 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Repository-level Software Documentation via Question Answering and Feature-Driven Development
Apr 08, 2026Software documentation is crucial for repository comprehension. While Large Language Models (LLMs) advance documentation generation from code snippets to entire repositories, existing benchmarks have two key limitations: (1) they lack a holistic, repository-level assessment, and (2) they rely on unreliable evaluation strategies, such as LLM-as-a-judge, which suffers from vague criteria and limited repository-level knowledge. To address these issues, we introduce SWD-Bench, a novel benchmark for evaluating repository-level software documentation. Inspired by documentation-driven development, our strategy evaluates documentation quality by assessing an LLM's ability to understand and implement functionalities using the documentation, rather than by directly scoring it. This is measured through function-driven Question Answering (QA) tasks. SWD-Bench comprises three interconnected QA tasks: (1) Functionality Detection, to determine if a functionality is described; (2) Functionality Localization, to evaluate the accuracy of locating related files; and (3) Functionality Completion, to measure the comprehensiveness of implementation details. We construct the benchmark, containing 4,170 entries, by mining high-quality Pull Requests and enriching them with repository-level context. Experiments reveal limitations in current documentation generation methods and show that source code provides complementary value. Notably, documentation from the best-performing method improves the issue-solving rate of SWE-Agent by 20.00%, which demonstrates the practical value of high-quality documentation in supporting documentation-driven development.
UFVideo: Towards Unified Fine-Grained Video Cooperative Understanding with Large Language Models
Dec 12, 2025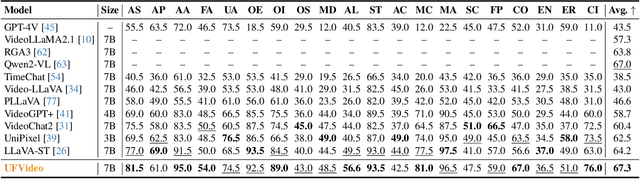
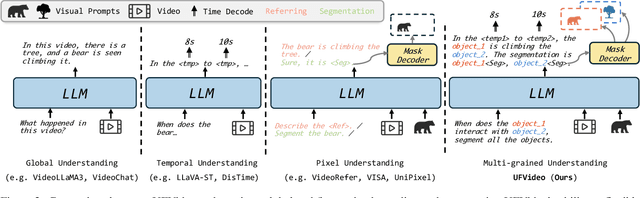
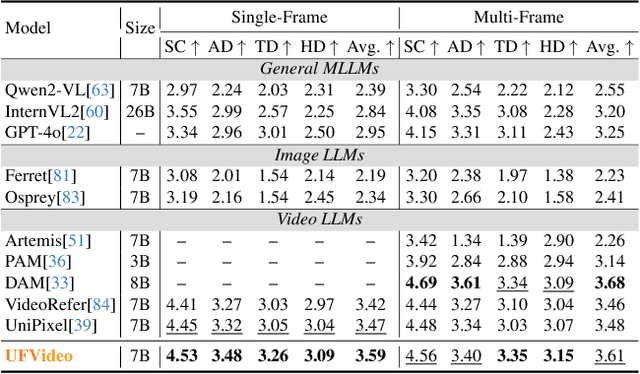
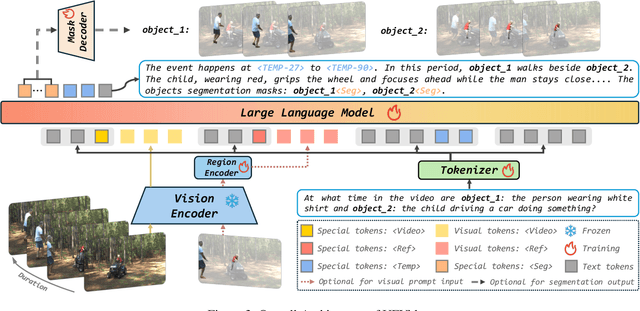
With the advancement of multi-modal Large Language Models (LLMs), Video LLMs have been further developed to perform on holistic and specialized video understanding. However, existing works are limited to specialized video understanding tasks, failing to achieve a comprehensive and multi-grained video perception. To bridge this gap, we introduce UFVideo, the first Video LLM with unified multi-grained cooperative understanding capabilities. Specifically, we design unified visual-language guided alignment to flexibly handle video understanding across global, pixel and temporal scales within a single model. UFVideo dynamically encodes the visual and text inputs of different tasks and generates the textual response, temporal localization, or grounded mask. Additionally, to evaluate challenging multi-grained video understanding tasks, we construct the UFVideo-Bench consisting of three distinct collaborative tasks within the scales, which demonstrates UFVideo's flexibility and advantages over GPT-4o. Furthermore, we validate the effectiveness of our model across 9 public benchmarks covering various common video understanding tasks, providing valuable insights for future Video LLMs.
