 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Guided Prompting for Unified Remote Sensing Image Restoration
Apr 03, 2026Remote sensing image restoration (RSIR) is essential for recovering high-fidelity imagery from degraded observations, enabling accurate downstream analysis. However, most existing methods focus on single degradation types within homogeneous data, restricting their practicality in real-world scenarios where multiple degradations often across diverse spectral bands or sensor modalities, creating a significant operational bottleneck. To address this fundamental gap, we propose TGPNet, a unified framework capable of handling denoising, cloud removal, shadow removal, deblurring, and SAR despeckling within a single, unified architecture. The core of our framework is a novel Task-Guided Prompting (TGP) strategy. TGP leverages learnable, task-specific embeddings to generate degradation-aware cues, which then hierarchically modulate features throughout the decoder. This task-adaptive mechanism allows the network to precisely tailor its restoration process for distinct degradation patterns while maintaining a single set of shared weights. To validate our framework, we construct a unified RSIR benchmark covering RGB, multispectral, SAR, and thermal infrared modalities for five aforementioned restoration tasks. Experimental results demonstrate that TGPNet achieves state-of-the-art performance on both unified multi-task scenarios and unseen composite degradations, surpassing even specialized models in individual domains such as cloud removal. By successfully unifying heterogeneous degradation removal within a single adaptive framework, this work presents a significant advancement for multi-task RSIR, offering a practical and scalable solution for operational pipelines. The code and benchmark will be released at https://github.com/huangwenwenlili/TGPNet.
* 17 pages, 11 figures
Forest canopy height estimation from satellite RGB imagery using large-scale airborne LiDAR-derived training data and monocular depth estimation
Feb 09, 2026Large-scale, high-resolution forest canopy height mapping plays a crucial role in understanding regional and global carbon and water cycles. Spaceborne LiDAR missions, including the Ice, Cloud, and Land Elevation Satellite-2 (ICESat-2) and the Global Ecosystem Dynamics Investigation (GEDI), provide global observations of forest structure but are spatially sparse and subject to inherent uncertainties. In contrast, near-surface LiDAR platforms, such as airborne and unmanned aerial vehicle (UAV) LiDAR systems, offer much finer measurements of forest canopy structure, and a growing number of countries have made these datasets openly available. In this study, a state-of-the-art monocular depth estimation model, Depth Anything V2, was trained using approximately 16,000 km2 of canopy height models (CHMs) derived from publicly available airborne LiDAR point clouds and related products across multiple countries, together with 3 m resolution PlanetScope and airborne RGB imagery. The trained model, referred to as Depth2CHM, enables the estimation of spatially continuous CHMs directly from PlanetScope RGB imagery. Independent validation was conducted at sites in China (approximately 1 km2) and the United States (approximately 116 km2). The results showed that Depth2CHM could accurately estimate canopy height, with biases of 0.59 m and 0.41 m and root mean square errors (RMSEs) of 2.54 m and 5.75 m for these two sites, respectively. Compared with an existing global meter-resolution CHM product, the mean absolute error is reduced by approximately 1.5 m and the RMSE by approximately 2 m. These results demonstrated that monocular depth estimation networks trained with large-scale airborne LiDAR-derived canopy height data provide a promising and scalable pathway for high-resolution, spatially continuous forest canopy height estimation from satellite RGB imagery.
FreqGRL: Suppressing Low-Frequency Bias and Mining High-Frequency Knowledge for Cross-Domain Few-Shot Learning
Nov 10, 2025Cross-domain few-shot learning (CD-FSL) aims to recognize novel classes with only a few labeled examples under significant domain shifts. While recent approaches leverage a limited amount of labeled target-domain data to improve performance, the severe imbalance between abundant source data and scarce target data remains a critical challenge for effective representation learning. We present the first frequency-space perspective to analyze this issue and identify two key challenges: (1) models are easily biased toward source-specific knowledge encoded in the low-frequency components of source data, and (2) the sparsity of target data hinders the learning of high-frequency, domain-generalizable features. To address these challenges, we propose \textbf{FreqGRL}, a novel CD-FSL framework that mitigates the impact of data imbalance in the frequency space. Specifically, we introduce a Low-Frequency Replacement (LFR) module that substitutes the low-frequency components of source tasks with those from the target domain to create new source tasks that better align with target characteristics, thus reducing source-specific biases and promoting generalizable representation learning. We further design a High-Frequency Enhancement (HFE) module that filters out low-frequency components and performs learning directly on high-frequency features in the frequency space to improve cross-domain generalization. Additionally, a Global Frequency Filter (GFF) is incorporated to suppress noisy or irrelevant frequencies and emphasize informative ones, mitigating overfitting risks under limited target supervision. Extensive experiments on five standard CD-FSL benchmarks demonstrate that our frequency-guided framework achieves state-of-the-art performance.
Attentive Contextual Attention for Cloud Removal
Nov 20, 2024

