 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIORS: Personalized Intelligent Outpatient Reception based on Large Language Model with Multi-Agents Medical Scenario Simulation
Nov 21, 2024



In China, receptionist nurses face overwhelming workloads in outpatient settings, limiting their time and attention for each patient and ultimately reducing service quality. In this paper, we present the Personalized Intelligent Outpatient Reception System (PIORS). This system integrates an LLM-based reception nurse and a collaboration between LLM and hospital information system (HIS) into real outpatient reception setting, aiming to deliver personalized, high-quality, and efficient reception services. Additionally, to enhance the performance of LLMs in real-world healthcare scenarios, we propose a medical conversational data generation framework named Service Flow aware Medical Scenario Simulation (SFMSS), aiming to adapt the LLM to the real-world environments and PIORS settings. We evaluate the effectiveness of PIORS and SFMSS through automatic and human assessments involving 15 users and 15 clinical experts. The results demonstrate that PIORS-Nurse outperforms all baselines, including the current state-of-the-art model GPT-4o, and aligns with human preferences and clinical needs. Further details and demo can be found at https://github.com/FudanDISC/PIORS
Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis
Sep 10, 2024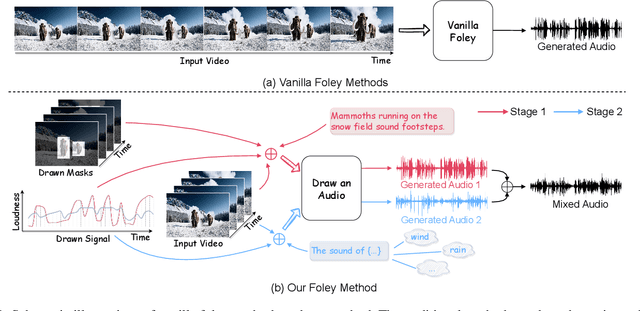
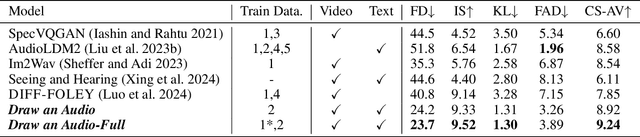
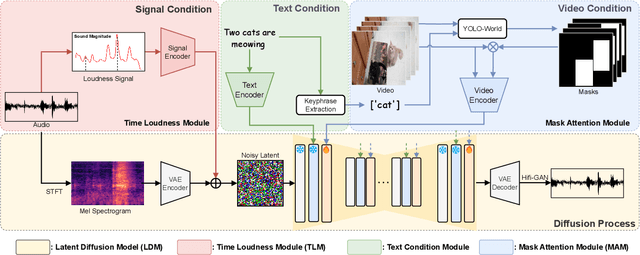
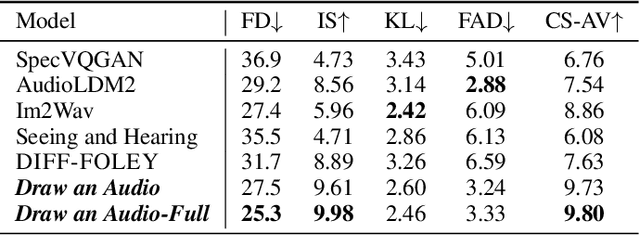
Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art. Project page: https://yannqi.github.io/Draw-an-Audio/.
BrainODE: Dynamic Brain Signal Analysis via Graph-Aided Neural Ordinary Differential Equations
Apr 30, 2024



Brain network analysis is vital for understanding the neural interactions regarding brain structures and functions, and identifying potential biomarkers for clinical phenotypes. However, widely used brain signals such as Blood Oxygen Level Dependent (BOLD) time series generated from functional Magnetic Resonance Imaging (fMRI) often manifest three challenges: (1) missing values, (2) irregular samples, and (3) sampling misalignment, due to instrumental limitations, impacting downstream brain network analysis and clinical outcome predictions. In this work, we propose a novel model called BrainODE to achieve continuous modeling of dynamic brain signals using Ordinary Differential Equations (ODE). By learning latent initial values and neural ODE functions from irregular time series, BrainODE effectively reconstructs brain signals at any time point, mitigating the aforementioned three data challenges of brain signals altogether. Comprehensive experimental results on real-world neuroimaging datasets demonstrate the superior performance of BrainODE and its capability of addressing the three data challenges.
