 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATT-CR: Adaptive Triangular Transformer for Cloud Removal
Jun 04, 2026Cloud removal aims to accurately reconstruct the ground objects obscured by clouds in remote sensing images. Existing Transformer-based methods utilizing self-attention have shown impressive results by effectively modeling long-range dependencies in cloudy images. However, they suffer from the following issues: 1) the high computational complexity of self-attention limits scalability; 2) treating both cloudy and clean pixels as valid within the attention computation brings disturbances in subsequent layers, leading to suboptimal performance. To address these challenges, we propose the Adaptive Triangular Transformer for Cloud Removal (ATT-CR), a model that effectively reduces computational costs and mitigates interference from cloudy pixels. Specifically, it consists of two core components: Triangular Attention (TAN) and Feature Selected Gating Module (FSGM). TAN employs lower and upper triangular matrices to approximate Softmax attention with O(N) computational complexity, significantly reducing the computational costs. The FSGM, on the other hand, integrates with TAN to adaptively distinguish between cloudy and clean features, which minimizes the introduction of invalid information into subsequent layers. Extensive experiments on cloud removal benchmarks demonstrate that ATT-CR delivers superior performance compared to existing methods.
Gram-Anchored Prompt Learning for Vision-Language Models via Second-Order Statistics
Apr 05, 2026Parameter-efficient prompt learning has become the de facto standard for adapting Vision-Language Models (VLMs) to downstream tasks. Existing approaches predominantly focus on aligning text prompts with first-order visual features (i.e., spatial feature maps). While effective for fine-grained semantic discrimination, we argue that relying solely on first-order information is insufficient for robust adaptation, as these spatially entangled features are highly susceptible to domain shifts and local noise. In this work, we propose \textbf{Gram-Anchored Prompt Learning (GAPL)} for Vision-Language Models via Second-Order Statistics, a framework that synergizes local semantic alignment with global structural consistency. Methodologically, we introduce an additional second-order statistical stream via \textbf{Gram matrices} that augments the standard first-order spatial interaction. By anchoring prompts to these second-order priors, our approach enables language representations to dynamically adapt to statistical distribution shifts across diverse domains. Extensive experiments indicate the effectiveness of the second-order features, and show compelling performances of GAPL on various benchmarks.
Task-Guided Prompting for Unified Remote Sensing Image Restoration
Apr 03, 2026Remote sensing image restoration (RSIR) is essential for recovering high-fidelity imagery from degraded observations, enabling accurate downstream analysis. However, most existing methods focus on single degradation types within homogeneous data, restricting their practicality in real-world scenarios where multiple degradations often across diverse spectral bands or sensor modalities, creating a significant operational bottleneck. To address this fundamental gap, we propose TGPNet, a unified framework capable of handling denoising, cloud removal, shadow removal, deblurring, and SAR despeckling within a single, unified architecture. The core of our framework is a novel Task-Guided Prompting (TGP) strategy. TGP leverages learnable, task-specific embeddings to generate degradation-aware cues, which then hierarchically modulate features throughout the decoder. This task-adaptive mechanism allows the network to precisely tailor its restoration process for distinct degradation patterns while maintaining a single set of shared weights. To validate our framework, we construct a unified RSIR benchmark covering RGB, multispectral, SAR, and thermal infrared modalities for five aforementioned restoration tasks. Experimental results demonstrate that TGPNet achieves state-of-the-art performance on both unified multi-task scenarios and unseen composite degradations, surpassing even specialized models in individual domains such as cloud removal. By successfully unifying heterogeneous degradation removal within a single adaptive framework, this work presents a significant advancement for multi-task RSIR, offering a practical and scalable solution for operational pipelines. The code and benchmark will be released at https://github.com/huangwenwenlili/TGPNet.
