 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Multi-Object Tracking with Global Response Map
Paper and Code
Jul 13, 2020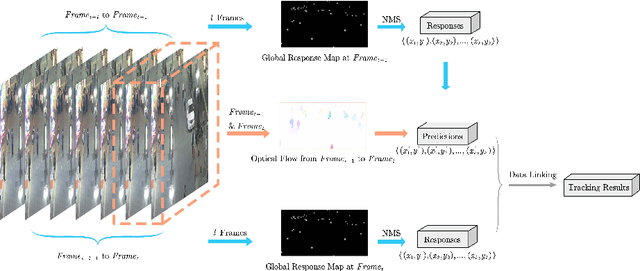

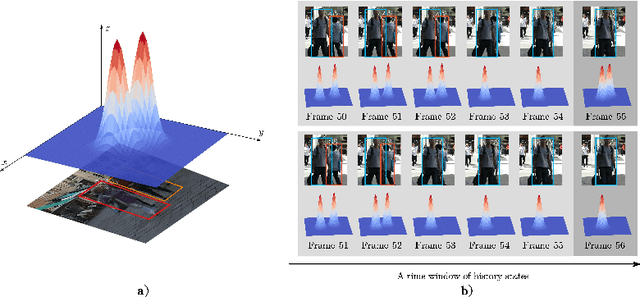
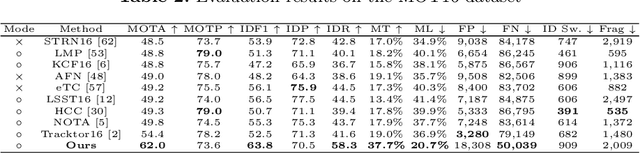
Most existing Multi-Object Tracking (MOT) approaches follow the Tracking-by-Detection paradigm and the data association framework where objects are firstly detected and then associated. Although deep-learning based method can noticeably improve the object detection performance and also provide good appearance features for cross-frame association, the framework is not completely end-to-end, and therefore the computation is huge while the performance is limited. To address the problem, we present a completely end-to-end approach that takes image-sequence/video as input and outputs directly the located and tracked objects of learned types. Specifically, with our introduced multi-object representation strategy, a global response map can be accurately generated over frames, from which the trajectory of each tracked object can be easily picked up, just like how a detector inputs an image and outputs the bounding boxes of each detected object. The proposed model is fast and accurate. Experimental results based on the MOT16 and MOT17 benchmarks show that our proposed on-line tracker achieved state-of-the-art performance on several tracking metrics.