 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Tail-dropping for Adaptive Visual Tokenization
Jan 20, 2026We present Soft Tail-dropping Adaptive Tokenizer (STAT), a 1D discrete visual tokenizer that adaptively chooses the number of output tokens per image according to its structural complexity and level of detail. STAT encodes an image into a sequence of discrete codes together with per-token keep probabilities. Beyond standard autoencoder objectives, we regularize these keep probabilities to be monotonically decreasing along the sequence and explicitly align their distribution with an image-level complexity measure. As a result, STAT produces length-adaptive 1D visual tokens that are naturally compatible with causal 1D autoregressive (AR) visual generative models. On ImageNet-1k, equipping vanilla causal AR models with STAT yields competitive or superior visual generation quality compared to other probabilistic model families, while also exhibiting favorable scaling behavior that has been elusive in prior vanilla AR visual generation attempts.
X-Prompt: Towards Universal In-Context Image Generation in Auto-Regressive Vision Language Foundation Models
Dec 02, 2024



In-context generation is a key component of large language models' (LLMs) open-task generalization capability. By leveraging a few examples as context, LLMs can perform both in-domain and out-of-domain tasks. Recent advancements in auto-regressive vision-language models (VLMs) built upon LLMs have showcased impressive performance in text-to-image generation. However, the potential of in-context learning for general image generation tasks remains largely unexplored. To address this, we introduce X-Prompt, a purely auto-regressive large-vision language model designed to deliver competitive performance across a wide range of both seen and unseen image generation tasks, all within a unified in-context learning framework. X-Prompt incorporates a specialized design that efficiently compresses valuable features from in-context examples, supporting longer in-context token sequences and improving its ability to generalize to unseen tasks. A unified training task for both text and image prediction enables X-Prompt to handle general image generation with enhanced task awareness from in-context examples. Extensive experiments validate the model's performance across diverse seen image generation tasks and its capacity to generalize to previously unseen tasks.
MIA-DPO: Multi-Image Augmented Direct Preference Optimization For Large Vision-Language Models
Oct 23, 2024



Visual preference alignment involves training Large Vision-Language Models (LVLMs) to predict human preferences between visual inputs. This is typically achieved by using labeled datasets of chosen/rejected pairs and employing optimization algorithms like direct preference optimization (DPO). Existing visual alignment methods, primarily designed for single-image scenarios, struggle to effectively handle the complexity of multi-image tasks due to the scarcity of diverse training data and the high cost of annotating chosen/rejected pairs. We present Multi-Image Augmented Direct Preference Optimization (MIA-DPO), a visual preference alignment approach that effectively handles multi-image inputs. MIA-DPO mitigates the scarcity of diverse multi-image training data by extending single-image data with unrelated images arranged in grid collages or pic-in-pic formats, significantly reducing the costs associated with multi-image data annotations. Our observation reveals that attention values of LVLMs vary considerably across different images. We use attention values to identify and filter out rejected responses the model may have mistakenly focused on. Our attention-aware selection for constructing the chosen/rejected pairs without relying on (i) human annotation, (ii) extra data, and (iii) external models or APIs. MIA-DPO is compatible with various architectures and outperforms existing methods on five multi-image benchmarks, achieving an average performance boost of 3.0% on LLaVA-v1.5 and 4.3% on the recent InternLM-XC2.5. Moreover, MIA-DPO has a minimal effect on the model's ability to understand single images.
MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs
Jun 17, 2024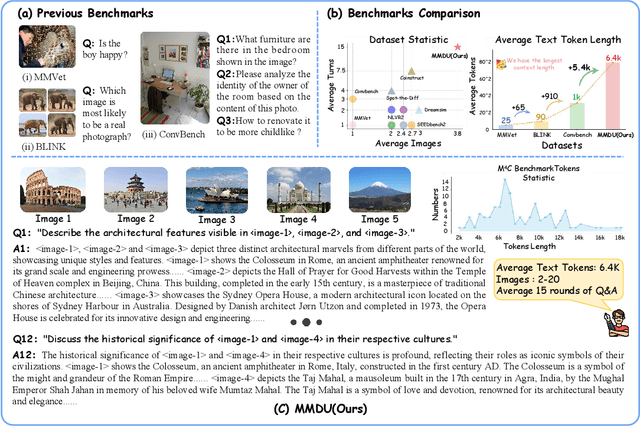
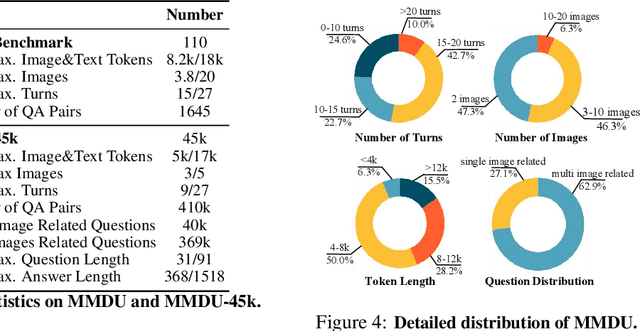
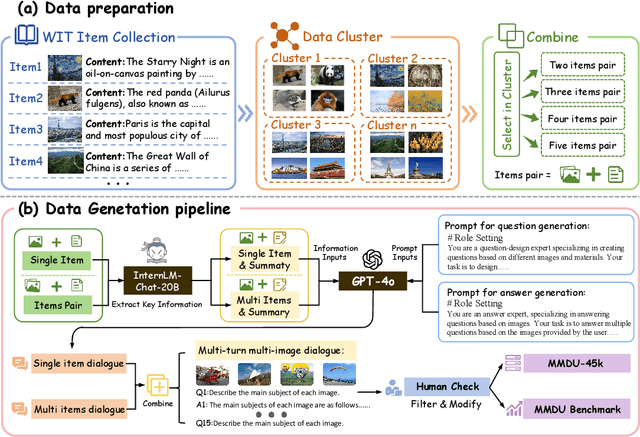

