 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositionOCR: Augmenting Positional Awareness in Multi-Modal Models via Hybrid Specialist Integration
Feb 22, 2026In recent years, Multi-modal Large Language Models (MLLMs) have achieved strong performance in OCR-centric Visual Question Answering (VQA) tasks, illustrating their capability to process heterogeneous data and exhibit adaptability across varied contexts. However, these MLLMs rely on a Large Language Model (LLM) as the decoder, which is primarily designed for linguistic processing, and thus inherently lacks the positional reasoning required for precise visual tasks, such as text spotting and text grounding. Additionally, the extensive parameters of MLLMs necessitate substantial computational resources and large-scale data for effective training. Conversely, text spotting specialists achieve state-of-the-art coordinate predictions but lack semantic reasoning capabilities. This dichotomy motivates our key research question: Can we synergize the efficiency of specialists with the contextual power of LLMs to create a positionally-accurate MLLM? To overcome these challenges, we introduce PositionOCR, a parameter-efficient hybrid architecture that seamlessly integrates a text spotting model's positional strengths with an LLM's contextual reasoning. Comprising 131M trainable parameters, this framework demonstrates outstanding multi-modal processing capabilities, particularly excelling in tasks such as text grounding and text spotting, consistently surpassing traditional MLLMs.
Empirical Comparison of Encoder-Based Language Models and Feature-Based Supervised Machine Learning Approaches to Automated Scoring of Long Essays
Jan 07, 2026Long context may impose challenges for encoder-only language models in text processing, specifically for automated scoring of essays. This study trained several commonly used encoder-based language models for automated scoring of long essays. The performance of these trained models was evaluated and compared with the ensemble models built upon the base language models with a token limit of 512?. The experimented models include BERT-based models (BERT, RoBERTa, DistilBERT, and DeBERTa), ensemble models integrating embeddings from multiple encoder models, and ensemble models of feature-based supervised machine learning models, including Gradient-Boosted Decision Trees, eXtreme Gradient Boosting, and Light Gradient Boosting Machine. We trained, validated, and tested each model on a dataset of 17,307 essays, with an 80%/10%/10% split, and evaluated model performance using Quadratic Weighted Kappa. This study revealed that an ensemble-of-embeddings model that combines multiple pre-trained language model representations with gradient-boosting classifier as the ensemble model significantly outperforms individual language models at scoring long essays.
UFVideo: Towards Unified Fine-Grained Video Cooperative Understanding with Large Language Models
Dec 12, 2025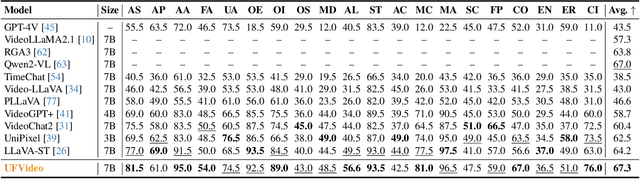
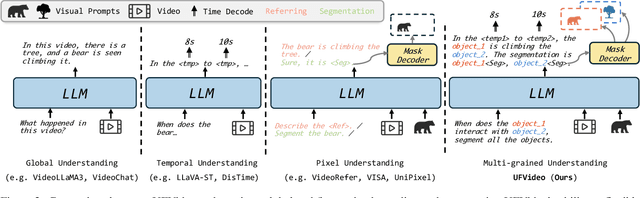