Benchmarking LLMs for Fine-Grained Code Review with Enriched Context in Practice
Nov 10, 2025



Code review is a cornerstone of software quality assurance, and recent advances in Large Language Models (LLMs) have shown promise in automating this process. However, existing benchmarks for LLM-based code review face three major limitations. (1) Lack of semantic context: most benchmarks provide only code diffs without textual information such as issue descriptions, which are crucial for understanding developer intent. (2) Data quality issues: without rigorous validation, many samples are noisy-e.g., reviews on outdated or irrelevant code-reducing evaluation reliability. (3) Coarse granularity: most benchmarks operate at the file or commit level, overlooking the fine-grained, line-level reasoning essential for precise review. We introduce ContextCRBench, a high-quality, context-rich benchmark for fine-grained LLM evaluation in code review. Our construction pipeline comprises: (1) Raw Data Crawling, collecting 153.7K issues and pull requests from top-tier repositories; (2) Comprehensive Context Extraction, linking issue-PR pairs for textual context and extracting the full surrounding function or class for code context; and (3) Multi-stage Data Filtering, combining rule-based and LLM-based validation to remove outdated, malformed, or low-value samples, resulting in 67,910 context-enriched entries. ContextCRBench supports three evaluation scenarios aligned with the review workflow: (1) hunk-level quality assessment, (2) line-level defect localization, and (3) line-level comment generation. Evaluating eight leading LLMs (four closed-source and four open-source) reveals that textual context yields greater performance gains than code context alone, while current LLMs remain far from human-level review ability. Deployed at ByteDance, ContextCRBench drives a self-evolving code review system, improving performance by 61.98% and demonstrating its robustness and industrial utility.
Scalable Supervising Software Agents with Patch Reasoner
Oct 26, 2025



While large language model agents have advanced software engineering tasks, the unscalable nature of existing test-based supervision is limiting the potential improvement of data scaling. The reason is twofold: (1) building and running test sandbox is rather heavy and fragile, and (2) data with high-coverage tests is naturally rare and threatened by test hacking via edge cases. In this paper, we propose R4P, a patch verifier model to provide scalable rewards for training and testing SWE agents via reasoning. We consider that patch verification is fundamentally a reasoning task, mirroring how human repository maintainers review patches without writing and running new reproduction tests. To obtain sufficient reference and reduce the risk of reward hacking, R4P uses a group-wise objective for RL training, enabling it to verify multiple patches against each other's modification and gain a dense reward for stable training. R4P achieves 72.2% Acc. for verifying patches from SWE-bench-verified, surpassing OpenAI o3. To demonstrate R4P's practicality, we design and train a lite scaffold, Mini-SE, with pure reinforcement learning where all rewards are derived from R4P. As a result, Mini-SE achieves 26.2% Pass@1 on SWE-bench-verified, showing a 10.0% improvement over the original Qwen3-32B. This can be further improved to 32.8% with R4P for test-time scaling. Furthermore, R4P verifies patches within a second, 50x faster than testing on average. The stable scaling curves of rewards and accuracy along with high efficiency reflect R4P's practicality.
CodeVisionary: An Agent-based Framework for Evaluating Large Language Models in Code Generation
Apr 18, 2025Large language models (LLMs) have demonstrated strong capabilities in code generation, underscoring the critical need for rigorous and comprehensive evaluation. Existing evaluation approaches fall into three categories, including human-centered, metric-based, and LLM-based. Considering that human-centered approaches are labour-intensive and metric-based ones overly rely on reference answers, LLM-based approaches are gaining increasing attention due to their stronger contextual understanding capabilities and superior efficiency. However, the performance of LLM-based approaches remains limited due to: (1) lack of multisource domain knowledge, and (2) insufficient comprehension of complex code. To mitigate the limitations, we propose CodeVisionary, the first LLM-based agent framework for evaluating LLMs in code generation. CodeVisionary consists of two stages: (1) Multiscore knowledge analysis stage, which aims to gather multisource and comprehensive domain knowledge by formulating and executing a stepwise evaluation plan. (2) Negotiation-based scoring stage, which involves multiple judges engaging in discussions to better comprehend the complex code and reach a consensus on the evaluation score. Extensive experiments demonstrate that CodeVisionary achieves the best performance for evaluating LLMs in code generation, outperforming the best baseline methods with average improvements of 0.202, 0.139, and 0.117 in Pearson, Spearman, and Kendall-Tau coefficients, respectively. Besides, CodeVisionary provides detailed evaluation reports, which assist developers in identifying shortcomings and making improvements. The resources of CodeVisionary are available at https://anonymous.4open.science/r/CodeVisionary.