Generating natural and meaningful responses to communicate with multi-modal human inputs is a fundamental capability of Large Vision-Language Models(LVLMs). While current open-source LVLMs demonstrate promising performance in simplified scenarios such as single-turn single-image input, they fall short in real-world conversation scenarios such as following instructions in a long context history with multi-turn and multi-images. Existing LVLM benchmarks primarily focus on single-choice questions or short-form responses, which do not adequately assess the capabilities of LVLMs in real-world human-AI interaction applications. Therefore, we introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs' abilities in multi-turn and multi-image conversations. We employ the clustering algorithm to ffnd the relevant images and textual descriptions from the open-source Wikipedia and construct the question-answer pairs by human annotators with the assistance of the GPT-4o model. MMDU has a maximum of 18k image+text tokens, 20 images, and 27 turns, which is at least 5x longer than previous benchmarks and poses challenges to current LVLMs. Our in-depth analysis of 15 representative LVLMs using MMDU reveals that open-source LVLMs lag behind closed-source counterparts due to limited conversational instruction tuning data. We demonstrate that ffne-tuning open-source LVLMs on MMDU-45k signiffcantly address this gap, generating longer and more accurate conversations, and improving scores on MMDU and existing benchmarks (MMStar: +1.1%, MathVista: +1.5%, ChartQA:+1.2%). Our contributions pave the way for bridging the gap between current LVLM models and real-world application demands. This project is available at https://github.com/Liuziyu77/MMDU.
RetinaGS: Scalable Training for Dense Scene Rendering with Billion-Scale 3D Gaussians
Jun 17, 2024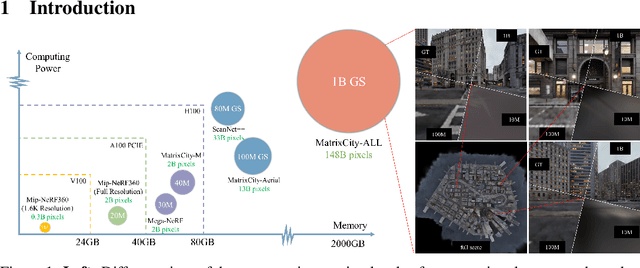


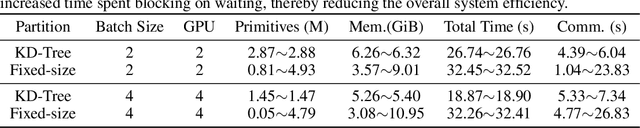
In this work, we explore the possibility of training high-parameter 3D Gaussian splatting (3DGS) models on large-scale, high-resolution datasets. We design a general model parallel training method for 3DGS, named RetinaGS, which uses a proper rendering equation and can be applied to any scene and arbitrary distribution of Gaussian primitives. It enables us to explore the scaling behavior of 3DGS in terms of primitive numbers and training resolutions that were difficult to explore before and surpass previous state-of-the-art reconstruction quality. We observe a clear positive trend of increasing visual quality when increasing primitive numbers with our method. We also demonstrate the first attempt at training a 3DGS model with more than one billion primitives on the full MatrixCity dataset that attains a promising visual quality.
Image and Video Tokenization with Binary Spherical Quantization
Jun 11, 2024We propose a new transformer-based image and video tokenizer with Binary Spherical Quantization (BSQ). BSQ projects the high-dimensional visual embedding to a lower-dimensional hypersphere and then applies binary quantization. BSQ is (1) parameter-efficient without an explicit codebook, (2) scalable to arbitrary token dimensions, and (3) compact: compressing visual data by up to 100$\times$ with minimal distortion. Our tokenizer uses a transformer encoder and decoder with simple block-wise causal masking to support variable-length videos as input. The resulting BSQ-ViT achieves state-of-the-art visual reconstruction quality on image and video reconstruction benchmarks with 2.4$\times$ throughput compared to the best prior methods. Furthermore, by learning an autoregressive prior for adaptive arithmetic coding, BSQ-ViT achieves comparable results on video compression with state-of-the-art video compression standards. BSQ-ViT also enables masked language models to achieve competitive image synthesis quality to GAN- and diffusion-based methods.
Bootstrap3D: Improving 3D Content Creation with Synthetic Data
May 31, 2024



