 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalPaint: Spatiotemporal Coherent Video Outpainting with Global Feature Guidance
Jan 10, 2026Video outpainting extends a video beyond its original boundaries by synthesizing missing border content. Compared with image outpainting, it requires not only per-frame spatial plausibility but also long-range temporal coherence, especially when outpainted content becomes visible across time under camera or object motion. We propose GlobalPaint, a diffusion-based framework for spatiotemporal coherent video outpainting. Our approach adopts a hierarchical pipeline that first outpaints key frames and then completes intermediate frames via an interpolation model conditioned on the completed boundaries, reducing error accumulation in sequential processing. At the model level, we augment a pretrained image inpainting backbone with (i) an Enhanced Spatial-Temporal module featuring 3D windowed attention for stronger spatiotemporal interaction, and (ii) global feature guidance that distills OpenCLIP features from observed regions across all frames into compact global tokens using a dedicated extractor. Comprehensive evaluations on benchmark datasets demonstrate improved reconstruction quality and more natural motion compared to prior methods. Our demo page is https://yuemingpan.github.io/GlobalPaint/
UniHOI: Unified Human-Object Interaction Understanding via Unified Token Space
Nov 19, 2025In the field of human-object interaction (HOI), detection and generation are two dual tasks that have traditionally been addressed separately, hindering the development of comprehensive interaction understanding. To address this, we propose UniHOI, which jointly models HOI detection and generation via a unified token space, thereby effectively promoting knowledge sharing and enhancing generalization. Specifically, we introduce a symmetric interaction-aware attention module and a unified semi-supervised learning paradigm, enabling effective bidirectional mapping between images and interaction semantics even under limited annotations. Extensive experiments demonstrate that UniHOI achieves state-of-the-art performance in both HOI detection and generation. Specifically, UniHOI improves accuracy by 4.9% on long-tailed HOI detection and boosts interaction metrics by 42.0% on open-vocabulary generation tasks.
DAMap: Distance-aware MapNet for High Quality HD Map Construction
Oct 26, 2025Predicting High-definition (HD) map elements with high quality (high classification and localization scores) is crucial to the safety of autonomous driving vehicles. However, current methods perform poorly in high quality predictions due to inherent task misalignment. Two main factors are responsible for misalignment: 1) inappropriate task labels due to one-to-many matching queries sharing the same labels, and 2) sub-optimal task features due to task-shared sampling mechanism. In this paper, we reveal two inherent defects in current methods and develop a novel HD map construction method named DAMap to address these problems. Specifically, DAMap consists of three components: Distance-aware Focal Loss (DAFL), Hybrid Loss Scheme (HLS), and Task Modulated Deformable Attention (TMDA). The DAFL is introduced to assign appropriate classification labels for one-to-many matching samples. The TMDA is proposed to obtain discriminative task-specific features. Furthermore, the HLS is proposed to better utilize the advantages of the DAFL. We perform extensive experiments and consistently achieve performance improvement on the NuScenes and Argoverse2 benchmarks under different metrics, baselines, splits, backbones, and schedules. Code will be available at https://github.com/jpdong-xjtu/DAMap.
ChangingGrounding: 3D Visual Grounding in Changing Scenes
Oct 16, 2025Real-world robots localize objects from natural-language instructions while scenes around them keep changing. Yet most of the existing 3D visual grounding (3DVG) method still assumes a reconstructed and up-to-date point cloud, an assumption that forces costly re-scans and hinders deployment. We argue that 3DVG should be formulated as an active, memory-driven problem, and we introduce ChangingGrounding, the first benchmark that explicitly measures how well an agent can exploit past observations, explore only where needed, and still deliver precise 3D boxes in changing scenes. To set a strong reference point, we also propose Mem-ChangingGrounder, a zero-shot method for this task that marries cross-modal retrieval with lightweight multi-view fusion: it identifies the object type implied by the query, retrieves relevant memories to guide actions, then explores the target efficiently in the scene, falls back when previous operations are invalid, performs multi-view scanning of the target, and projects the fused evidence from multi-view scans to get accurate object bounding boxes. We evaluate different baselines on ChangingGrounding, and our Mem-ChangingGrounder achieves the highest localization accuracy while greatly reducing exploration cost. We hope this benchmark and method catalyze a shift toward practical, memory-centric 3DVG research for real-world applications. Project page: https://hm123450.github.io/CGB/ .
