 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartArena: Benchmarking Chart Parsing across Languages, Scenarios, and Formats
May 31, 2026Charts are a primary medium for conveying quantitative and relational information, yet systematically evaluating chart parsing models remains difficult. Existing benchmarks focus on narrow chart types and leave diagrammatic structures such as flowcharts and mind maps largely unaddressed, while models produce outputs in incompatible formats, and datasets rarely include the printed or hand-drawn images encountered in practice. To address these issues, we introduce ChartArena, a comprehensive bilingual benchmark covering eight chart families spanning both numeric charts and diagrammatic structures, each evaluated across three visual scenarios: digital renderings, printed photos, and hand-drawn photos. The dataset is built via a human-agent collaborative annotation pipeline with multi-stage human verification to ensure annotation reliability. To enable fair cross-model comparison, we further design a format-agnostic evaluation protocol that maps heterogeneous outputs into two canonical semantic spaces, a normalized triple view and a directed graph view, and scores them with structure-aware metrics. Through extensive evaluation of 26 leading MLLMs, we observe three consistent findings: (i) frontier proprietary models such as Gemini 3.1 Pro lead overall, yet the strongest open-source systems are rapidly closing the gap; (ii) document parsing models handle numeric charts reasonably but fall sharply behind on diagrammatic structures; and (iii) expert chart parsers remain limited to narrow chart families. Across all models, radar charts and hand-drawn scenarios stay especially challenging. These findings show that ChartArena exposes clear capability gaps and provides a unified foundation for future progress. ChartArena is publicly available at https://github.com/pspdada/ChartArena.
Chronicles-OCR: A Cross-Temporal Perception Benchmark for the Evolutionary Trajectory of Chinese Characters
May 12, 2026Vision Large Language Models (VLLMs) have achieved remarkable success in modern text-rich visual understanding. However, their perceptual robustness in the face of the continuous morphological evolution of historical writing systems remains largely unexplored. Existing ancient text datasets typically focus on isolated historical periods, failing to capture the systematic visual distribution shifts spanning thousands of years. To bridge this gap and empower Digital Humanities, we introduce Chronicles-OCR, the first comprehensive benchmark specifically designed to evaluate the cross-temporal visual perception capabilities of VLLMs across the complete evolutionary trajectory of Chinese characters, known as the Seven Chinese Scripts. Curated in collaboration with top-tier institutional domain experts, the dataset comprises 2,800 strictly balanced images encompassing highly diverse physical media, ranging from tortoise shells to paper-based calligraphy. To accommodate the drastic morphological and topological variations across different historical stages, we propose a novel Stage-Adaptive Annotation Paradigm. Based on this, Chronicles-OCR formulates four rigorous quantitative tasks: cross-period character spotting, fine-grained archaic character recognition via visual referring, ancient text parsing, and script classification. By isolating visual perception from semantic reasoning, Chronicles-OCR provides an authoritative platform to expose the limitations of current VLLMs, paving the way for robust, evolution-aware historical text perception. Chronicles-OCR is publicly available at https://github.com/VirtualLUOUCAS/Chronicles-OCR.
Towards Real-World Document Parsing via Realistic Scene Synthesis and Document-Aware Training
Mar 25, 2026Document parsing has recently advanced with multimodal large language models (MLLMs) that directly map document images to structured outputs. Traditional cascaded pipelines depend on precise layout analysis and often fail under casually captured or non-standard conditions. Although end-to-end approaches mitigate this dependency, they still exhibit repetitive, hallucinated, and structurally inconsistent predictions - primarily due to the scarcity of large-scale, high-quality full-page (document-level) end-to-end parsing data and the lack of structure-aware training strategies. To address these challenges, we propose a data-training co-design framework for robust end-to-end document parsing. A Realistic Scene Synthesis strategy constructs large-scale, structurally diverse full-page end-to-end supervision by composing layout templates with rich document elements, while a Document-Aware Training Recipe introduces progressive learning and structure-token optimization to enhance structural fidelity and decoding stability. We further build Wild-OmniDocBench, a benchmark derived from real-world captured documents for robustness evaluation. Integrated into a 1B-parameter MLLM, our method achieves superior accuracy and robustness across both scanned/digital and real-world captured scenarios. All models, data synthesis pipelines, and benchmarks will be publicly released to advance future research in document understanding.