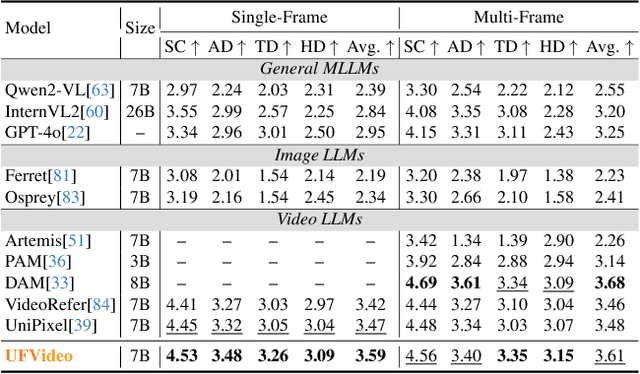
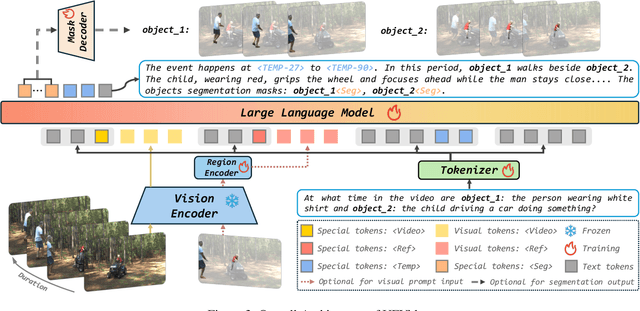
With the advancement of multi-modal Large Language Models (LLMs), Video LLMs have been further developed to perform on holistic and specialized video understanding. However, existing works are limited to specialized video understanding tasks, failing to achieve a comprehensive and multi-grained video perception. To bridge this gap, we introduce UFVideo, the first Video LLM with unified multi-grained cooperative understanding capabilities. Specifically, we design unified visual-language guided alignment to flexibly handle video understanding across global, pixel and temporal scales within a single model. UFVideo dynamically encodes the visual and text inputs of different tasks and generates the textual response, temporal localization, or grounded mask. Additionally, to evaluate challenging multi-grained video understanding tasks, we construct the UFVideo-Bench consisting of three distinct collaborative tasks within the scales, which demonstrates UFVideo's flexibility and advantages over GPT-4o. Furthermore, we validate the effectiveness of our model across 9 public benchmarks covering various common video understanding tasks, providing valuable insights for future Video LLMs.
MotionCharacter: Identity-Preserving and Motion Controllable Human Video Generation
Nov 30, 2024



Recent advancements in personalized Text-to-Video (T2V) generation highlight the importance of integrating character-specific identities and actions. However, previous T2V models struggle with identity consistency and controllable motion dynamics, mainly due to limited fine-grained facial and action-based textual prompts, and datasets that overlook key human attributes and actions. To address these challenges, we propose MotionCharacter, an efficient and high-fidelity human video generation framework designed for identity preservation and fine-grained motion control. We introduce an ID-preserving module to maintain identity fidelity while allowing flexible attribute modifications, and further integrate ID-consistency and region-aware loss mechanisms, significantly enhancing identity consistency and detail fidelity. Additionally, our approach incorporates a motion control module that prioritizes action-related text while maintaining subject consistency, along with a dataset, Human-Motion, which utilizes large language models to generate detailed motion descriptions. For simplify user control during inference, we parameterize motion intensity through a single coefficient, allowing for easy adjustments. Extensive experiments highlight the effectiveness of MotionCharacter, demonstrating significant improvements in ID-preserving, high-quality video generation.
Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis
Sep 10, 2024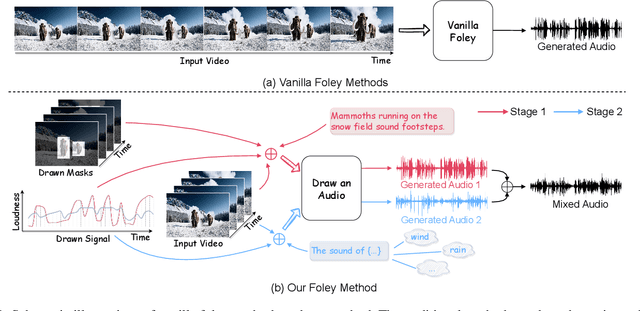
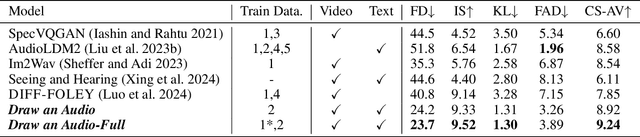
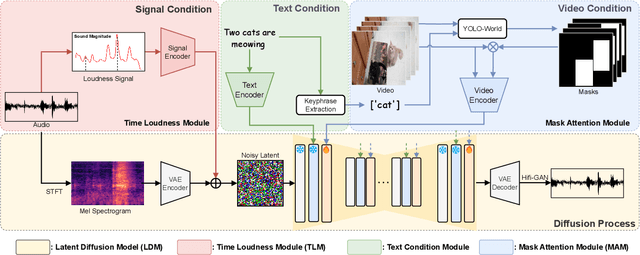
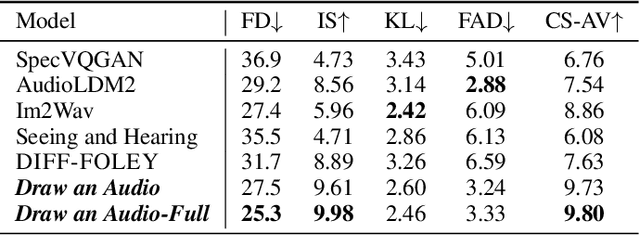
Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art. Project page: https://yannqi.github.io/Draw-an-Audio/.