MCGM: Multi-stage Clustered Global Modeling for Long-range Interactions in Molecules
Sep 26, 2025Geometric graph neural networks (GNNs) excel at capturing molecular geometry, yet their locality-biased message passing hampers the modeling of long-range interactions. Current solutions have fundamental limitations: extending cutoff radii causes computational costs to scale cubically with distance; physics-inspired kernels (e.g., Coulomb, dispersion) are often system-specific and lack generality; Fourier-space methods require careful tuning of multiple parameters (e.g., mesh size, k-space cutoff) with added computational overhead. We introduce Multi-stage Clustered Global Modeling (MCGM), a lightweight, plug-and-play module that endows geometric GNNs with hierarchical global context through efficient clustering operations. MCGM builds a multi-resolution hierarchy of atomic clusters, distills global information via dynamic hierarchical clustering, and propagates this context back through learned transformations, ultimately reinforcing atomic features via residual connections. Seamlessly integrated into four diverse backbone architectures, MCGM reduces OE62 energy prediction error by an average of 26.2%. On AQM, MCGM achieves state-of-the-art accuracy (17.0 meV for energy, 4.9 meV/{\AA} for forces) while using 20% fewer parameters than Neural P3M. Code will be made available upon acceptance.
LongReasonArena: A Long Reasoning Benchmark for Large Language Models
Aug 26, 2025Existing long-context benchmarks for Large Language Models (LLMs) focus on evaluating comprehension of long inputs, while overlooking the evaluation of long reasoning abilities. To address this gap, we introduce LongReasonArena, a benchmark specifically designed to assess the long reasoning capabilities of LLMs. Our tasks require models to solve problems by executing multi-step algorithms that reflect key aspects of long reasoning, such as retrieval and backtracking. By controlling the inputs, the required reasoning length can be arbitrarily scaled, reaching up to 1 million tokens of reasoning for the most challenging tasks. Extensive evaluation results demonstrate that LongReasonArena presents a significant challenge for both open-source and proprietary LLMs. For instance, Deepseek-R1 achieves only 7.5% accuracy on our task. Further analysis also reveals that the accuracy exhibits a linear decline with respect to the logarithm of the expected number of reasoning steps. Our code and data is available at https://github.com/LongReasonArena/LongReasonArena.
EVA: Mixture-of-Experts Semantic Variant Alignment for Compositional Zero-Shot Learning
Jun 26, 2025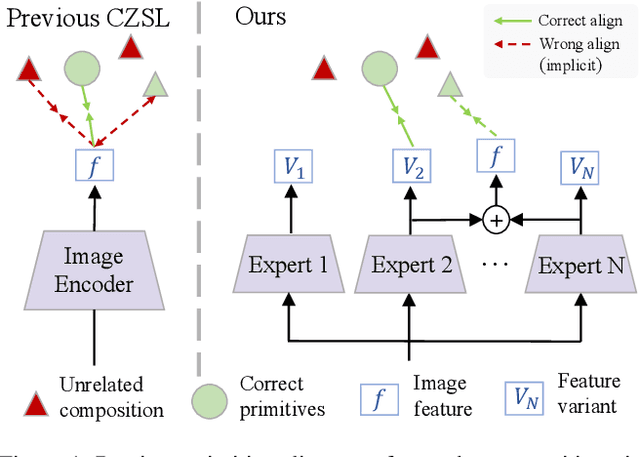
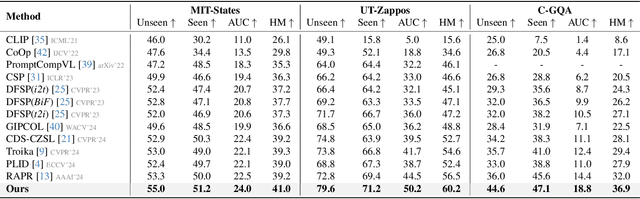
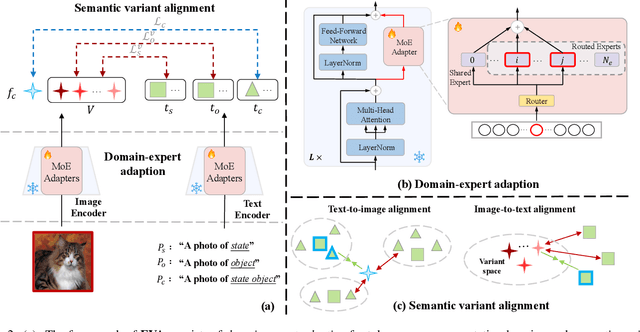
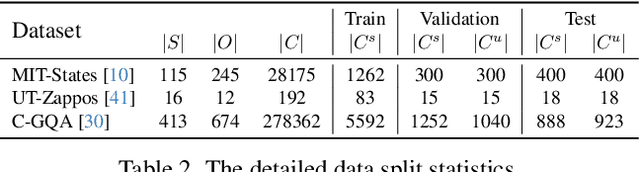
Compositional Zero-Shot Learning (CZSL) investigates compositional generalization capacity to recognize unknown state-object pairs based on learned primitive concepts. Existing CZSL methods typically derive primitives features through a simple composition-prototype mapping, which is suboptimal for a set of individuals that can be divided into distinct semantic subsets. Moreover, the all-to-one cross-modal primitives matching neglects compositional divergence within identical states or objects, limiting fine-grained image-composition alignment. In this study, we propose EVA, a Mixture-of-Experts Semantic Variant Alignment framework for CZSL. Specifically, we introduce domain-expert adaption, leveraging multiple experts to achieve token-aware learning and model high-quality primitive representations. To enable accurate compositional generalization, we further present semantic variant alignment to select semantically relevant representation for image-primitives matching. Our method significantly outperforms other state-of-the-art CZSL methods on three popular benchmarks in both closed- and open-world settings, demonstrating the efficacy of the proposed insight.