MMTIT-Bench: A Multilingual and Multi-Scenario Benchmark with Cognition-Perception-Reasoning Guided Text-Image Machine Translation
Mar 25, 2026End-to-end text-image machine translation (TIMT), which directly translates textual content in images across languages, is crucial for real-world multilingual scene understanding. Despite advances in vision-language large models (VLLMs), robustness across diverse visual scenes and low-resource languages remains underexplored due to limited evaluation resources. We present MMTIT-Bench, a human-verified multilingual and multi-scenario benchmark with 1,400 images spanning fourteen non-English and non-Chinese languages and diverse settings such as documents, scenes, and web images, enabling rigorous assessment of end-to-end TIMT. Beyond benchmarking, we study how reasoning-oriented data design improves translation. Although recent VLLMs have begun to incorporate long Chain-of-Thought (CoT) reasoning, effective thinking paradigms for TIMT are still immature: existing designs either cascade parsing and translation in a sequential manner or focus on language-only reasoning, overlooking the visual cognition central to VLLMs. We propose Cognition-Perception-Reasoning for Translation (CPR-Trans), a data paradigm that integrates scene cognition, text perception, and translation reasoning within a unified reasoning process. Using a VLLM-driven data generation pipeline, CPR-Trans provides structured, interpretable supervision that aligns perception with reasoning. Experiments on 3B and 7B models show consistent gains in accuracy and interpretability. We will release MMTIT-Bench to promote the multilingual and multi-scenario TIMT research upon acceptance.
StrucTexTv3: An Efficient Vision-Language Model for Text-rich Image Perception, Comprehension, and Beyond
Jun 04, 2024



Text-rich images have significant and extensive value, deeply integrated into various aspects of human life. Notably, both visual cues and linguistic symbols in text-rich images play crucial roles in information transmission but are accompanied by diverse challenges. Therefore, the efficient and effective understanding of text-rich images is a crucial litmus test for the capability of Vision-Language Models. We have crafted an efficient vision-language model, StrucTexTv3, tailored to tackle various intelligent tasks for text-rich images. The significant design of StrucTexTv3 is presented in the following aspects: Firstly, we adopt a combination of an effective multi-scale reduced visual transformer and a multi-granularity token sampler (MG-Sampler) as a visual token generator, successfully solving the challenges of high-resolution input and complex representation learning for text-rich images. Secondly, we enhance the perception and comprehension abilities of StrucTexTv3 through instruction learning, seamlessly integrating various text-oriented tasks into a unified framework. Thirdly, we have curated a comprehensive collection of high-quality text-rich images, abbreviated as TIM-30M, encompassing diverse scenarios like incidental scenes, office documents, web pages, and screenshots, thereby improving the robustness of our model. Our method achieved SOTA results in text-rich image perception tasks, and significantly improved performance in comprehension tasks. Among multimodal models with LLM decoder of approximately 1.8B parameters, it stands out as a leader, which also makes the deployment of edge devices feasible. In summary, the StrucTexTv3 model, featuring efficient structural design, outstanding performance, and broad adaptability, offers robust support for diverse intelligent application tasks involving text-rich images, thus exhibiting immense potential for widespread application.
Towards Unified Multi-granularity Text Detection with Interactive Attention
May 30, 2024



Existing OCR engines or document image analysis systems typically rely on training separate models for text detection in varying scenarios and granularities, leading to significant computational complexity and resource demands. In this paper, we introduce "Detect Any Text" (DAT), an advanced paradigm that seamlessly unifies scene text detection, layout analysis, and document page detection into a cohesive, end-to-end model. This design enables DAT to efficiently manage text instances at different granularities, including *word*, *line*, *paragraph* and *page*. A pivotal innovation in DAT is the across-granularity interactive attention module, which significantly enhances the representation learning of text instances at varying granularities by correlating structural information across different text queries. As a result, it enables the model to achieve mutually beneficial detection performances across multiple text granularities. Additionally, a prompt-based segmentation module refines detection outcomes for texts of arbitrary curvature and complex layouts, thereby improving DAT's accuracy and expanding its real-world applicability. Experimental results demonstrate that DAT achieves state-of-the-art performances across a variety of text-related benchmarks, including multi-oriented/arbitrarily-shaped scene text detection, document layout analysis and page detection tasks.