AdaFedFR: Federated Face Recognition with Adaptive Inter-Class Representation Learning
May 22, 2024



With the growing attention on data privacy and communication security in face recognition applications, federated learning has been introduced to learn a face recognition model with decentralized datasets in a privacy-preserving manner. However, existing works still face challenges such as unsatisfying performance and additional communication costs, limiting their applicability in real-world scenarios. In this paper, we propose a simple yet effective federated face recognition framework called AdaFedFR, by devising an adaptive inter-class representation learning algorithm to enhance the generalization of the generic face model and the efficiency of federated training under strict privacy-preservation. In particular, our work delicately utilizes feature representations of public identities as learnable negative knowledge to optimize the local objective within the feature space, which further encourages the local model to learn powerful representations and optimize personalized models for clients. Experimental results demonstrate that our method outperforms previous approaches on several prevalent face recognition benchmarks within less than 3 communication rounds, which shows communication-friendly and great efficiency.
Joint Physical-Digital Facial Attack Detection Via Simulating Spoofing Clues
Apr 12, 2024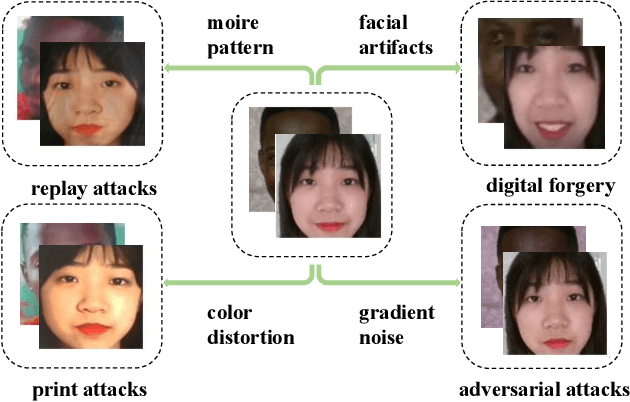
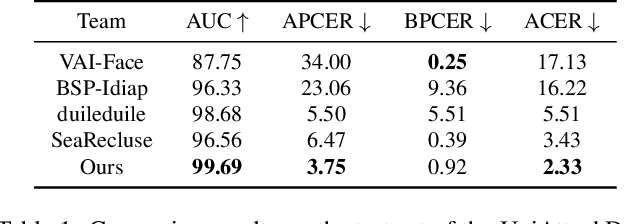
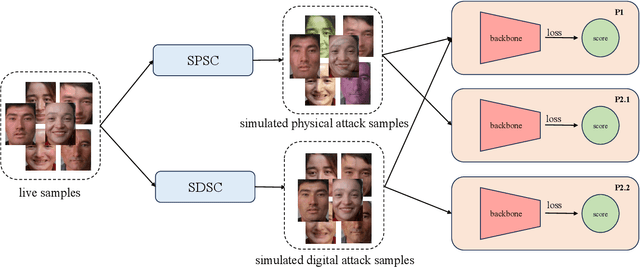
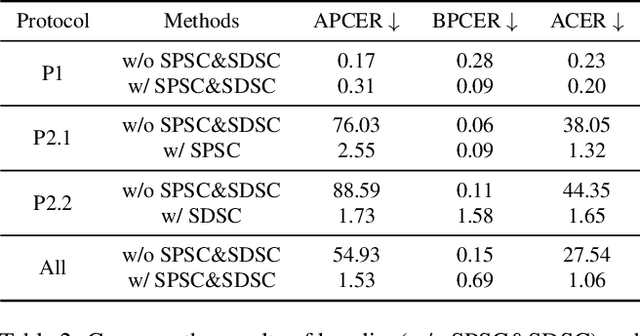
Face recognition systems are frequently subjected to a variety of physical and digital attacks of different types. Previous methods have achieved satisfactory performance in scenarios that address physical attacks and digital attacks, respectively. However, few methods are considered to integrate a model that simultaneously addresses both physical and digital attacks, implying the necessity to develop and maintain multiple models. To jointly detect physical and digital attacks within a single model, we propose an innovative approach that can adapt to any network architecture. Our approach mainly contains two types of data augmentation, which we call Simulated Physical Spoofing Clues augmentation (SPSC) and Simulated Digital Spoofing Clues augmentation (SDSC). SPSC and SDSC augment live samples into simulated attack samples by simulating spoofing clues of physical and digital attacks, respectively, which significantly improve the capability of the model to detect "unseen" attack types. Extensive experiments show that SPSC and SDSC can achieve state-of-the-art generalization in Protocols 2.1 and 2.2 of the UniAttackData dataset, respectively. Our method won first place in "Unified Physical-Digital Face Attack Detection" of the 5th Face Anti-spoofing Challenge@CVPR2024. Our final submission obtains 3.75% APCER, 0.93% BPCER, and 2.34% ACER, respectively. Our code is available at https://github.com/Xianhua-He/cvpr2024-face-anti-spoofing-challenge.
