 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLayDiff: A Unified Diffusion Transformer for Content-Aware Layout Generation
Dec 09, 2025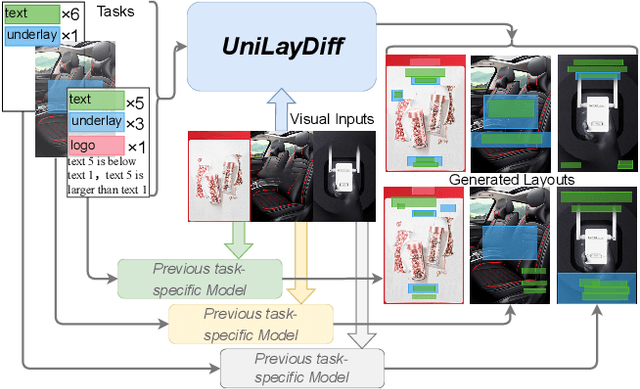
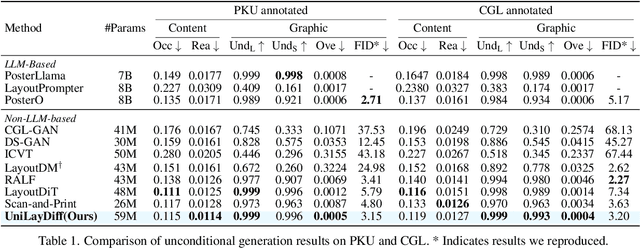
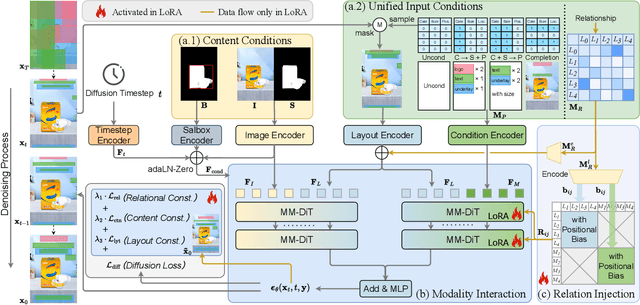
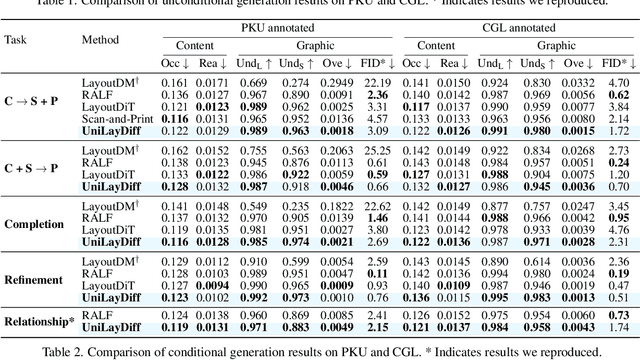
Content-aware layout generation is a critical task in graphic design automation, focused on creating visually appealing arrangements of elements that seamlessly blend with a given background image. The variety of real-world applications makes it highly challenging to develop a single model capable of unifying the diverse range of input-constrained generation sub-tasks, such as those conditioned by element types, sizes, or their relationships. Current methods either address only a subset of these tasks or necessitate separate model parameters for different conditions, failing to offer a truly unified solution. In this paper, we propose UniLayDiff: a Unified Diffusion Transformer, that for the first time, addresses various content-aware layout generation tasks with a single, end-to-end trainable model. Specifically, we treat layout constraints as a distinct modality and employ Multi-Modal Diffusion Transformer framework to capture the complex interplay between the background image, layout elements, and diverse constraints. Moreover, we integrate relation constraints through fine-tuning the model with LoRA after pretraining the model on other tasks. Such a schema not only achieves unified conditional generation but also enhances overall layout quality. Extensive experiments demonstrate that UniLayDiff achieves state-of-the-art performance across from unconditional to various conditional generation tasks and, to the best of our knowledge, is the first model to unify the full range of content-aware layout generation tasks.
