 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Distributed and Quantized Algorithm for MPC-based Autonomous Vehicle Platooning Optimization
Jan 31, 2025Intelligent transportation systems have recently emerged to address the growing interest for safer, more efficient, and sustainable transportation solutions. In this direction, this paper presents distributed algorithms for control and optimization over vehicular networks. First, we formulate the autonomous vehicle platooning framework based on model-predictive-control (MPC) strategies and present its objective optimization as a cooperative quadratic cost function. Then, we propose a distributed algorithm to locally optimize this objective at every vehicle subject to data quantization over the communication network of vehicles. In contrast to most existing literature that assumes ideal communication channels, log-scale data quantization over the network is addressed in this work, which is more realistic and practical. In particular, we show by simulation that the proposed log-quantized algorithm reaches optimal convergence with less residual and optimality gap. This outperforms the existing literature considering uniform quantization which leads to a large optimality gap and residual.
Laplace-HDC: Understanding the geometry of binary hyperdimensional computing
Apr 16, 2024This paper studies the geometry of binary hyperdimensional computing (HDC), a computational scheme in which data are encoded using high-dimensional binary vectors. We establish a result about the similarity structure induced by the HDC binding operator and show that the Laplace kernel naturally arises in this setting, motivating our new encoding method Laplace-HDC, which improves upon previous methods. We describe how our results indicate limitations of binary HDC in encoding spatial information from images and discuss potential solutions, including using Haar convolutional features and the definition of a translation-equivariant HDC encoding. Several numerical experiments highlighting the improved accuracy of Laplace-HDC in contrast to alternative methods are presented. We also numerically study other aspects of the proposed framework such as robustness and the underlying translation-equivariant encoding.
Fully Zeroth-Order Bilevel Programming via Gaussian Smoothing
Mar 29, 2024In this paper, we study and analyze zeroth-order stochastic approximation algorithms for solving bilvel problems, when neither the upper/lower objective values, nor their unbiased gradient estimates are available. In particular, exploiting Stein's identity, we first use Gaussian smoothing to estimate first- and second-order partial derivatives of functions with two independent block of variables. We then used these estimates in the framework of a stochastic approximation algorithm for solving bilevel optimization problems and establish its non-asymptotic convergence analysis. To the best of our knowledge, this is the first time that sample complexity bounds are established for a fully stochastic zeroth-order bilevel optimization algorithm.
Certain and Approximately Certain Models for Statistical Learning
Mar 01, 2024



Real-world data is often incomplete and contains missing values. To train accurate models over real-world datasets, users need to spend a substantial amount of time and resources imputing and finding proper values for missing data items. In this paper, we demonstrate that it is possible to learn accurate models directly from data with missing values for certain training data and target models. We propose a unified approach for checking the necessity of data imputation to learn accurate models across various widely-used machine learning paradigms. We build efficient algorithms with theoretical guarantees to check this necessity and return accurate models in cases where imputation is unnecessary. Our extensive experiments indicate that our proposed algorithms significantly reduce the amount of time and effort needed for data imputation without imposing considerable computational overhead.
Accelerated Distributed Allocation
Jan 28, 2024