* 17 pages, 11 figures
Attentive Contextual Attention for Cloud Removal
Nov 20, 2024

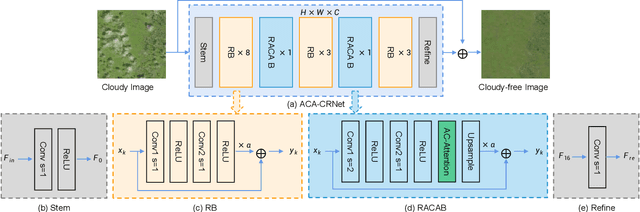

Cloud cover can significantly hinder the use of remote sensing images for Earth observation, prompting urgent advancements in cloud removal technology. Recently, deep learning strategies have shown strong potential in restoring cloud-obscured areas. These methods utilize convolution to extract intricate local features and attention mechanisms to gather long-range information, improving the overall comprehension of the scene. However, a common drawback of these approaches is that the resulting images often suffer from blurriness, artifacts, and inconsistencies. This is partly because attention mechanisms apply weights to all features based on generalized similarity scores, which can inadvertently introduce noise and irrelevant details from cloud-covered areas. To overcome this limitation and better capture relevant distant context, we introduce a novel approach named Attentive Contextual Attention (AC-Attention). This method enhances conventional attention mechanisms by dynamically learning data-driven attentive selection scores, enabling it to filter out noise and irrelevant features effectively. By integrating the AC-Attention module into the DSen2-CR cloud removal framework, we significantly improve the model's ability to capture essential distant information, leading to more effective cloud removal. Our extensive evaluation of various datasets shows that our method outperforms existing ones regarding image reconstruction quality. Additionally, we conducted ablation studies by integrating AC-Attention into multiple existing methods and widely used network architectures. These studies demonstrate the effectiveness and adaptability of AC-Attention and reveal its ability to focus on relevant features, thereby improving the overall performance of the networks. The code is available at \url{https://github.com/huangwenwenlili/ACA-CRNet}.
T-former: An Efficient Transformer for Image Inpainting
May 19, 2023
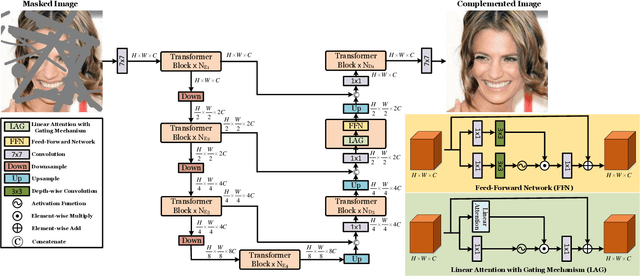


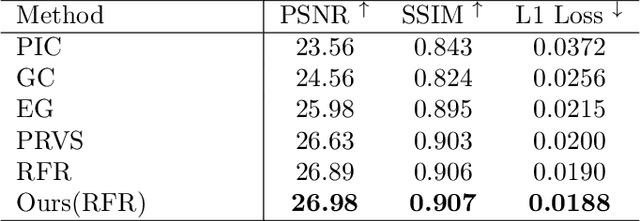
Benefiting from powerful convolutional neural networks (CNNs), learning-based image inpainting methods have made significant breakthroughs over the years. However, some nature of CNNs (e.g. local prior, spatially shared parameters) limit the performance in the face of broken images with diverse and complex forms. Recently, a class of attention-based network architectures, called transformer, has shown significant performance on natural language processing fields and high-level vision tasks. Compared with CNNs, attention operators are better at long-range modeling and have dynamic weights, but their computational complexity is quadratic