FreqGRL: Suppressing Low-Frequency Bias and Mining High-Frequency Knowledge for Cross-Domain Few-Shot Learning
Nov 10, 2025Cross-domain few-shot learning (CD-FSL) aims to recognize novel classes with only a few labeled examples under significant domain shifts. While recent approaches leverage a limited amount of labeled target-domain data to improve performance, the severe imbalance between abundant source data and scarce target data remains a critical challenge for effective representation learning. We present the first frequency-space perspective to analyze this issue and identify two key challenges: (1) models are easily biased toward source-specific knowledge encoded in the low-frequency components of source data, and (2) the sparsity of target data hinders the learning of high-frequency, domain-generalizable features. To address these challenges, we propose \textbf{FreqGRL}, a novel CD-FSL framework that mitigates the impact of data imbalance in the frequency space. Specifically, we introduce a Low-Frequency Replacement (LFR) module that substitutes the low-frequency components of source tasks with those from the target domain to create new source tasks that better align with target characteristics, thus reducing source-specific biases and promoting generalizable representation learning. We further design a High-Frequency Enhancement (HFE) module that filters out low-frequency components and performs learning directly on high-frequency features in the frequency space to improve cross-domain generalization. Additionally, a Global Frequency Filter (GFF) is incorporated to suppress noisy or irrelevant frequencies and emphasize informative ones, mitigating overfitting risks under limited target supervision. Extensive experiments on five standard CD-FSL benchmarks demonstrate that our frequency-guided framework achieves state-of-the-art performance.
DAMap: Distance-aware MapNet for High Quality HD Map Construction
Oct 26, 2025Predicting High-definition (HD) map elements with high quality (high classification and localization scores) is crucial to the safety of autonomous driving vehicles. However, current methods perform poorly in high quality predictions due to inherent task misalignment. Two main factors are responsible for misalignment: 1) inappropriate task labels due to one-to-many matching queries sharing the same labels, and 2) sub-optimal task features due to task-shared sampling mechanism. In this paper, we reveal two inherent defects in current methods and develop a novel HD map construction method named DAMap to address these problems. Specifically, DAMap consists of three components: Distance-aware Focal Loss (DAFL), Hybrid Loss Scheme (HLS), and Task Modulated Deformable Attention (TMDA). The DAFL is introduced to assign appropriate classification labels for one-to-many matching samples. The TMDA is proposed to obtain discriminative task-specific features. Furthermore, the HLS is proposed to better utilize the advantages of the DAFL. We perform extensive experiments and consistently achieve performance improvement on the NuScenes and Argoverse2 benchmarks under different metrics, baselines, splits, backbones, and schedules. Code will be available at https://github.com/jpdong-xjtu/DAMap.
SAMPO:Scale-wise Autoregression with Motion PrOmpt for generative world models
Sep 19, 2025World models allow agents to simulate the consequences of actions in imagined environments for planning, control, and long-horizon decision-making. However, existing autoregressive world models struggle with visually coherent predictions due to disrupted spatial structure, inefficient decoding, and inadequate motion modeling. In response, we propose \textbf{S}cale-wise \textbf{A}utoregression with \textbf{M}otion \textbf{P}r\textbf{O}mpt (\textbf{SAMPO}), a hybrid framework that combines visual autoregressive modeling for intra-frame generation with causal modeling for next-frame generation. Specifically, SAMPO integrates temporal causal decoding with bidirectional spatial attention, which preserves spatial locality and supports parallel decoding within each scale. This design significantly enhances both temporal consistency and rollout efficiency. To further improve dynamic scene understanding, we devise an asymmetric multi-scale tokenizer that preserves spatial details in observed frames and extracts compact dynamic representations for future frames, optimizing both memory usage and model performance. Additionally, we introduce a trajectory-aware motion prompt module that injects spatiotemporal cues about object and robot trajectories, focusing attention on dynamic regions and improving temporal consistency and physical realism. Extensive experiments show that SAMPO achieves competitive performance in action-conditioned video prediction and model-based control, improving generation quality with 4.4$\times$ faster inference. We also evaluate SAMPO's zero-shot generalization and scaling behavior, demonstrating its ability to generalize to unseen tasks and benefit from larger model sizes.