SoRFT: Issue Resolving with Subtask-oriented Reinforced Fine-Tuning
Feb 27, 2025



Mainstream issue-resolving frameworks predominantly rely on commercial models, leading to high costs and privacy concerns. Existing training approaches for issue resolving struggle with poor generalization and fail to fully leverage open-source development resources. We propose Subtask-oriented Reinforced Fine-Tuning (SoRFT), a novel training approach to enhance the issue resolving capability of LLMs. We decomposes issue resolving into structured subtasks: file localization, function localization, line localization, and code edit generation. SoRFT consists of two training stages: (1) rejection-sampled supervised fine-tuning, Chain of Thought (CoT) data is filtered using ground-truth before fine-tuning the LLM, and (2) rule-based reinforcement learning, which leverages PPO with ground-truth based rewards. We evaluate the SoRFT-trained model on SWE-Bench Verified and SWE-Bench Lite, achieving state-of-the-art (SOTA) performance among open-source models (e.g., resolve 21.4% issues on SWE-Bench Verified with SoRFT-Qwen-7B). The experimental results demonstrate that SoRFT significantly enhances issue-resolving performance, improves model generalization, and provides a cost-efficient alternative to commercial models.
Verification of Bit-Flip Attacks against Quantized Neural Networks
Feb 22, 2025



In the rapidly evolving landscape of neural network security, the resilience of neural networks against bit-flip attacks (i.e., an attacker maliciously flips an extremely small amount of bits within its parameter storage memory system to induce harmful behavior), has emerged as a relevant area of research. Existing studies suggest that quantization may serve as a viable defense against such attacks. Recognizing the documented susceptibility of real-valued neural networks to such attacks and the comparative robustness of quantized neural networks (QNNs), in this work, we introduce BFAVerifier, the first verification framework designed to formally verify the absence of bit-flip attacks or to identify all vulnerable parameters in a sound and rigorous manner. BFAVerifier comprises two integral components: an abstraction-based method and an MILP-based method. Specifically, we first conduct a reachability analysis with respect to symbolic parameters that represent the potential bit-flip attacks, based on a novel abstract domain with a sound guarantee. If the reachability analysis fails to prove the resilience of such attacks, then we encode this verification problem into an equivalent MILP problem which can be solved by off-the-shelf solvers. Therefore, BFAVerifier is sound, complete, and reasonably efficient. We conduct extensive experiments, which demonstrate its effectiveness and efficiency across various network architectures, quantization bit-widths, and adversary capabilities.