in spatial resolution, and thus less suitable for applications involving higher resolution images, such as image inpainting. In this paper, we design a novel attention linearly related to the resolution according to Taylor expansion. And based on this attention, a network called $T$-former is designed for image inpainting. Experiments on several benchmark datasets demonstrate that our proposed method achieves state-of-the-art accuracy while maintaining a relatively low number of parameters and computational complexity. The code can be found at \href{https://github.com/dengyecode/T-former_image_inpainting}{github.com/dengyecode/T-former\_image\_inpainting}
Auxiliary Loss Adaptation for Image Inpainting
Nov 22, 2021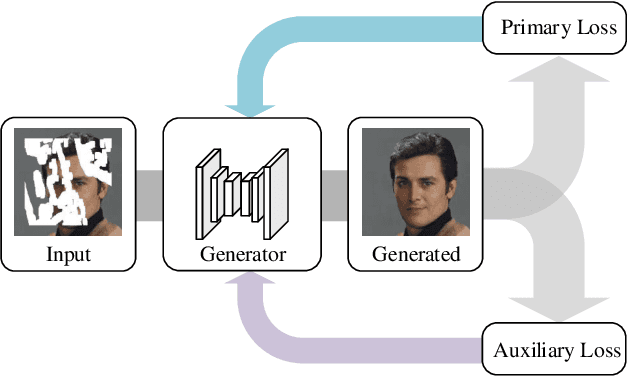
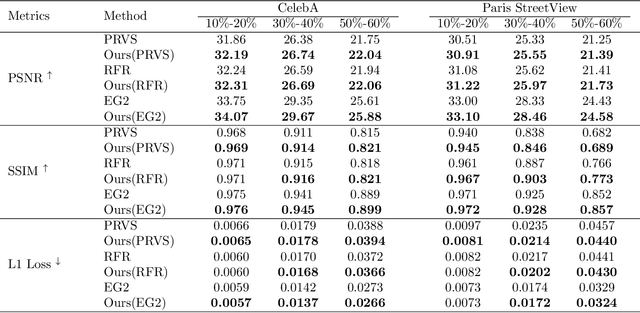
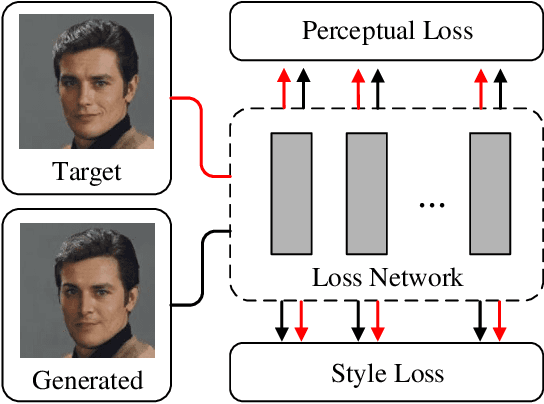
Auxiliary losses commonly used in image inpainting lead to better reconstruction performance by incorporating prior knowledge of missing regions. However, it usually requires a lot of effort to fully exploit the potential of auxiliary losses, or otherwise, improperly weighted auxiliary losses would distract the model from the inpainting task, and the effectiveness of an auxiliary loss might vary during the training process. Hence the design of auxiliary losses takes strong domain expertise. To mitigate the problem, in this work, we introduce the Auxiliary Loss Adaptation for Image Inpainting (ALA) algorithm to dynamically adjust the parameters of the auxiliary loss. Our method is based on the principle that the best auxiliary loss is the one that helps increase the performance of the main loss most through several steps of gradient descent. We then examined two commonly used auxiliary losses in inpainting and used ALA to adapt their parameters. Experimental results show that ALA induces more competitive inpainting results than fixed auxiliary losses. In particular, simply combining auxiliary loss with ALA, existing inpainting methods can achieve increased performances without explicitly incorporating delicate network design or structure knowledge prior.
Distributed Generative Adversarial Net
Nov 19, 2019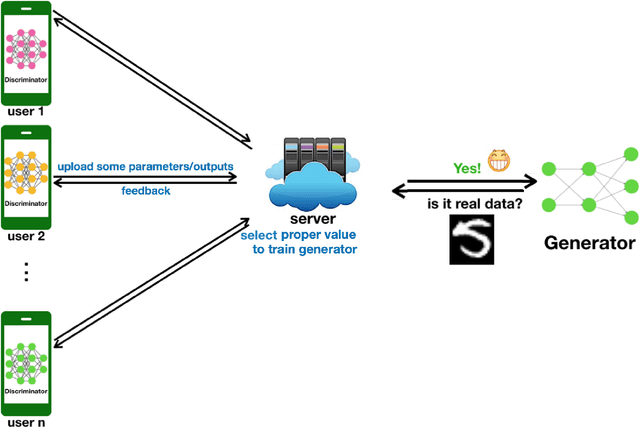



Recently the Generative Adversarial Network has become a hot topic. Considering the application of GAN in multi-user environment, we propose Distributed-GAN. It enables multiple users to train with their own data locally and generates more diverse samples. Users don't need to share data with each other to avoid the leakage of privacy. In recent years, commercial companies have launched cloud platforms based on artificial intelligence to provide model for users who lack computing power. We hope our work can inspire these companies to provide more powerful AI services.