 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Noisy Label Learning via Two-Stream Sample Distillation
Apr 16, 2024Noisy label learning aims to learn robust networks under the supervision of noisy labels, which plays a critical role in deep learning. Existing work either conducts sample selection or label correction to deal with noisy labels during the model training process. In this paper, we design a simple yet effective sample selection framework, termed Two-Stream Sample Distillation (TSSD), for noisy label learning, which can extract more high-quality samples with clean labels to improve the robustness of network training. Firstly, a novel Parallel Sample Division (PSD) module is designed to generate a certain training set with sufficient reliable positive and negative samples by jointly considering the sample structure in feature space and the human prior in loss space. Secondly, a novel Meta Sample Purification (MSP) module is further designed to mine adequate semi-hard samples from the remaining uncertain training set by learning a strong meta classifier with extra golden data. As a result, more and more high-quality samples will be distilled from the noisy training set to train networks robustly in every iteration. Extensive experiments on four benchmark datasets, including CIFAR-10, CIFAR-100, Tiny-ImageNet, and Clothing-1M, show that our method has achieved state-of-the-art results over its competitors.
Pairwise Similarity Distribution Clustering for Noisy Label Learning
Apr 02, 2024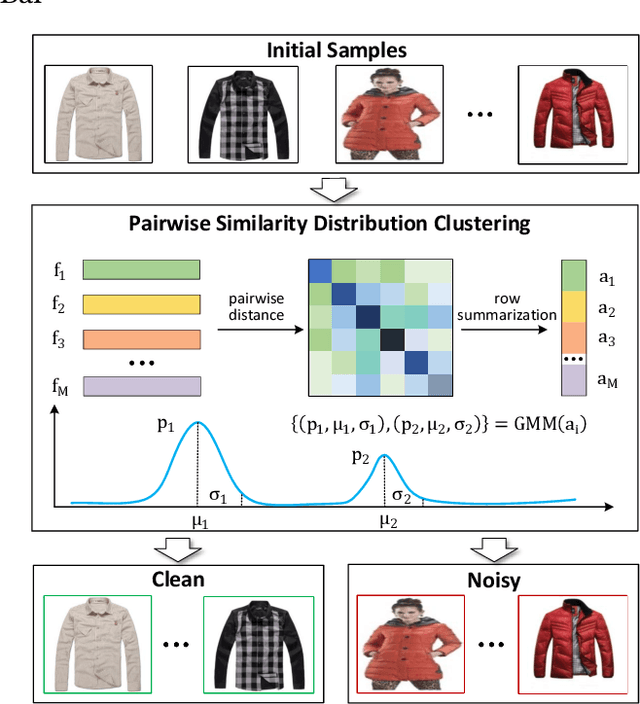
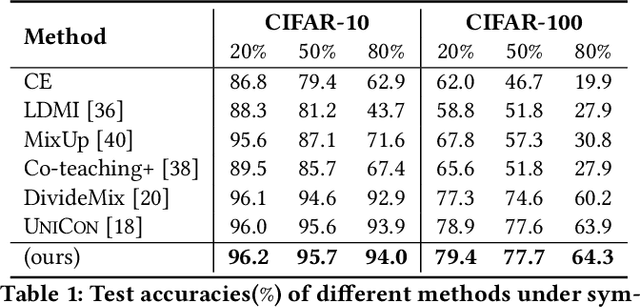
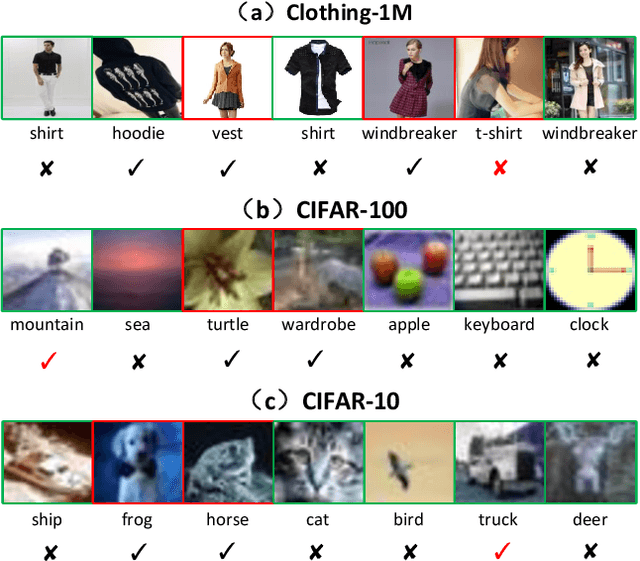
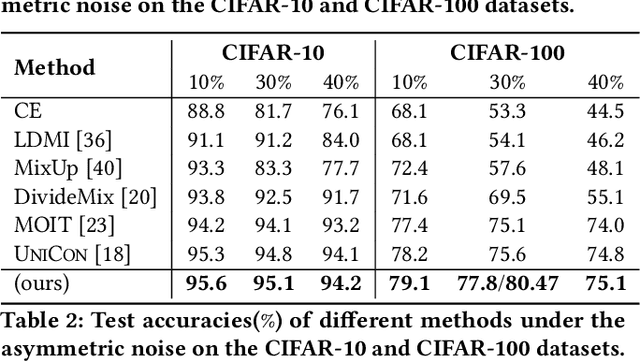
Noisy label learning aims to train deep neural networks using a large amount of samples with noisy labels, whose main challenge comes from how to deal with the inaccurate supervision caused by wrong labels. Existing works either take the label correction or sample selection paradigm to involve more samples with accurate labels into the training process. In this paper, we propose a simple yet effective sample selection algorithm, termed as Pairwise Similarity Distribution Clustering~(PSDC), to divide the training samples into one clean set and another noisy set, which can power any of the off-the-shelf semi-supervised learning regimes to further train networks for different downstream tasks. Specifically, we take the pairwise similarity between sample pairs to represent the sample structure, and the Gaussian Mixture Model~(GMM) to model the similarity distribution between sample pairs belonging to the same noisy cluster, therefore each sample can be confidently divided into the clean set or noisy set. Even under severe label noise rate, the resulting data partition mechanism has been proved to be more robust in judging the label confidence in both theory and practice. Experimental results on various benchmark datasets, such as CIFAR-10, CIFAR-100 and Clothing1M, demonstrate significant improvements over state-of-the-art methods.