 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoRFT: Issue Resolving with Subtask-oriented Reinforced Fine-Tuning
Feb 27, 2025



Mainstream issue-resolving frameworks predominantly rely on commercial models, leading to high costs and privacy concerns. Existing training approaches for issue resolving struggle with poor generalization and fail to fully leverage open-source development resources. We propose Subtask-oriented Reinforced Fine-Tuning (SoRFT), a novel training approach to enhance the issue resolving capability of LLMs. We decomposes issue resolving into structured subtasks: file localization, function localization, line localization, and code edit generation. SoRFT consists of two training stages: (1) rejection-sampled supervised fine-tuning, Chain of Thought (CoT) data is filtered using ground-truth before fine-tuning the LLM, and (2) rule-based reinforcement learning, which leverages PPO with ground-truth based rewards. We evaluate the SoRFT-trained model on SWE-Bench Verified and SWE-Bench Lite, achieving state-of-the-art (SOTA) performance among open-source models (e.g., resolve 21.4% issues on SWE-Bench Verified with SoRFT-Qwen-7B). The experimental results demonstrate that SoRFT significantly enhances issue-resolving performance, improves model generalization, and provides a cost-efficient alternative to commercial models.
Repository Structure-Aware Training Makes SLMs Better Issue Resolver
Dec 26, 2024Language models have been applied to various software development tasks, but the performance varies according to the scale of the models. Large Language Models (LLMs) outperform Small Language Models (SLMs) in complex tasks like repository-level issue resolving, but raise concerns about privacy and cost. In contrast, SLMs are more accessible but under-perform in complex tasks. In this paper, we introduce ReSAT (Repository Structure-Aware Training), construct training data based on a large number of issues and corresponding pull requests from open-source communities to enhance the model's understanding of repository structure and issue resolving ability. We construct two types of training data: (1) localization training data, a multi-level progressive localization data to improve code understanding and localization capability; (2) code edit training data, which improves context-based code editing capability. The evaluation results on SWE-Bench-verified and RepoQA demonstrate that ReSAT effectively enhances SLMs' issue-resolving and repository-level long-context understanding capabilities.
Dehallucinating Parallel Context Extension for Retrieval-Augmented Generation
Dec 19, 2024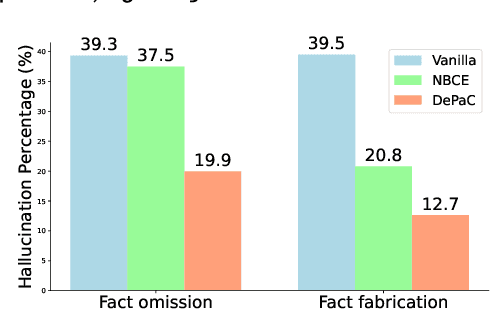
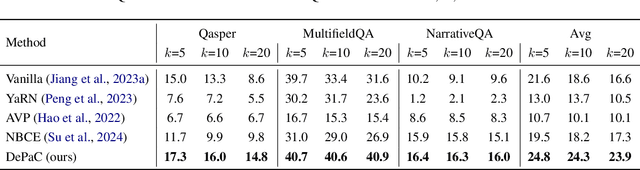

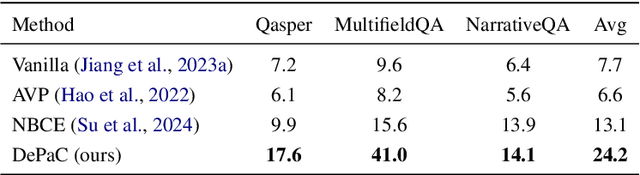
Large language models (LLMs) are susceptible to generating hallucinated information, despite the integration of retrieval-augmented generation (RAG). Parallel context extension (PCE) is a line of research attempting to effectively integrating parallel (unordered) contexts, while it still suffers from hallucinations when adapted to RAG scenarios. In this paper, we propose DePaC (Dehallucinating Parallel Context Extension), which alleviates the hallucination problem with context-aware negative training and information-calibrated aggregation. DePaC is designed to alleviate two types of in-context hallucination: fact fabrication (i.e., LLMs present claims that are not supported by the contexts) and fact omission (i.e., LLMs fail to present claims that can be supported by the contexts). Specifically, (1) for fact fabrication, we apply the context-aware negative training that fine-tunes the LLMs with negative supervisions, thus explicitly guiding the LLMs to refuse to answer when contexts are not related to questions; (2) for fact omission, we propose the information-calibrated aggregation which prioritizes context windows with higher information increment from their contexts. The experimental results on nine RAG tasks demonstrate that DePaC significantly alleviates the two types of hallucination and consistently achieves better performances on these tasks.