Distributed allocation finds applications in many scenarios including CPU scheduling, distributed energy resource management, and networked coverage control. In this paper, we propose a fast convergent optimization algorithm with a tunable rate using the signum function. The convergence rate of the proposed algorithm can be managed by changing two parameters. We prove convergence over uniformly-connected multi-agent networks. Therefore, the solution converges even if the network loses connectivity at some finite time intervals. The proposed algorithm is all-time feasible, implying that at any termination time of the algorithm, the resource-demand feasibility holds. This is in contrast to asymptotic feasibility in many dual formulation solutions (e.g., ADMM) that meet resource-demand feasibility over time and asymptotically.
Survey of Distributed Algorithms for Resource Allocation over Multi-Agent Systems
Jan 28, 2024Resource allocation and scheduling in multi-agent systems present challenges due to complex interactions and decentralization. This survey paper provides a comprehensive analysis of distributed algorithms for addressing the distributed resource allocation (DRA) problem over multi-agent systems. It covers a significant area of research at the intersection of optimization, multi-agent systems, and distributed consensus-based computing. The paper begins by presenting a mathematical formulation of the DRA problem, establishing a solid foundation for further exploration. Real-world applications of DRA in various domains are examined to underscore the importance of efficient resource allocation, and relevant distributed optimization formulations are presented. The survey then delves into existing solutions for DRA, encompassing linear, nonlinear, primal-based, and dual-formulation-based approaches. Furthermore, this paper evaluates the features and properties of DRA algorithms, addressing key aspects such as feasibility, convergence rate, and network reliability. The analysis of mathematical foundations, diverse applications, existing solutions, and algorithmic properties contributes to a broader comprehension of the challenges and potential solutions for this domain.
Robust-to-Noise Algorithms for Distributed Resource Allocation and Scheduling
Nov 30, 2023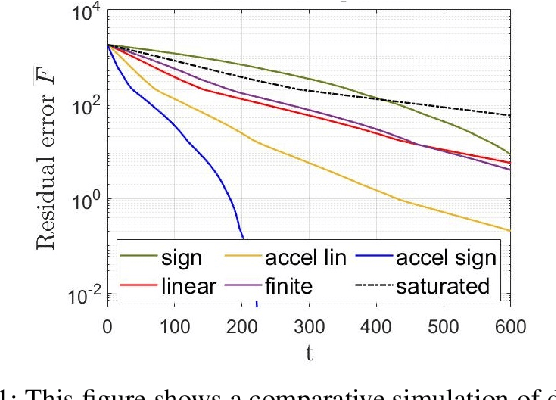
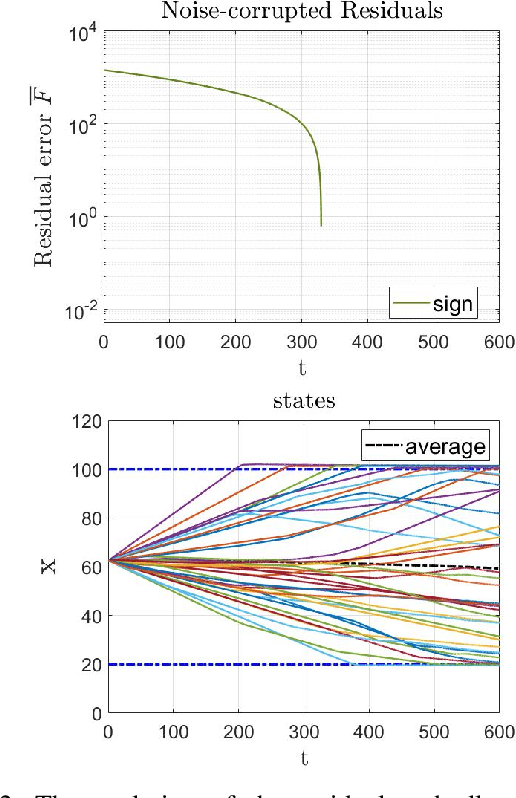
Efficient resource allocation and scheduling algorithms are essential for various distributed applications, ranging from wireless networks and cloud computing platforms to autonomous multi-agent systems and swarm robotic networks. However, real-world environments are often plagued by uncertainties and noise, leading to sub-optimal performance and increased vulnerability of traditional algorithms. This paper addresses the challenge of robust resource allocation and scheduling in the presence of noise and disturbances. The proposed study introduces a novel sign-based dynamics for developing robust-to-noise algorithms distributed over a multi-agent network that can adaptively handle external disturbances. Leveraging concepts from convex optimization theory, control theory, and network science the framework establishes a principled approach to design algorithms that can maintain key properties such as resource-demand balance and constraint feasibility. Meanwhile, notions of uniform-connectivity and versatile networking conditions are also addressed.
Discretized Distributed Optimization over Dynamic Digraphs
Nov 14, 2023We consider a discrete-time model of continuous-time distributed optimization over dynamic directed-graphs (digraphs) with applications to distributed learning. Our optimization algorithm works over general strongly connected dynamic networks under switching topologies, e.g., in mobile multi-agent systems and volatile networks due to link failures. Compared to many existing lines of work, there is no need for bi-stochastic weight designs on the links. The existing literature mostly needs the link weights to be stochastic using specific weight-design algorithms needed both at the initialization and at all times when the topology of the network changes. This paper eliminates the need for such algorithms and paves the way for distributed optimization over time-varying digraphs. We derive the bound on the gradient-tracking step-size and discrete time-step for convergence and prove dynamic stability using arguments from consensus algorithms, matrix perturbation theory, and Lyapunov theory. This work, particularly, is an improvement over existing stochastic-weight undirected networks in case of link removal or packet drops. This is because the existing literature may need to rerun time-consuming and computationally complex algorithms for stochastic design, while the proposed strategy works as long as the underlying network is weight-symmetric and balanced. The proposed optimization framework finds applications to distributed classification and learning.
D-SVM over Networked Systems with Non-Ideal Linking Conditions
Apr 13, 2023This paper considers distributed optimization algorithms, with application in binary classification via distributed support-vector-machines (D-SVM) over multi-agent networks subject to some link nonlinearities. The agents solve a consensus-constraint distributed optimization cooperatively via continuous-time dynamics, while the links are subject to strongly sign-preserving odd nonlinear conditions. Logarithmic quantization and clipping (saturation) are two examples of such nonlinearities. In contrast to existing literature that mostly considers ideal links and perfect information exchange over linear channels, we show how general sector-bounded models affect the convergence to the optimizer (i.e., the SVM classifier) over dynamic balanced directed networks. In general, any odd sector-bounded nonlinear mapping can be applied to our dynamics. The main challenge is to show that the proposed system dynamics always have one zero eigenvalue (associated with the consensus) and the other eigenvalues all have negative real parts. This is done by recalling arguments from matrix perturbation theory. Then, the solution is shown to converge to the agreement state under certain conditions. For example, the gradient tracking (GT) step size is tighter than the linear case by factors related to the upper/lower sector bounds. To the best of our knowledge, no existing work in distributed optimization and learning literature considers non-ideal link conditions.
RIGID: Robust Linear Regression with Missing Data
May 26, 2022


We present a robust framework to perform linear regression with missing entries in the features. By considering an elliptical data distribution, and specifically a multivariate normal model, we are able to conditionally formulate a distribution for the missing entries and present a robust framework, which minimizes the worst case error caused by the uncertainty about the missing data. We show that the proposed formulation, which naturally takes into account the dependency between different variables, ultimately reduces to a convex program, for which a customized and scalable solver can be delivered. In addition to a detailed analysis to deliver such solver, we also asymptoticly analyze the behavior of the proposed framework, and present technical discussions to estimate the required input parameters. We complement our analysis with experiments performed on synthetic, semi-synthetic, and real data, and show how the proposed formulation improves the prediction accuracy and robustness, and outperforms the competing techniques.