 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate Models on Incomplete Data with Minimal Imputation
Mar 18, 2025



Missing data often exists in real-world datasets, requiring significant time and effort for imputation to learn accurate machine learning (ML) models. In this paper, we demonstrate that imputing all missing values is not always necessary to achieve an accurate ML model. We introduce the concept of minimal data imputation, which ensures accurate ML models trained over the imputed dataset. Implementing minimal imputation guarantees both minimal imputation effort and optimal ML models. We propose algorithms to find exact and approximate minimal imputation for various ML models. Our extensive experiments indicate that our proposed algorithms significantly reduce the time and effort required for data imputation.
Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis
Sep 10, 2024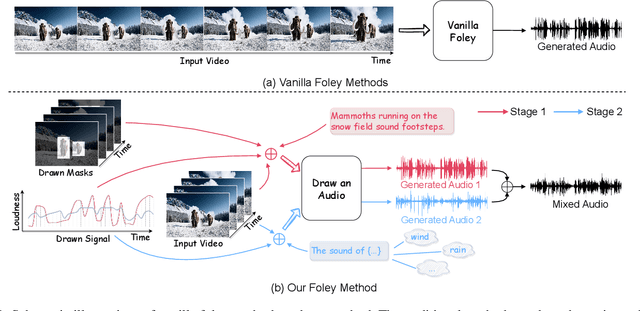
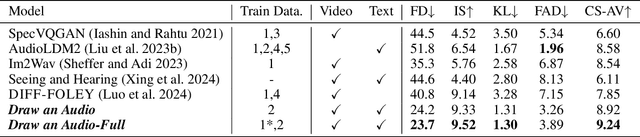
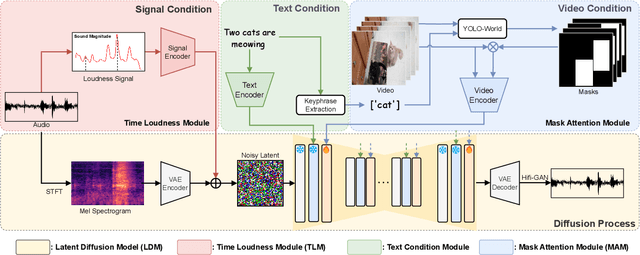
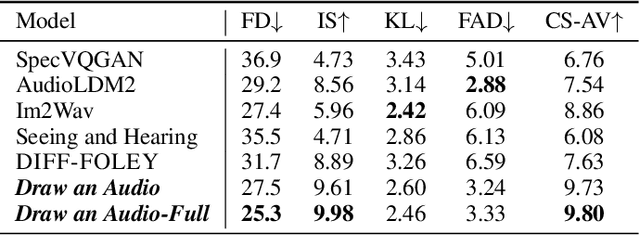
Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art. Project page: https://yannqi.github.io/Draw-an-Audio/.
Certain and Approximately Certain Models for Statistical Learning
Mar 01, 2024



Real-world data is often incomplete and contains missing values. To train accurate models over real-world datasets, users need to spend a substantial amount of time and resources imputing and finding proper values for missing data items. In this paper, we demonstrate that it is possible to learn accurate models directly from data with missing values for certain training data and target models. We propose a unified approach for checking the necessity of data imputation to learn accurate models across various widely-used machine learning paradigms. We build efficient algorithms with theoretical guarantees to check this necessity and return accurate models in cases where imputation is unnecessary. Our extensive experiments indicate that our proposed algorithms significantly reduce the amount of time and effort needed for data imputation without imposing considerable computational overhead.
CustomListener: Text-guided Responsive Interaction for User-friendly Listening Head Generation
Mar 01, 2024

Listening head generation aims to synthesize a non-verbal responsive listener head by modeling the correlation between the speaker and the listener in dynamic conversion.The applications of listener agent generation in virtual interaction have promoted many works achieving the diverse and fine-grained motion generation. However, they can only manipulate motions through simple emotional labels, but cannot freely control the listener's motions. Since listener agents should have human-like attributes (e.g. identity, personality) which can be freely customized by users, this limits their realism. In this paper, we propose a user-friendly framework called CustomListener to realize the free-form text prior guided listener generation. To achieve speaker-listener coordination, we design a Static to Dynamic Portrait module (SDP), which interacts with speaker information to transform static text into dynamic portrait token with completion rhythm and amplitude information. To achieve coherence between segments, we design a Past Guided Generation Module (PGG) to maintain the consistency of customized listener attributes through the motion prior, and utilize a diffusion-based structure conditioned on the portrait token and the motion prior to realize the controllable generation. To train and evaluate our model, we have constructed two text-annotated listening head datasets based on ViCo and RealTalk, which provide text-video paired labels. Extensive experiments have verified the effectiveness of our model.