StructVPR++: Distill Structural and Semantic Knowledge with Weighting Samples for Visual Place Recognition
Mar 09, 2025Visual place recognition is a challenging task for autonomous driving and robotics, which is usually considered as an image retrieval problem. A commonly used two-stage strategy involves global retrieval followed by re-ranking using patch-level descriptors. Most deep learning-based methods in an end-to-end manner cannot extract global features with sufficient semantic information from RGB images. In contrast, re-ranking can utilize more explicit structural and semantic information in one-to-one matching process, but it is time-consuming. To bridge the gap between global retrieval and re-ranking and achieve a good trade-off between accuracy and efficiency, we propose StructVPR++, a framework that embeds structural and semantic knowledge into RGB global representations via segmentation-guided distillation. Our key innovation lies in decoupling label-specific features from global descriptors, enabling explicit semantic alignment between image pairs without requiring segmentation during deployment. Furthermore, we introduce a sample-wise weighted distillation strategy that prioritizes reliable training pairs while suppressing noisy ones. Experiments on four benchmarks demonstrate that StructVPR++ surpasses state-of-the-art global methods by 5-23% in Recall@1 and even outperforms many two-stage approaches, achieving real-time efficiency with a single RGB input.
ForestLPR: LiDAR Place Recognition in Forests Attentioning Multiple BEV Density Images
Mar 06, 2025Place recognition is essential to maintain global consistency in large-scale localization systems. While research in urban environments has progressed significantly using LiDARs or cameras, applications in natural forest-like environments remain largely under-explored. Furthermore, forests present particular challenges due to high self-similarity and substantial variations in vegetation growth over time. In this work, we propose a robust LiDAR-based place recognition method for natural forests, ForestLPR. We hypothesize that a set of cross-sectional images of the forest's geometry at different heights contains the information needed to recognize revisiting a place. The cross-sectional images are represented by \ac{bev} density images of horizontal slices of the point cloud at different heights. Our approach utilizes a visual transformer as the shared backbone to produce sets of local descriptors and introduces a multi-BEV interaction module to attend to information at different heights adaptively. It is followed by an aggregation layer that produces a rotation-invariant place descriptor. We evaluated the efficacy of our method extensively on real-world data from public benchmarks as well as robotic datasets and compared it against the state-of-the-art (SOTA) methods. The results indicate that ForestLPR has consistently good performance on all evaluations and achieves an average increase of 7.38\% and 9.11\% on Recall@1 over the closest competitor on intra-sequence loop closure detection and inter-sequence re-localization, respectively, validating our hypothesis
HRVMamba: High-Resolution Visual State Space Model for Dense Prediction
Oct 04, 2024Recently, State Space Models (SSMs) with efficient hardware-aware designs, i.e., Mamba, have demonstrated significant potential in computer vision tasks due to their linear computational complexity with respect to token length and their global receptive field. However, Mamba's performance on dense prediction tasks, including human pose estimation and semantic segmentation, has been constrained by three key challenges: insufficient inductive bias, long-range forgetting, and low-resolution output representation. To address these challenges, we introduce the Dynamic Visual State Space (DVSS) block, which utilizes multi-scale convolutional kernels to extract local features across different scales and enhance inductive bias, and employs deformable convolution to mitigate the long-range forgetting problem while enabling adaptive spatial aggregation based on input and task-specific information. By leveraging the multi-resolution parallel design proposed in HRNet, we introduce High-Resolution Visual State Space Model (HRVMamba) based on the DVSS block, which preserves high-resolution representations throughout the entire process while promoting effective multi-scale feature learning. Extensive experiments highlight HRVMamba's impressive performance on dense prediction tasks, achieving competitive results against existing benchmark models without bells and whistles. Code is available at https://github.com/zhanghao5201/HRVMamba.