CustomListener: Text-guided Responsive Interaction for User-friendly Listening Head Generation
Mar 01, 2024

Listening head generation aims to synthesize a non-verbal responsive listener head by modeling the correlation between the speaker and the listener in dynamic conversion.The applications of listener agent generation in virtual interaction have promoted many works achieving the diverse and fine-grained motion generation. However, they can only manipulate motions through simple emotional labels, but cannot freely control the listener's motions. Since listener agents should have human-like attributes (e.g. identity, personality) which can be freely customized by users, this limits their realism. In this paper, we propose a user-friendly framework called CustomListener to realize the free-form text prior guided listener generation. To achieve speaker-listener coordination, we design a Static to Dynamic Portrait module (SDP), which interacts with speaker information to transform static text into dynamic portrait token with completion rhythm and amplitude information. To achieve coherence between segments, we design a Past Guided Generation Module (PGG) to maintain the consistency of customized listener attributes through the motion prior, and utilize a diffusion-based structure conditioned on the portrait token and the motion prior to realize the controllable generation. To train and evaluate our model, we have constructed two text-annotated listening head datasets based on ViCo and RealTalk, which provide text-video paired labels. Extensive experiments have verified the effectiveness of our model.
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
Dec 11, 2023Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. Code and more results will be publicly available at https://combo-avs.github.io/.
LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation
Nov 01, 2023
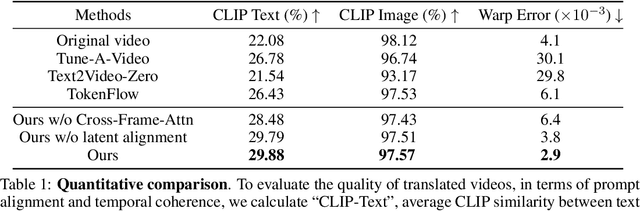

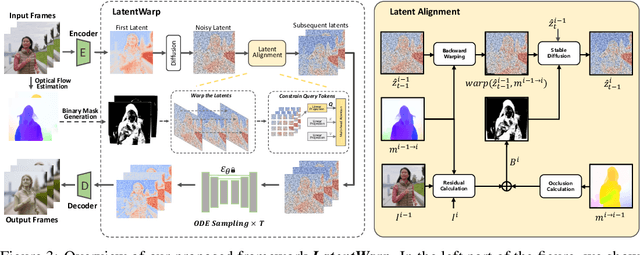
Leveraging the generative ability of image diffusion models offers great potential for zero-shot video-to-video translation. The key lies in how to maintain temporal consistency across generated video frames by image diffusion models. Previous methods typically adopt cross-frame attention, \emph{i.e.,} sharing the \textit{key} and \textit{value} tokens across attentions of different frames, to encourage the temporal consistency. However, in those works, temporal inconsistency issue may not be thoroughly solved, rendering the fidelity of generated videos limited.%The current state of the art cross-frame attention method aims at maintaining fine-grained visual details across frames, but it is still challenged by the temporal coherence problem. In this paper, we find the bottleneck lies in the unconstrained query tokens and propose a new zero-shot video-to-video translation framework, named \textit{LatentWarp}. Our approach is simple: to constrain the query tokens to be temporally consistent, we further incorporate a warping operation in the latent space to constrain the query tokens. Specifically, based on the optical flow obtained from the original video, we warp the generated latent features of last frame to align with the current frame during the denoising process. As a result, the corresponding regions across the adjacent frames can share closely-related query tokens and attention outputs, which can further improve latent-level consistency to enhance visual temporal coherence of generated videos. Extensive experiment results demonstrate the superiority of \textit{LatentWarp} in achieving video-to-video translation with temporal coherence.