An Empirical Study on LLM-based Agents for Automated Bug Fixing
Nov 15, 2024



Large language models (LLMs) and LLM-based Agents have been applied to fix bugs automatically, demonstrating the capability in addressing software defects by engaging in development environment interaction, iterative validation and code modification. However, systematic analysis of these agent and non-agent systems remain limited, particularly regarding performance variations among top-performing ones. In this paper, we examine seven proprietary and open-source systems on the SWE-bench Lite benchmark for automated bug fixing. We first assess each system's overall performance, noting instances solvable by all or none of these sytems, and explore why some instances are uniquely solved by specific system types. We also compare fault localization accuracy at file and line levels and evaluate bug reproduction capabilities, identifying instances solvable only through dynamic reproduction. Through analysis, we concluded that further optimization is needed in both the LLM itself and the design of Agentic flow to improve the effectiveness of the Agent in bug fixing.
Make Your LLM Fully Utilize the Context
Apr 26, 2024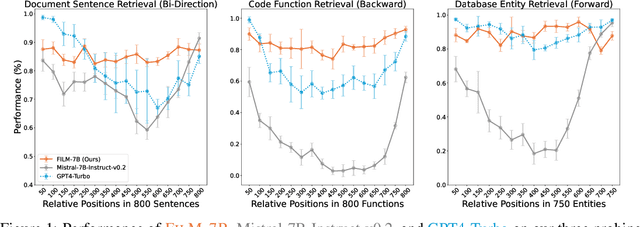
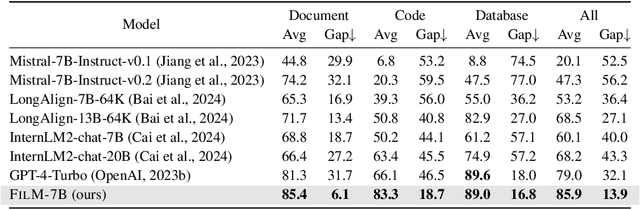
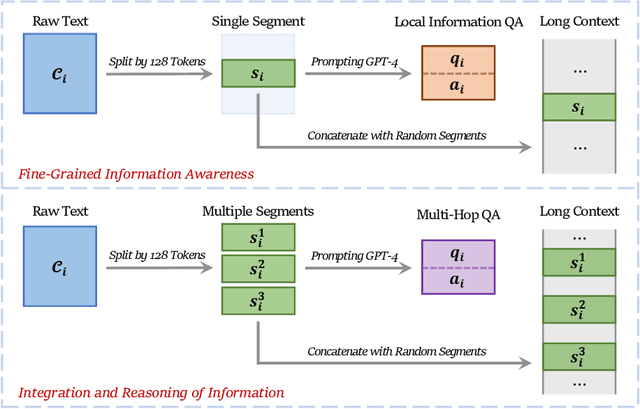
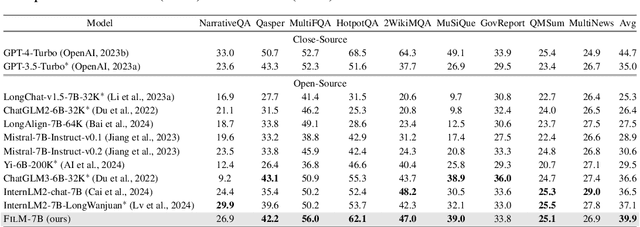
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information. Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle. Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the integration and reasoning of information from two or more short segments. Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FILl-in-the-Middle). To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval). The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window. Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU). Github Link: https://github.com/microsoft/FILM.
