 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Dec 12, 2025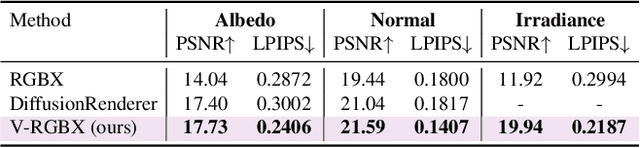
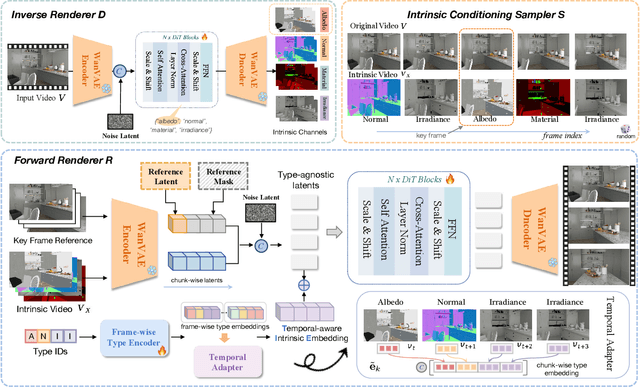
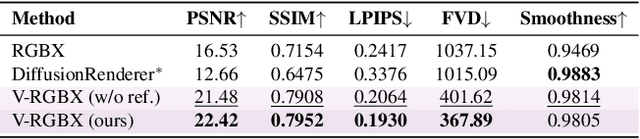

Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.
RelightVid: Temporal-Consistent Diffusion Model for Video Relighting
Jan 27, 2025Diffusion models have demonstrated remarkable success in image generation and editing, with recent advancements enabling albedo-preserving image relighting. However, applying these models to video relighting remains challenging due to the lack of paired video relighting datasets and the high demands for output fidelity and temporal consistency, further complicated by the inherent randomness of diffusion models. To address these challenges, we introduce RelightVid, a flexible framework for video relighting that can accept background video, text prompts, or environment maps as relighting conditions. Trained on in-the-wild videos with carefully designed illumination augmentations and rendered videos under extreme dynamic lighting, RelightVid achieves arbitrary video relighting with high temporal consistency without intrinsic decomposition while preserving the illumination priors of its image backbone.
GPT4Scene: Understand 3D Scenes from Videos with Vision-Language Models
Jan 03, 2025



In recent years, 2D Vision-Language Models (VLMs) have made significant strides in image-text understanding tasks. However, their performance in 3D spatial comprehension, which is critical for embodied intelligence, remains limited. Recent advances have leveraged 3D point clouds and multi-view images as inputs, yielding promising results. However, we propose exploring a purely vision-based solution inspired by human perception, which merely relies on visual cues for 3D spatial understanding. This paper empirically investigates the limitations of VLMs in 3D spatial knowledge, revealing that their primary shortcoming lies in the lack of global-local correspondence between the scene and individual frames. To address this, we introduce GPT4Scene, a novel visual prompting paradigm in VLM training and inference that helps build the global-local relationship, significantly improving the 3D spatial understanding of indoor scenes. Specifically, GPT4Scene constructs a 3D Bird's Eye View (BEV) image from the video and marks consistent object IDs across both frames and the BEV image. The model then inputs the concatenated BEV image and video frames with markers. In zero-shot evaluations, GPT4Scene improves performance over closed-source VLMs like GPT-4o. Additionally, we prepare a processed video dataset consisting of 165K text annotation to fine-tune open-source VLMs, achieving state-of-the-art performance on all 3D understanding tasks. Surprisingly, after training with the GPT4Scene paradigm, VLMs consistently improve during inference, even without visual prompting and BEV image as explicit correspondence. It demonstrates that the proposed paradigm helps VLMs develop an intrinsic ability to understand 3D scenes, which paves the way for a noninvasive approach to extending pre-trained VLMs for 3D scene understanding.
Make-it-Real: Unleashing Large Multimodal Model's Ability for Painting 3D Objects with Realistic Materials
Apr 29, 2024