Recent years have witnessed remarkable progress in multi-view diffusion models for 3D content creation. However, there remains a significant gap in image quality and prompt-following ability compared to 2D diffusion models. A critical bottleneck is the scarcity of high-quality 3D assets with detailed captions. To address this challenge, we propose Bootstrap3D, a novel framework that automatically generates an arbitrary quantity of multi-view images to assist in training multi-view diffusion models. Specifically, we introduce a data generation pipeline that employs (1) 2D and video diffusion models to generate multi-view images based on constructed text prompts, and (2) our fine-tuned 3D-aware MV-LLaVA for filtering high-quality data and rewriting inaccurate captions. Leveraging this pipeline, we have generated 1 million high-quality synthetic multi-view images with dense descriptive captions to address the shortage of high-quality 3D data. Furthermore, we present a Training Timestep Reschedule (TTR) strategy that leverages the denoising process to learn multi-view consistency while maintaining the original 2D diffusion prior. Extensive experiments demonstrate that Bootstrap3D can generate high-quality multi-view images with superior aesthetic quality, image-text alignment, and maintained view consistency.
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
May 29, 2024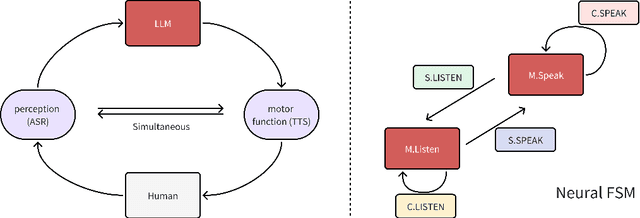


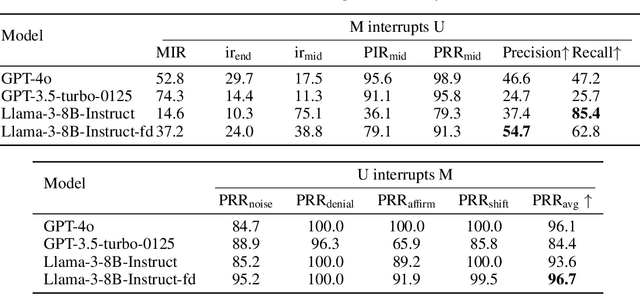
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
RAR: Retrieving And Ranking Augmented MLLMs for Visual Recognition
Mar 20, 2024



CLIP (Contrastive Language-Image Pre-training) uses contrastive learning from noise image-text pairs to excel at recognizing a wide array of candidates, yet its focus on broad associations hinders the precision in distinguishing subtle differences among fine-grained items. Conversely, Multimodal Large Language Models (MLLMs) excel at classifying fine-grained categories, thanks to their substantial knowledge from pre-training on web-level corpora. However, the performance of MLLMs declines with an increase in category numbers, primarily due to growing complexity and constraints of limited context window size. To synergize the strengths of both approaches and enhance the few-shot/zero-shot recognition abilities for datasets characterized by extensive and fine-grained vocabularies, this paper introduces RAR, a Retrieving And Ranking augmented method for MLLMs. We initially establish a multi-modal retriever based on CLIP to create and store explicit memory for different categories beyond the immediate context window. During inference, RAR retrieves the top-k similar results from the memory and uses MLLMs to rank and make the final predictions. Our proposed approach not only addresses the inherent limitations in fine-grained recognition but also preserves the model's comprehensive knowledge base, significantly boosting accuracy across a range of vision-language recognition tasks. Notably, our approach demonstrates a significant improvement in performance on 5 fine-grained visual recognition benchmarks, 11 few-shot image recognition datasets, and the 2 object detection datasets under the zero-shot recognition setting.
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Dec 13, 2023Contrastive Language-Image Pre-training (CLIP) plays an essential role in extracting valuable content information from images across diverse tasks. It aligns textual and visual modalities to comprehend the entire image, including all the details, even those irrelevant to specific tasks. However, for a finer understanding and controlled editing of images, it becomes crucial to focus on specific regions of interest, which can be indicated as points, masks, or boxes by humans or perception models. To fulfill the requirements, we introduce Alpha-CLIP, an enhanced version of CLIP with an auxiliary alpha channel to suggest attentive regions and fine-tuned with constructed millions of RGBA region-text pairs. Alpha-CLIP not only preserves the visual recognition ability of CLIP but also enables precise control over the emphasis of image contents. It demonstrates effectiveness in various tasks, including but not limited to open-world recognition, multimodal large language models, and conditional 2D / 3D generation. It has a strong potential to serve as a versatile tool for image-related tasks.