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
Dec 11, 2023Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. Code and more results will be publicly available at https://combo-avs.github.io/.
Controllable Guide-Space for Generalizable Face Forgery Detection
Jul 26, 2023
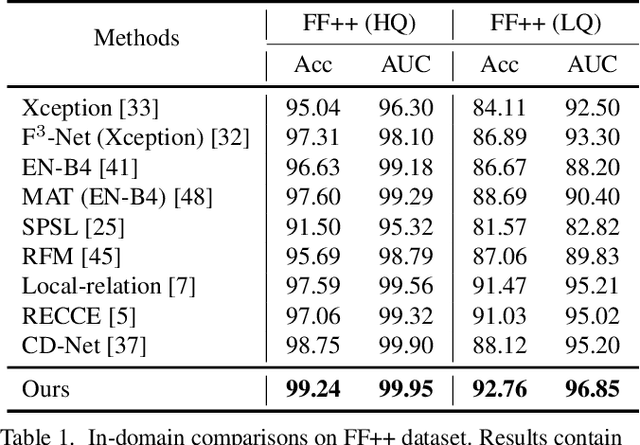
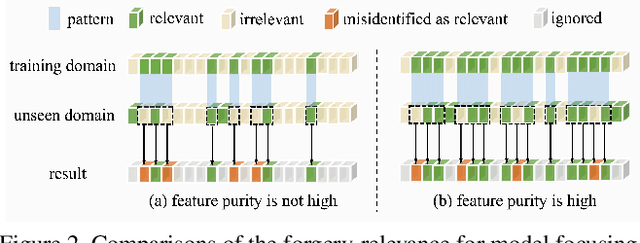
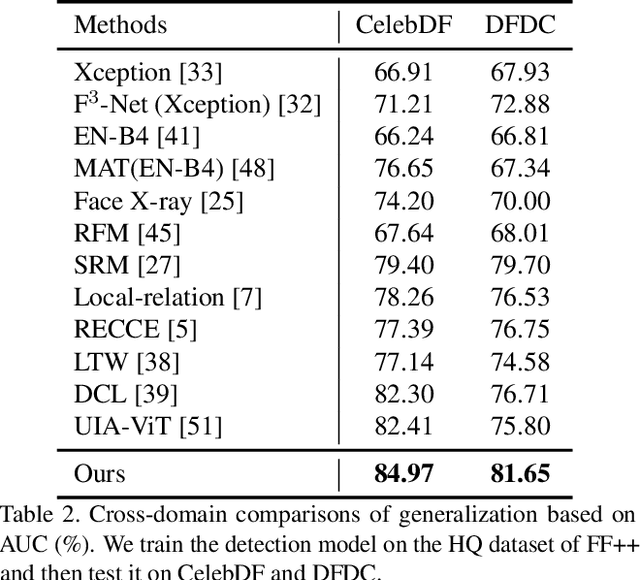
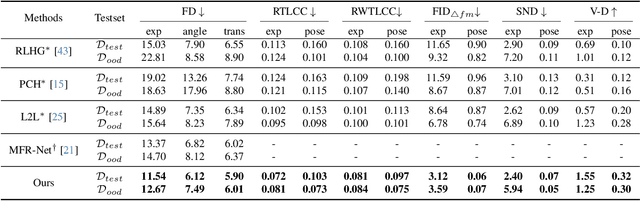
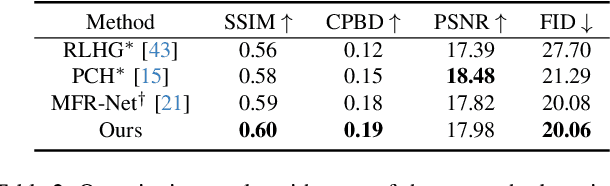
Recent studies on face forgery detection have shown satisfactory performance for methods involved in training datasets, but are not ideal enough for unknown domains. This motivates many works to improve the generalization, but forgery-irrelevant information, such as image background and identity, still exists in different domain features and causes unexpected clustering, limiting the generalization. In this paper, we propose a controllable guide-space (GS) method to enhance the discrimination of different forgery domains, so as to increase the forgery relevance of features and thereby improve the generalization. The well-designed guide-space can simultaneously achieve both the proper separation of forgery domains and the large distance between real-forgery domains in an explicit and controllable manner. Moreover, for better discrimination, we use a decoupling module to weaken the interference of forgery-irrelevant correlations between domains. Furthermore, we make adjustments to the decision boundary manifold according to the clustering degree of the same domain features within the neighborhood. Extensive experiments in multiple in-domain and cross-domain settings confirm that our method can achieve state-of-the-art generalization.