Auxiliary Loss Adaptation for Image Inpainting
Nov 22, 2021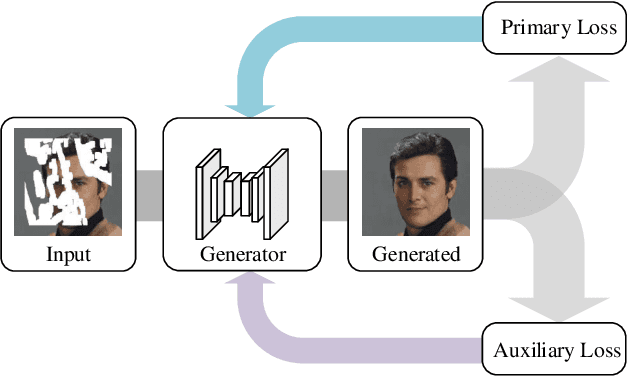
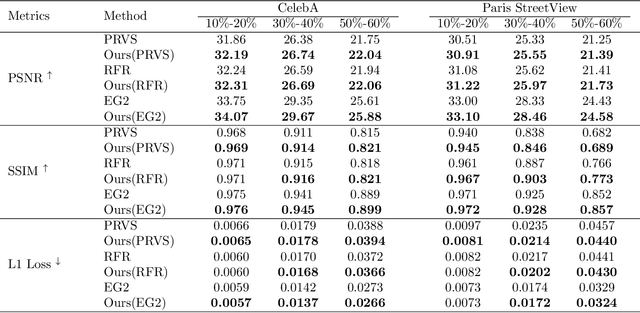
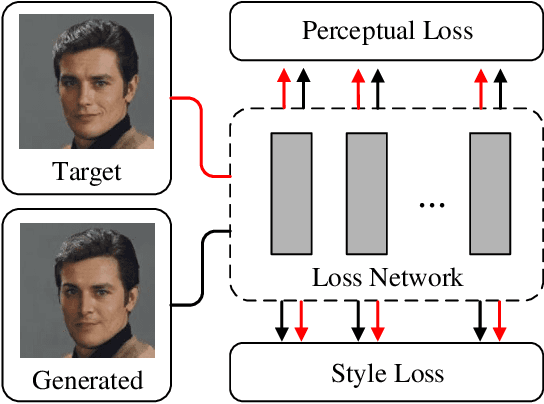
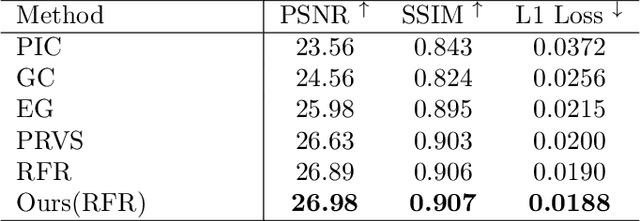
Auxiliary losses commonly used in image inpainting lead to better reconstruction performance by incorporating prior knowledge of missing regions. However, it usually requires a lot of effort to fully exploit the potential of auxiliary losses, or otherwise, improperly weighted auxiliary losses would distract the model from the inpainting task, and the effectiveness of an auxiliary loss might vary during the training process. Hence the design of auxiliary losses takes strong domain expertise. To mitigate the problem, in this work, we introduce the Auxiliary Loss Adaptation for Image Inpainting (ALA) algorithm to dynamically adjust the parameters of the auxiliary loss. Our method is based on the principle that the best auxiliary loss is the one that helps increase the performance of the main loss most through several steps of gradient descent. We then examined two commonly used auxiliary losses in inpainting and used ALA to adapt their parameters. Experimental results show that ALA induces more competitive inpainting results than fixed auxiliary losses. In particular, simply combining auxiliary loss with ALA, existing inpainting methods can achieve increased performances without explicitly incorporating delicate network design or structure knowledge prior.