CustomListener: Text-guided Responsive Interaction for User-friendly Listening Head Generation
Mar 01, 2024Listening head generation aims to synthesize a non-verbal responsive listener head by modeling the correlation between the speaker and the listener in dynamic conversion.The applications of listener agent generation in virtual interaction have promoted many works achieving the diverse and fine-grained motion generation. However, they can only manipulate motions through simple emotional labels, but cannot freely control the listener's motions. Since listener agents should have human-like attributes (e.g. identity, personality) which can be freely customized by users, this limits their realism. In this paper, we propose a user-friendly framework called CustomListener to realize the free-form text prior guided listener generation. To achieve speaker-listener coordination, we design a Static to Dynamic Portrait module (SDP), which interacts with speaker information to transform static text into dynamic portrait token with completion rhythm and amplitude information. To achieve coherence between segments, we design a Past Guided Generation Module (PGG) to maintain the consistency of customized listener attributes through the motion prior, and utilize a diffusion-based structure conditioned on the portrait token and the motion prior to realize the controllable generation. To train and evaluate our model, we have constructed two text-annotated listening head datasets based on ViCo and RealTalk, which provide text-video paired labels. Extensive experiments have verified the effectiveness of our model.
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
Dec 11, 2023Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. Code and more results will be publicly available at https://combo-avs.github.io/.
Dynamic Brain Transformer with Multi-level Attention for Functional Brain Network Analysis
Sep 05, 2023Recent neuroimaging studies have highlighted the importance of network-centric brain analysis, particularly with functional magnetic resonance imaging. The emergence of Deep Neural Networks has fostered a substantial interest in predicting clinical outcomes and categorizing individuals based on brain networks. However, the conventional approach involving static brain network analysis offers limited potential in capturing the dynamism of brain function. Although recent studies have attempted to harness dynamic brain networks, their high dimensionality and complexity present substantial challenges. This paper proposes a novel methodology, Dynamic bRAin Transformer (DART), which combines static and dynamic brain networks for more effective and nuanced brain function analysis. Our model uses the static brain network as a baseline, integrating dynamic brain networks to enhance performance against traditional methods. We innovatively employ attention mechanisms, enhancing model explainability and exploiting the dynamic brain network's temporal variations. The proposed approach offers a robust solution to the low signal-to-noise ratio of blood-oxygen-level-dependent signals, a recurring issue in direct DNN modeling. It also provides valuable insights into which brain circuits or dynamic networks contribute more to final predictions. As such, DRAT shows a promising direction in neuroimaging studies, contributing to the comprehensive understanding of brain organization and the role of neural circuits.
Controllable Guide-Space for Generalizable Face Forgery Detection
Jul 26, 2023
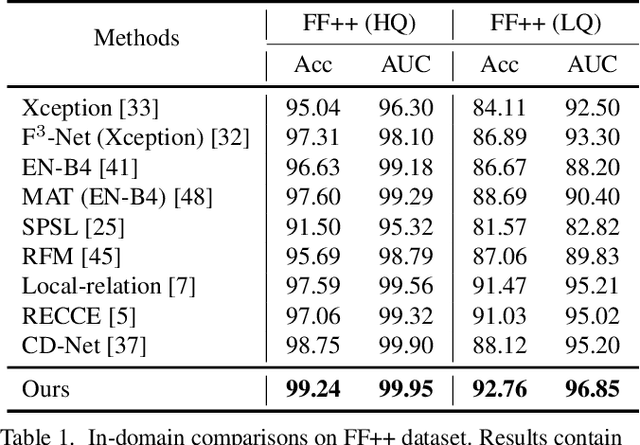
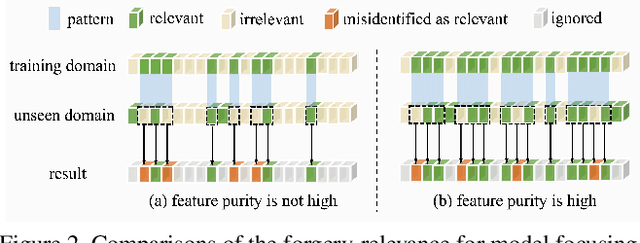
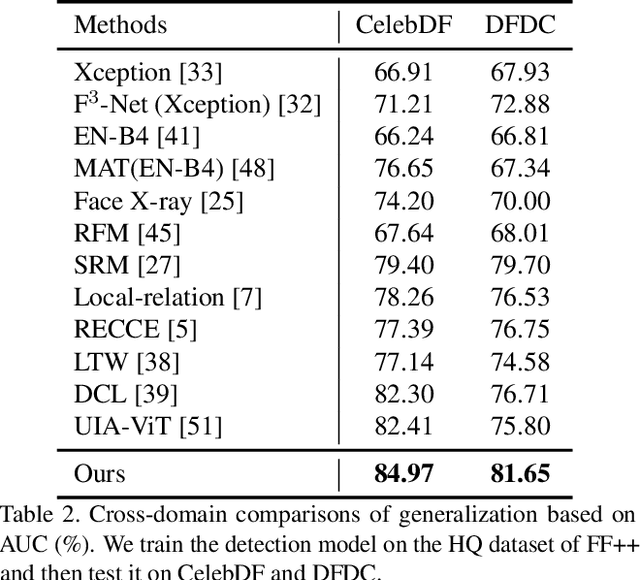
Recent studies on face forgery detection have shown satisfactory performance for methods involved in training datasets, but are not ideal enough for unknown domains. This motivates many works to improve the generalization, but forgery-irrelevant information, such as image background and identity, still exists in different domain features and causes unexpected clustering, limiting the generalization. In this paper, we propose a controllable guide-space (GS) method to enhance the discrimination of different forgery domains, so as to increase the forgery relevance of features and thereby improve the generalization. The well-designed guide-space can simultaneously achieve both the proper separation of forgery domains and the large distance between real-forgery domains in an explicit and controllable manner. Moreover, for better discrimination, we use a decoupling module to weaken the interference of forgery-irrelevant correlations between domains. Furthermore, we make adjustments to the decision boundary manifold according to the clustering degree of the same domain features within the neighborhood. Extensive experiments in multiple in-domain and cross-domain settings confirm that our method can achieve state-of-the-art generalization.