Time-Unified Diffusion Policy with Action Discrimination for Robotic Manipulation
Jun 11, 2025In many complex scenarios, robotic manipulation relies on generative models to estimate the distribution of multiple successful actions. As the diffusion model has better training robustness than other generative models, it performs well in imitation learning through successful robot demonstrations. However, the diffusion-based policy methods typically require significant time to iteratively denoise robot actions, which hinders real-time responses in robotic manipulation. Moreover, existing diffusion policies model a time-varying action denoising process, whose temporal complexity increases the difficulty of model training and leads to suboptimal action accuracy. To generate robot actions efficiently and accurately, we present the Time-Unified Diffusion Policy (TUDP), which utilizes action recognition capabilities to build a time-unified denoising process. On the one hand, we build a time-unified velocity field in action space with additional action discrimination information. By unifying all timesteps of action denoising, our velocity field reduces the difficulty of policy learning and speeds up action generation. On the other hand, we propose an action-wise training method, which introduces an action discrimination branch to supply additional action discrimination information. Through action-wise training, the TUDP implicitly learns the ability to discern successful actions to better denoising accuracy. Our method achieves state-of-the-art performance on RLBench with the highest success rate of 82.6% on a multi-view setup and 83.8% on a single-view setup. In particular, when using fewer denoising iterations, TUDP achieves a more significant improvement in success rate. Additionally, TUDP can produce accurate actions for a wide range of real-world tasks.
RSRNav: Reasoning Spatial Relationship for Image-Goal Navigation
Apr 25, 2025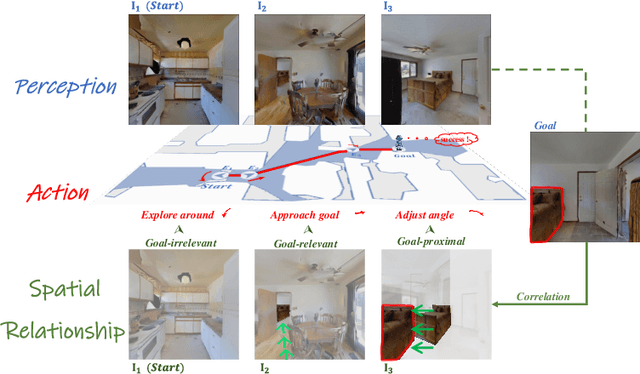
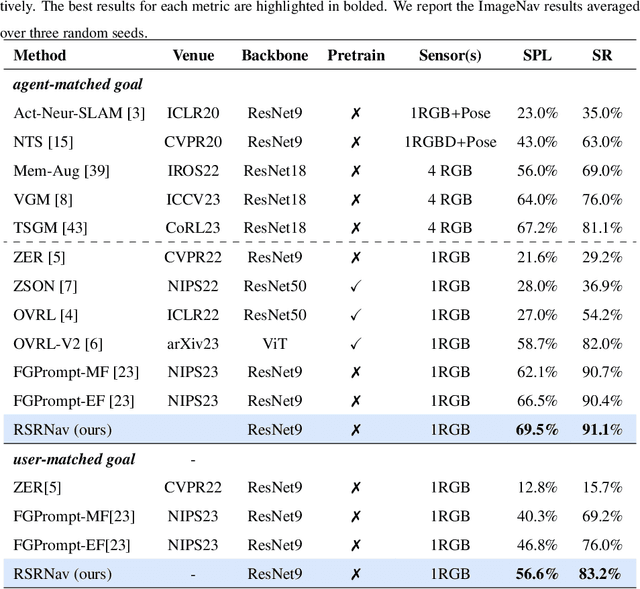
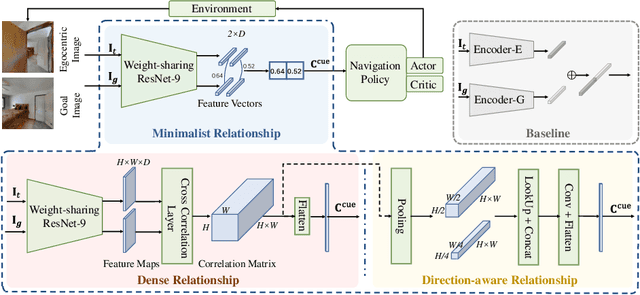
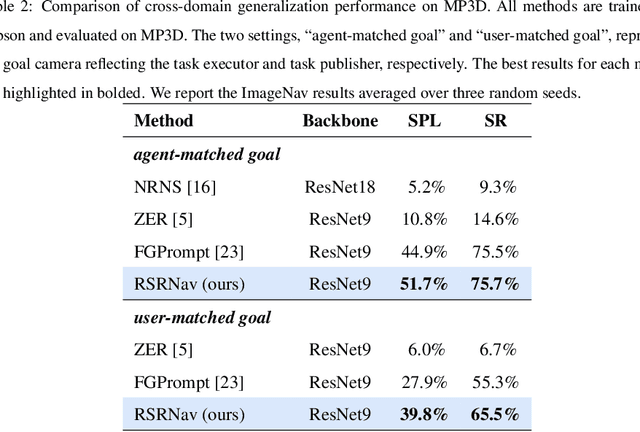
Recent image-goal navigation (ImageNav) methods learn a perception-action policy by separately capturing semantic features of the goal and egocentric images, then passing them to a policy network. However, challenges remain: (1) Semantic features often fail to provide accurate directional information, leading to superfluous actions, and (2) performance drops significantly when viewpoint inconsistencies arise between training and application. To address these challenges, we propose RSRNav, a simple yet effective method that reasons spatial relationships between the goal and current observations as navigation guidance. Specifically, we model the spatial relationship by constructing correlations between the goal and current observations, which are then passed to the policy network for action prediction. These correlations are progressively refined using fine-grained cross-correlation and direction-aware correlation for more precise navigation. Extensive evaluation of RSRNav on three benchmark datasets demonstrates superior navigation performance, particularly in the "user-matched goal" setting, highlighting its potential for real-world applications.
From Mapping to Composing: A Two-Stage Framework for Zero-shot Composed Image Retrieval
