underscored the importance of incorporating semantic information, however there still lacks an efficient way to utilize semantic information. Previous methods suffer from treating the semantics as a pre-processing, causing the utilization of semantics overly coarse-grained and lack adaptability when dealing with different tasks. In our work, we seek another way to use the semantic information, that is semantic-aware feature representation learning framework.Based on this, we propose SRMatcher, a new detector-free feature matching method, which encourages the network to learn integrated semantic feature representation.Specifically, to capture precise and rich semantics, we leverage the capabilities of recently popularized vision foundation models (VFMs) trained on extensive datasets. Then, a cross-images Semantic-aware Fusion Block (SFB) is proposed to integrate its fine-grained semantic features into the feature representation space. In this way, by reducing errors stemming from semantic inconsistencies in matching pairs, our proposed SRMatcher is able to deliver more accurate and realistic outcomes. Extensive experiments show that SRMatcher surpasses solid baselines and attains SOTA results on multiple real-world datasets. Compared to the previous SOTA approach GeoFormer, SRMatcher increases the area under the cumulative curve (AUC) by about 11\% on HPatches. Additionally, the SRMatcher could serve as a plug-and-play framework for other matching methods like LoFTR, yielding substantial precision improvement.
Camera-aware Label Refinement for Unsupervised Person Re-identification
Mar 25, 2024



Unsupervised person re-identification aims to retrieve images of a specified person without identity labels. Many recent unsupervised Re-ID approaches adopt clustering-based methods to measure cross-camera feature similarity to roughly divide images into clusters. They ignore the feature distribution discrepancy induced by camera domain gap, resulting in the unavoidable performance degradation. Camera information is usually available, and the feature distribution in the single camera usually focuses more on the appearance of the individual and has less intra-identity variance. Inspired by the observation, we introduce a \textbf{C}amera-\textbf{A}ware \textbf{L}abel \textbf{R}efinement~(CALR) framework that reduces camera discrepancy by clustering intra-camera similarity. Specifically, we employ intra-camera training to obtain reliable local pseudo labels within each camera, and then refine global labels generated by inter-camera clustering and train the discriminative model using more reliable global pseudo labels in a self-paced manner. Meanwhile, we develop a camera-alignment module to align feature distributions under different cameras, which could help deal with the camera variance further. Extensive experiments validate the superiority of our proposed method over state-of-the-art approaches. The code is accessible at https://github.com/leeBooMla/CALR.
Pseudo Labels Refinement with Intra-camera Similarity for Unsupervised Person Re-identification
Apr 25, 2023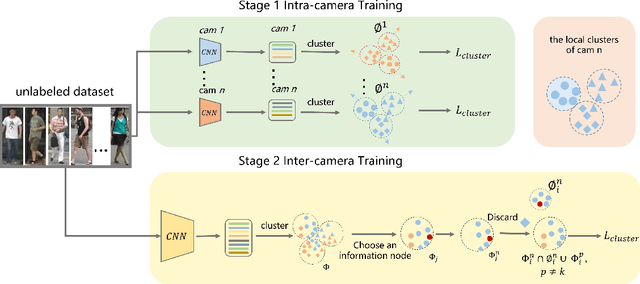
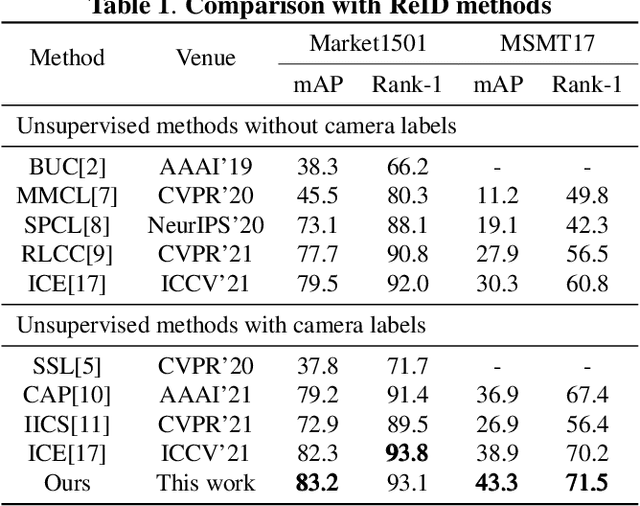
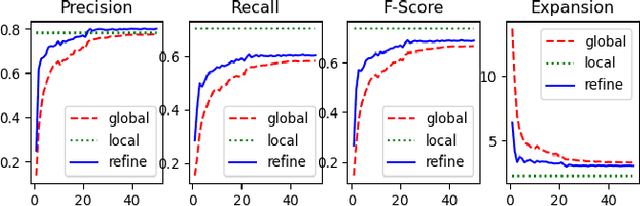
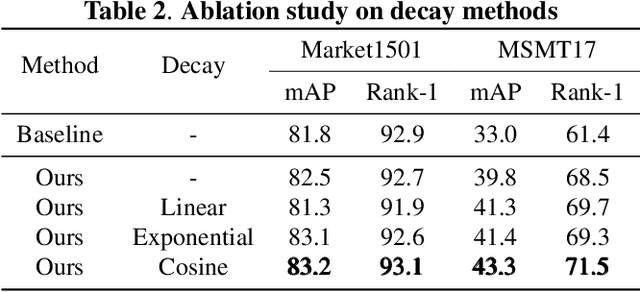
Unsupervised person re-identification (Re-ID) aims to retrieve person images across cameras without any identity labels. Most clustering-based methods roughly divide image features into clusters and neglect the feature distribution noise caused by domain shifts among different cameras, leading to inevitable performance degradation. To address this challenge, we propose a novel label refinement framework with clustering intra-camera similarity. Intra-camera feature distribution pays more attention to the appearance of pedestrians and labels are more reliable. We conduct intra-camera training to get local clusters in each camera, respectively, and refine inter-camera clusters with local results. We hence train the Re-ID model with refined reliable pseudo labels in a self-paced way. Extensive experiments demonstrate that the proposed method surpasses state-of-the-art performance.