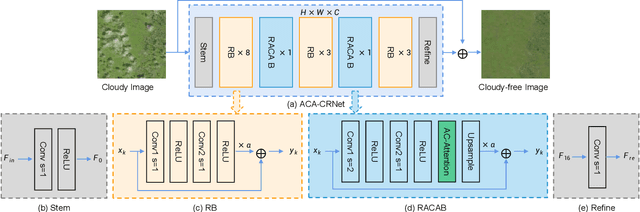

Cloud cover can significantly hinder the use of remote sensing images for Earth observation, prompting urgent advancements in cloud removal technology. Recently, deep learning strategies have shown strong potential in restoring cloud-obscured areas. These methods utilize convolution to extract intricate local features and attention mechanisms to gather long-range information, improving the overall comprehension of the scene. However, a common drawback of these approaches is that the resulting images often suffer from blurriness, artifacts, and inconsistencies. This is partly because attention mechanisms apply weights to all features based on generalized similarity scores, which can inadvertently introduce noise and irrelevant details from cloud-covered areas. To overcome this limitation and better capture relevant distant context, we introduce a novel approach named Attentive Contextual Attention (AC-Attention). This method enhances conventional attention mechanisms by dynamically learning data-driven attentive selection scores, enabling it to filter out noise and irrelevant features effectively. By integrating the AC-Attention module into the DSen2-CR cloud removal framework, we significantly improve the model's ability to capture essential distant information, leading to more effective cloud removal. Our extensive evaluation of various datasets shows that our method outperforms existing ones regarding image reconstruction quality. Additionally, we conducted ablation studies by integrating AC-Attention into multiple existing methods and widely used network architectures. These studies demonstrate the effectiveness and adaptability of AC-Attention and reveal its ability to focus on relevant features, thereby improving the overall performance of the networks. The code is available at \url{https://github.com/huangwenwenlili/ACA-CRNet}.
Camera-aware Label Refinement for Unsupervised Person Re-identification
Mar 25, 2024



Unsupervised person re-identification aims to retrieve images of a specified person without identity labels. Many recent unsupervised Re-ID approaches adopt clustering-based methods to measure cross-camera feature similarity to roughly divide images into clusters. They ignore the feature distribution discrepancy induced by camera domain gap, resulting in the unavoidable performance degradation. Camera information is usually available, and the feature distribution in the single camera usually focuses more on the appearance of the individual and has less intra-identity variance. Inspired by the observation, we introduce a \textbf{C}amera-\textbf{A}ware \textbf{L}abel \textbf{R}efinement~(CALR) framework that reduces camera discrepancy by clustering intra-camera similarity. Specifically, we employ intra-camera training to obtain reliable local pseudo labels within each camera, and then refine global labels generated by inter-camera clustering and train the discriminative model using more reliable global pseudo labels in a self-paced manner. Meanwhile, we develop a camera-alignment module to align feature distributions under different cameras, which could help deal with the camera variance further. Extensive experiments validate the superiority of our proposed method over state-of-the-art approaches. The code is accessible at https://github.com/leeBooMla/CALR.