R-Mixup: Riemannian Mixup for Biological Networks
Jun 05, 2023



Biological networks are commonly used in biomedical and healthcare domains to effectively model the structure of complex biological systems with interactions linking biological entities. However, due to their characteristics of high dimensionality and low sample size, directly applying deep learning models on biological networks usually faces severe overfitting. In this work, we propose R-MIXUP, a Mixup-based data augmentation technique that suits the symmetric positive definite (SPD) property of adjacency matrices from biological networks with optimized training efficiency. The interpolation process in R-MIXUP leverages the log-Euclidean distance metrics from the Riemannian manifold, effectively addressing the swelling effect and arbitrarily incorrect label issues of vanilla Mixup. We demonstrate the effectiveness of R-MIXUP with five real-world biological network datasets on both regression and classification tasks. Besides, we derive a commonly ignored necessary condition for identifying the SPD matrices of biological networks and empirically study its influence on the model performance. The code implementation can be found in Appendix E.
Transformer-Based Hierarchical Clustering for Brain Network Analysis
May 06, 2023



Brain networks, graphical models such as those constructed from MRI, have been widely used in pathological prediction and analysis of brain functions. Within the complex brain system, differences in neuronal connection strengths parcellate the brain into various functional modules (network communities), which are critical for brain analysis. However, identifying such communities within the brain has been a nontrivial issue due to the complexity of neuronal interactions. In this work, we propose a novel interpretable transformer-based model for joint hierarchical cluster identification and brain network classification. Extensive experimental results on real-world brain network datasets show that with the help of hierarchical clustering, the model achieves increased accuracy and reduced runtime complexity while providing plausible insight into the functional organization of brain regions. The implementation is available at https://github.com/DDVD233/THC.
Simultaneously Optimizing Perturbations and Positions for Black-box Adversarial Patch Attacks
Dec 26, 2022Adversarial patch is an important form of real-world adversarial attack that brings serious risks to the robustness of deep neural networks. Previous methods generate adversarial patches by either optimizing their perturbation values while fixing the pasting position or manipulating the position while fixing the patch's content. This reveals that the positions and perturbations are both important to the adversarial attack. For that, in this paper, we propose a novel method to simultaneously optimize the position and perturbation for an adversarial patch, and thus obtain a high attack success rate in the black-box setting. Technically, we regard the patch's position, the pre-designed hyper-parameters to determine the patch's perturbations as the variables, and utilize the reinforcement learning framework to simultaneously solve for the optimal solution based on the rewards obtained from the target model with a small number of queries. Extensive experiments are conducted on the Face Recognition (FR) task, and results on four representative FR models show that our method can significantly improve the attack success rate and query efficiency. Besides, experiments on the commercial FR service and physical environments confirm its practical application value. We also extend our method to the traffic sign recognition task to verify its generalization ability.