Physically realistic materials are pivotal in augmenting the realism of 3D assets across various applications and lighting conditions. However, existing 3D assets and generative models often lack authentic material properties. Manual assignment of materials using graphic software is a tedious and time-consuming task. In this paper, we exploit advancements in Multimodal Large Language Models (MLLMs), particularly GPT-4V, to present a novel approach, Make-it-Real: 1) We demonstrate that GPT-4V can effectively recognize and describe materials, allowing the construction of a detailed material library. 2) Utilizing a combination of visual cues and hierarchical text prompts, GPT-4V precisely identifies and aligns materials with the corresponding components of 3D objects. 3) The correctly matched materials are then meticulously applied as reference for the new SVBRDF material generation according to the original diffuse map, significantly enhancing their visual authenticity. Make-it-Real offers a streamlined integration into the 3D content creation workflow, showcasing its utility as an essential tool for developers of 3D assets.
Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases
Dec 22, 2023The rapidly evolving sector of Multi-modal Large Language Models (MLLMs) is at the forefront of integrating linguistic and visual processing in artificial intelligence. This paper presents an in-depth comparative study of two pioneering models: Google's Gemini and OpenAI's GPT-4V(ision). Our study involves a multi-faceted evaluation of both models across key dimensions such as Vision-Language Capability, Interaction with Humans, Temporal Understanding, and assessments in both Intelligence and Emotional Quotients. The core of our analysis delves into the distinct visual comprehension abilities of each model. We conducted a series of structured experiments to evaluate their performance in various industrial application scenarios, offering a comprehensive perspective on their practical utility. We not only involve direct performance comparisons but also include adjustments in prompts and scenarios to ensure a balanced and fair analysis. Our findings illuminate the unique strengths and niches of both models. GPT-4V distinguishes itself with its precision and succinctness in responses, while Gemini excels in providing detailed, expansive answers accompanied by relevant imagery and links. These understandings not only shed light on the comparative merits of Gemini and GPT-4V but also underscore the evolving landscape of multimodal foundation models, paving the way for future advancements in this area. After the comparison, we attempted to achieve better results by combining the two models. Finally, We would like to express our profound gratitude to the teams behind GPT-4V and Gemini for their pioneering contributions to the field. Our acknowledgments are also extended to the comprehensive qualitative analysis presented in 'Dawn' by Yang et al. This work, with its extensive collection of image samples, prompts, and GPT-4V-related results, provided a foundational basis for our analysis.
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Dec 13, 2023Contrastive Language-Image Pre-training (CLIP) plays an essential role in extracting valuable content information from images across diverse tasks. It aligns textual and visual modalities to comprehend the entire image, including all the details, even those irrelevant to specific tasks. However, for a finer understanding and controlled editing of images, it becomes crucial to focus on specific regions of interest, which can be indicated as points, masks, or boxes by humans or perception models. To fulfill the requirements, we introduce Alpha-CLIP, an enhanced version of CLIP with an auxiliary alpha channel to suggest attentive regions and fine-tuned with constructed millions of RGBA region-text pairs. Alpha-CLIP not only preserves the visual recognition ability of CLIP but also enables precise control over the emphasis of image contents. It demonstrates effectiveness in various tasks, including but not limited to open-world recognition, multimodal large language models, and conditional 2D / 3D generation. It has a strong potential to serve as a versatile tool for image-related tasks.
GPT4Point: A Unified Framework for Point-Language Understanding and Generation
Dec 05, 2023Multimodal Large Language Models (MLLMs) have excelled in 2D image-text comprehension and image generation, but their understanding of the 3D world is notably deficient, limiting progress in 3D language understanding and generation. To solve this problem, we introduce GPT4Point, an innovative groundbreaking point-language multimodal model designed specifically for unified 3D object understanding and generation within the MLLM framework. GPT4Point as a powerful 3D MLLM seamlessly can execute a variety of point-text reference tasks such as point-cloud captioning and Q&A. Additionally, GPT4Point is equipped with advanced capabilities for controllable 3D generation, it can get high-quality results through a low-quality point-text feature maintaining the geometric shapes and colors. To support the expansive needs of 3D object-text pairs, we develop Pyramid-XL, a point-language dataset annotation engine. It constructs a large-scale database over 1M objects of varied text granularity levels from the Objaverse-XL dataset, essential for training GPT4Point. A comprehensive benchmark has been proposed to evaluate 3D point-language understanding capabilities. In extensive evaluations, GPT4Point has demonstrated superior performance in understanding and generation.