Apr 25, 2025Composed Image Retrieval (CIR) is a challenging multimodal task that retrieves a target image based on a reference image and accompanying modification text. Due to the high cost of annotating CIR triplet datasets, zero-shot (ZS) CIR has gained traction as a promising alternative. Existing studies mainly focus on projection-based methods, which map an image to a single pseudo-word token. However, these methods face three critical challenges: (1) insufficient pseudo-word token representation capacity, (2) discrepancies between training and inference phases, and (3) reliance on large-scale synthetic data. To address these issues, we propose a two-stage framework where the training is accomplished from mapping to composing. In the first stage, we enhance image-to-pseudo-word token learning by introducing a visual semantic injection module and a soft text alignment objective, enabling the token to capture richer and fine-grained image information. In the second stage, we optimize the text encoder using a small amount of synthetic triplet data, enabling it to effectively extract compositional semantics by combining pseudo-word tokens with modification text for accurate target image retrieval. The strong visual-to-pseudo mapping established in the first stage provides a solid foundation for the second stage, making our approach compatible with both high- and low-quality synthetic data, and capable of achieving significant performance gains with only a small amount of synthetic data. Extensive experiments were conducted on three public datasets, achieving superior performance compared to existing approaches.
Moment Quantization for Video Temporal Grounding
Apr 03, 2025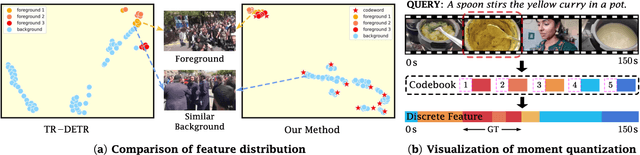
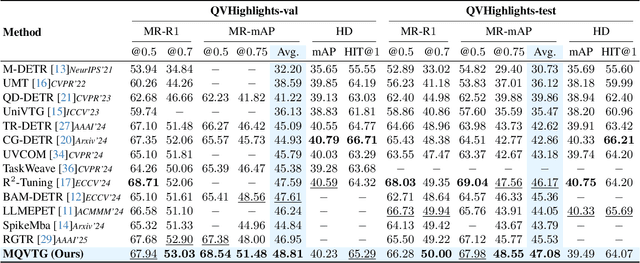
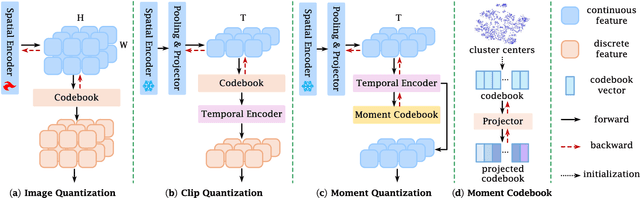
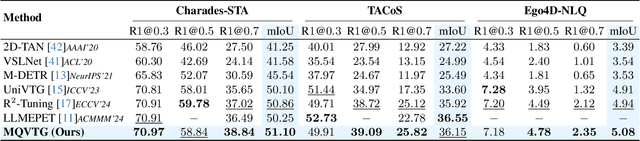
Video temporal grounding is a critical video understanding task, which aims to localize moments relevant to a language description. The challenge of this task lies in distinguishing relevant and irrelevant moments. Previous methods focused on learning continuous features exhibit weak differentiation between foreground and background features. In this paper, we propose a novel Moment-Quantization based Video Temporal Grounding method (MQVTG), which quantizes the input video into various discrete vectors to enhance the discrimination between relevant and irrelevant moments. Specifically, MQVTG maintains a learnable moment codebook, where each video moment matches a codeword. Considering the visual diversity, i.e., various visual expressions for the same moment, MQVTG treats moment-codeword matching as a clustering process without using discrete vectors, avoiding the loss of useful information from direct hard quantization. Additionally, we employ effective prior-initialization and joint-projection strategies to enhance the maintained moment codebook. With its simple implementation, the proposed method can be integrated into existing temporal grounding models as a plug-and-play component. Extensive experiments on six popular benchmarks demonstrate the effectiveness and generalizability of MQVTG, significantly outperforming state-of-the-art methods. Further qualitative analysis shows that our method effectively groups relevant features and separates irrelevant ones, aligning with our goal of enhancing discrimination.