Compositional API Recommendation for Library-Oriented Code Generation
Feb 29, 2024
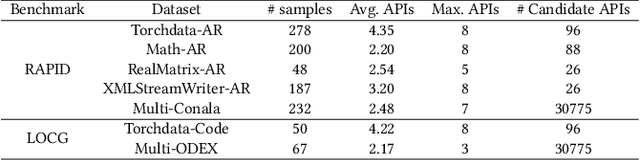
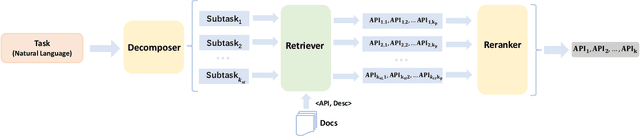
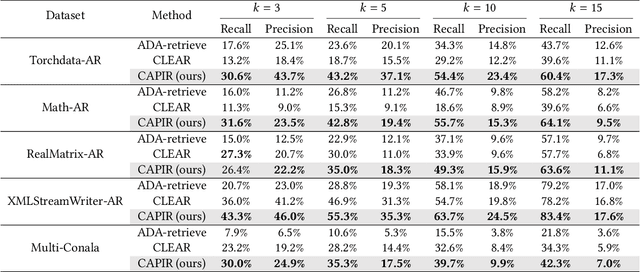
Large language models (LLMs) have achieved exceptional performance in code generation. However, the performance remains unsatisfactory in generating library-oriented code, especially for the libraries not present in the training data of LLMs. Previous work utilizes API recommendation technology to help LLMs use libraries: it retrieves APIs related to the user requirements, then leverages them as context to prompt LLMs. However, developmental requirements can be coarse-grained, requiring a combination of multiple fine-grained APIs. This granularity inconsistency makes API recommendation a challenging task. To address this, we propose CAPIR (Compositional API Recommendation), which adopts a "divide-and-conquer" strategy to recommend APIs for coarse-grained requirements. Specifically, CAPIR employs an LLM-based Decomposer to break down a coarse-grained task description into several detailed subtasks. Then, CAPIR applies an embedding-based Retriever to identify relevant APIs corresponding to each subtask. Moreover, CAPIR leverages an LLM-based Reranker to filter out redundant APIs and provides the final recommendation. To facilitate the evaluation of API recommendation methods on coarse-grained requirements, we present two challenging benchmarks, RAPID (Recommend APIs based on Documentation) and LOCG (Library-Oriented Code Generation). Experimental results on these benchmarks, demonstrate the effectiveness of CAPIR in comparison to existing baselines. Specifically, on RAPID's Torchdata-AR dataset, compared to the state-of-the-art API recommendation approach, CAPIR improves recall@5 from 18.7% to 43.2% and precision@5 from 15.5% to 37.1%. On LOCG's Torchdata-Code dataset, compared to code generation without API recommendation, CAPIR improves pass@100 from 16.0% to 28.0%.
Learning From Mistakes Makes LLM Better Reasoner
Nov 14, 2023Large language models (LLMs) recently exhibited remarkable reasoning capabilities on solving math problems. To further improve this capability, this work proposes Learning from Mistakes (LeMa), akin to human learning processes. Consider a human student who failed to solve a math problem, he will learn from what mistake he has made and how to correct it. Mimicking this error-driven learning process, LeMa fine-tunes LLMs on mistake-correction data pairs generated by GPT-4. Specifically, we first collect inaccurate reasoning paths from various LLMs and then employ GPT-4 as a "corrector" to (1) identify the mistake step, (2) explain the reason for the mistake, and (3) correct the mistake and generate the final answer. Experimental results demonstrate the effectiveness of LeMa: across five backbone LLMs and two mathematical reasoning tasks, LeMa consistently improves the performance compared with fine-tuning on CoT data alone. Impressively, LeMa can also benefit specialized LLMs such as WizardMath and MetaMath, achieving 85.4% pass@1 accuracy on GSM8K and 27.1% on MATH. This surpasses the SOTA performance achieved by non-execution open-source models on these challenging tasks. Our code, data and models will be publicly available at https://github.com/microsoft/LEMA.