Teacher-Student Asynchronous Learning with Multi-Source Consistency for Facial Landmark Detection
Dec 12, 2020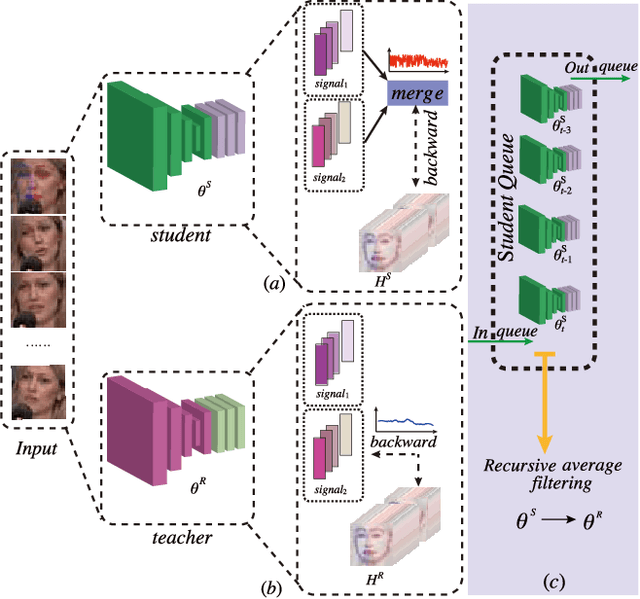

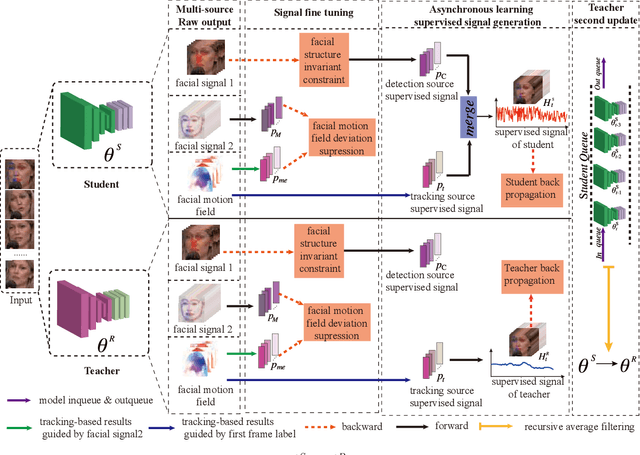

Due to the high annotation cost of large-scale facial landmark detection tasks in videos, a semi-supervised paradigm that uses self-training for mining high-quality pseudo-labels to participate in training has been proposed by researchers. However, self-training based methods often train with a gradually increasing number of samples, whose performances vary a lot depending on the number of pseudo-labeled samples added. In this paper, we propose a teacher-student asynchronous learning~(TSAL) framework based on the multi-source supervision signal consistency criterion, which implicitly mines pseudo-labels through consistency constraints. Specifically, the TSAL framework contains two models with exactly the same structure. The radical student uses multi-source supervision signals from the same task to update parameters, while the calm teacher uses a single-source supervision signal to update parameters. In order to reasonably absorb student's suggestions, teacher's parameters are updated again through recursive average filtering. The experimental results prove that asynchronous-learning framework can effectively filter noise in multi-source supervision signals, thereby mining the pseudo-labels which are more significant for network parameter updating. And extensive experiments on 300W, AFLW, and 300VW benchmarks show that the TSAL framework achieves state-of-the-art performance.
End-to-End Multi-Object Tracking with Global Response Map
Jul 13, 2020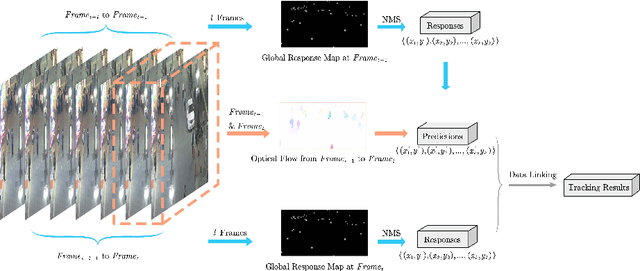

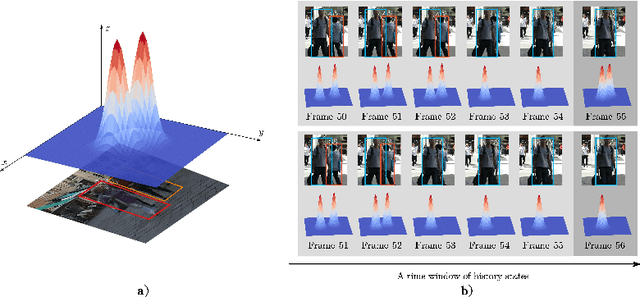
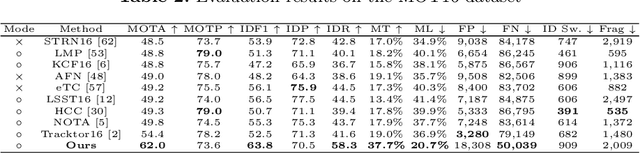
Most existing Multi-Object Tracking (MOT) approaches follow the Tracking-by-Detection paradigm and the data association framework where objects are firstly detected and then associated. Although deep-learning based method can noticeably improve the object detection performance and also provide good appearance features for cross-frame association, the framework is not completely end-to-end, and therefore the computation is huge while the performance is limited. To address the problem, we present a completely end-to-end approach that takes image-sequence/video as input and outputs directly the located and tracked objects of learned types. Specifically, with our introduced multi-object representation strategy, a global response map can be accurately generated over frames, from which the trajectory of each tracked object can be easily picked up, just like how a detector inputs an image and outputs the bounding boxes of each detected object. The proposed model is fast and accurate. Experimental results based on the MOT16 and MOT17 benchmarks show that our proposed on-line tracker achieved state-of-the-art performance on several tracking metrics.