StructVPR++: Distill Structural and Semantic Knowledge with Weighting Samples for Visual Place Recognition
Mar 09, 2025Visual place recognition is a challenging task for autonomous driving and robotics, which is usually considered as an image retrieval problem. A commonly used two-stage strategy involves global retrieval followed by re-ranking using patch-level descriptors. Most deep learning-based methods in an end-to-end manner cannot extract global features with sufficient semantic information from RGB images. In contrast, re-ranking can utilize more explicit structural and semantic information in one-to-one matching process, but it is time-consuming. To bridge the gap between global retrieval and re-ranking and achieve a good trade-off between accuracy and efficiency, we propose StructVPR++, a framework that embeds structural and semantic knowledge into RGB global representations via segmentation-guided distillation. Our key innovation lies in decoupling label-specific features from global descriptors, enabling explicit semantic alignment between image pairs without requiring segmentation during deployment. Furthermore, we introduce a sample-wise weighted distillation strategy that prioritizes reliable training pairs while suppressing noisy ones. Experiments on four benchmarks demonstrate that StructVPR++ surpasses state-of-the-art global methods by 5-23% in Recall@1 and even outperforms many two-stage approaches, achieving real-time efficiency with a single RGB input.
Referencing Where to Focus: Improving VisualGrounding with Referential Query
Dec 26, 2024



Visual Grounding aims to localize the referring object in an image given a natural language expression. Recent advancements in DETR-based visual grounding methods have attracted considerable attention, as they directly predict the coordinates of the target object without relying on additional efforts, such as pre-generated proposal candidates or pre-defined anchor boxes. However, existing research primarily focuses on designing stronger multi-modal decoder, which typically generates learnable queries by random initialization or by using linguistic embeddings. This vanilla query generation approach inevitably increases the learning difficulty for the model, as it does not involve any target-related information at the beginning of decoding. Furthermore, they only use the deepest image feature during the query learning process, overlooking the importance of features from other levels. To address these issues, we propose a novel approach, called RefFormer. It consists of the query adaption module that can be seamlessly integrated into CLIP and generate the referential query to provide the prior context for decoder, along with a task-specific decoder. By incorporating the referential query into the decoder, we can effectively mitigate the learning difficulty of the decoder, and accurately concentrate on the target object. Additionally, our proposed query adaption module can also act as an adapter, preserving the rich knowledge within CLIP without the need to tune the parameters of the backbone network. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method, outperforming state-of-the-art approaches on five visual grounding benchmarks.