CodeRepoQA: A Large-scale Benchmark for Software Engineering Question Answering
Dec 19, 2024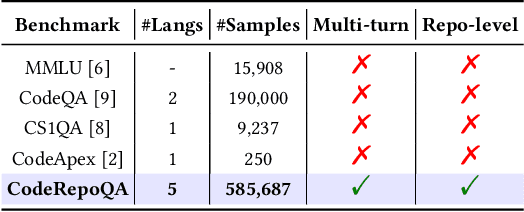
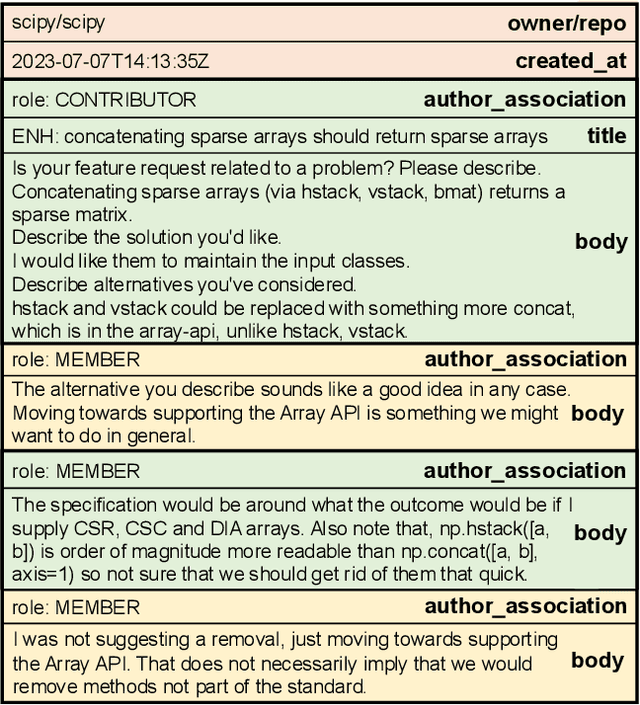

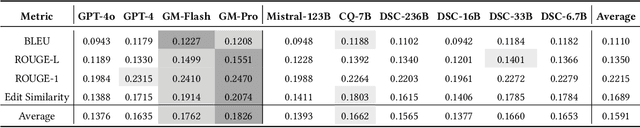
In this work, we introduce CodeRepoQA, a large-scale benchmark specifically designed for evaluating repository-level question-answering capabilities in the field of software engineering. CodeRepoQA encompasses five programming languages and covers a wide range of scenarios, enabling comprehensive evaluation of language models. To construct this dataset, we crawl data from 30 well-known repositories in GitHub, the largest platform for hosting and collaborating on code, and carefully filter raw data. In total, CodeRepoQA is a multi-turn question-answering benchmark with 585,687 entries, covering a diverse array of software engineering scenarios, with an average of 6.62 dialogue turns per entry. We evaluate ten popular large language models on our dataset and provide in-depth analysis. We find that LLMs still have limitations in question-answering capabilities in the field of software engineering, and medium-length contexts are more conducive to LLMs' performance. The entire benchmark is publicly available at https://github.com/kinesiatricssxilm14/CodeRepoQA.
AEGIS: An Agent-based Framework for General Bug Reproduction from Issue Descriptions
Nov 27, 2024In software maintenance, bug reproduction is essential for effective fault localization and repair. Manually writing reproduction scripts is a time-consuming task with high requirements for developers. Hence, automation of bug reproduction has increasingly attracted attention from researchers and practitioners. However, the existing studies on bug reproduction are generally limited to specific bug types such as program crashes, and hard to be applied to general bug reproduction. In this paper, considering the superior performance of agent-based methods in code intelligence tasks, we focus on designing an agent-based framework for the task. Directly employing agents would lead to limited bug reproduction performance, due to entangled subtasks, lengthy retrieved context, and unregulated actions. To mitigate the challenges, we propose an Automated gEneral buG reproductIon Scripts generation framework, named AEGIS, which is the first agent-based framework for the task. AEGIS mainly contains two modules: (1) A concise context construction module, which aims to guide the code agent in extracting structured information from issue descriptions, identifying issue-related code with detailed explanations, and integrating these elements to construct the concise context; (2) A FSM-based multi-feedback optimization module to further regulate the behavior of the code agent within the finite state machine (FSM), ensuring a controlled and efficient script generation process based on multi-dimensional feedback. Extensive experiments on the public benchmark dataset show that AEGIS outperforms the state-of-the-art baseline by 23.0% in F->P metric. In addition, the bug reproduction scripts generated by AEGIS can improve the relative resolved rate of Agentless by 12.5%.
An Empirical Study on LLM-based Agents for Automated Bug Fixing
Nov 15, 2024



Large language models (LLMs) and LLM-based Agents have been applied to fix bugs automatically, demonstrating the capability in addressing software defects by engaging in development environment interaction, iterative validation and code modification. However, systematic analysis of these agent and non-agent systems remain limited, particularly regarding performance variations among top-performing ones. In this paper, we examine seven proprietary and open-source systems on the SWE-bench Lite benchmark for automated bug fixing. We first assess each system's overall performance, noting instances solvable by all or none of these sytems, and explore why some instances are uniquely solved by specific system types. We also compare fault localization accuracy at file and line levels and evaluate bug reproduction capabilities, identifying instances solvable only through dynamic reproduction. Through analysis, we concluded that further optimization is needed in both the LLM itself and the design of Agentic flow to improve the effectiveness of the Agent in bug fixing.