Designing Novel Cognitive Diagnosis Models via Evolutionary Multi-Objective Neural Architecture Search
Jul 10, 2023



Cognitive diagnosis plays a vital role in modern intelligent education platforms to reveal students' proficiency in knowledge concepts for subsequent adaptive tasks. However, due to the requirement of high model interpretability, existing manually designed cognitive diagnosis models hold too simple architectures to meet the demand of current intelligent education systems, where the bias of human design also limits the emergence of effective cognitive diagnosis models. In this paper, we propose to automatically design novel cognitive diagnosis models by evolutionary multi-objective neural architecture search (NAS). Specifically, we observe existing models can be represented by a general model handling three given types of inputs and thus first design an expressive search space for the NAS task in cognitive diagnosis. Then, we propose multi-objective genetic programming (MOGP) to explore the NAS task's search space by maximizing model performance and interpretability. In the MOGP design, each architecture is transformed into a tree architecture and encoded by a tree for easy optimization, and a tailored genetic operation based on four sub-genetic operations is devised to generate offspring effectively. Besides, an initialization strategy is also suggested to accelerate the convergence by evolving half of the population from existing models' variants. Experiments on two real-world datasets demonstrate that the cognitive diagnosis models searched by the proposed approach exhibit significantly better performance than existing models and also hold as good interpretability as human-designed models.
CelebA-Spoof Challenge 2020 on Face Anti-Spoofing: Methods and Results
Feb 26, 2021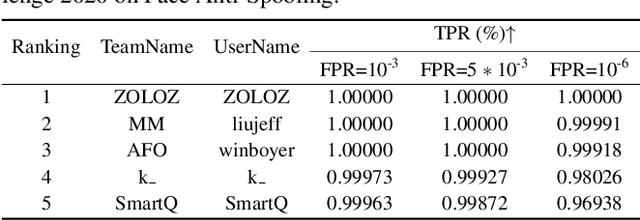
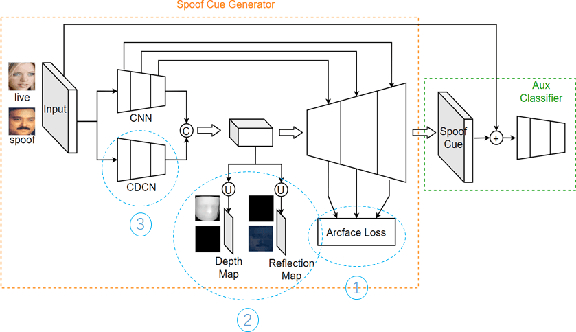
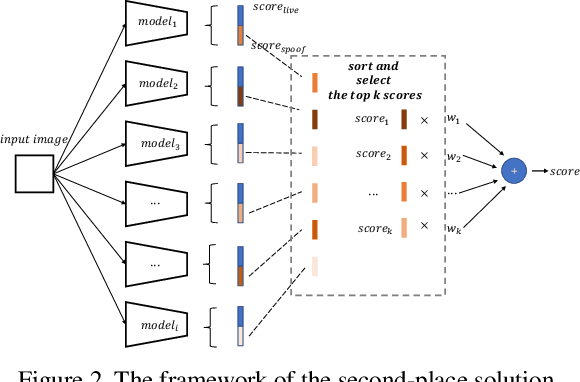
As facial interaction systems are prevalently deployed, security and reliability of these systems become a critical issue, with substantial research efforts devoted. Among them, face anti-spoofing emerges as an important area, whose objective is to identify whether a presented face is live or spoof. Recently, a large-scale face anti-spoofing dataset, CelebA-Spoof which comprised of 625,537 pictures of 10,177 subjects has been released. It is the largest face anti-spoofing dataset in terms of the numbers of the data and the subjects. This paper reports methods and results in the CelebA-Spoof Challenge 2020 on Face AntiSpoofing which employs the CelebA-Spoof dataset. The model evaluation is conducted online on the hidden test set. A total of 134 participants registered for the competition, and 19 teams made valid submissions. We will analyze the top ranked solutions and present some discussion on future work directions.