 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT4Scene: Understand 3D Scenes from Videos with Vision-Language Models
Jan 03, 2025



In recent years, 2D Vision-Language Models (VLMs) have made significant strides in image-text understanding tasks. However, their performance in 3D spatial comprehension, which is critical for embodied intelligence, remains limited. Recent advances have leveraged 3D point clouds and multi-view images as inputs, yielding promising results. However, we propose exploring a purely vision-based solution inspired by human perception, which merely relies on visual cues for 3D spatial understanding. This paper empirically investigates the limitations of VLMs in 3D spatial knowledge, revealing that their primary shortcoming lies in the lack of global-local correspondence between the scene and individual frames. To address this, we introduce GPT4Scene, a novel visual prompting paradigm in VLM training and inference that helps build the global-local relationship, significantly improving the 3D spatial understanding of indoor scenes. Specifically, GPT4Scene constructs a 3D Bird's Eye View (BEV) image from the video and marks consistent object IDs across both frames and the BEV image. The model then inputs the concatenated BEV image and video frames with markers. In zero-shot evaluations, GPT4Scene improves performance over closed-source VLMs like GPT-4o. Additionally, we prepare a processed video dataset consisting of 165K text annotation to fine-tune open-source VLMs, achieving state-of-the-art performance on all 3D understanding tasks. Surprisingly, after training with the GPT4Scene paradigm, VLMs consistently improve during inference, even without visual prompting and BEV image as explicit correspondence. It demonstrates that the proposed paradigm helps VLMs develop an intrinsic ability to understand 3D scenes, which paves the way for a noninvasive approach to extending pre-trained VLMs for 3D scene understanding.
Tailor3D: Customized 3D Assets Editing and Generation with Dual-Side Images
Jul 08, 2024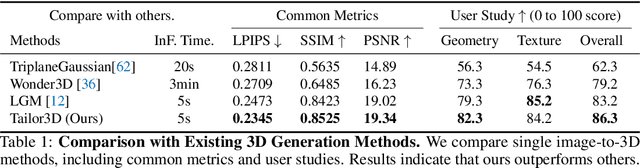
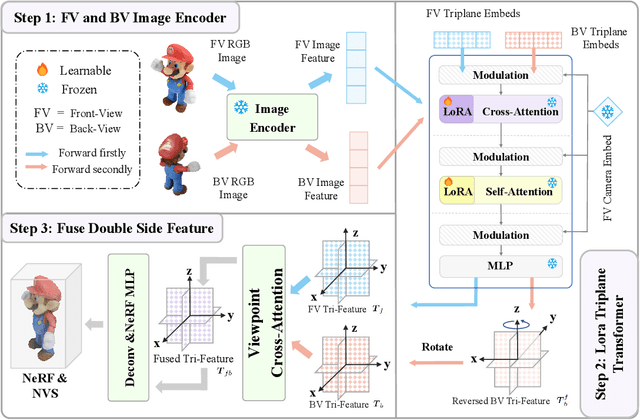
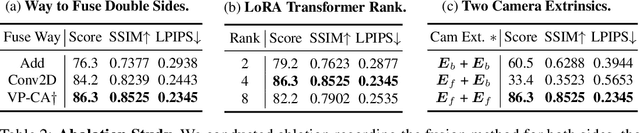
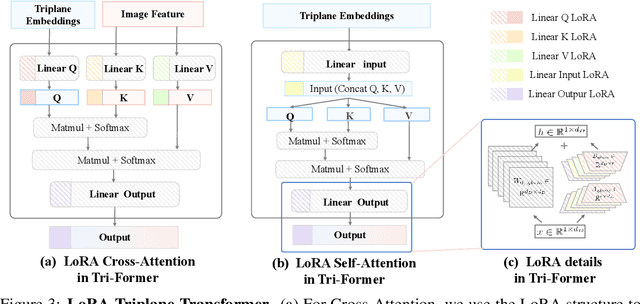
Recent advances in 3D AIGC have shown promise in directly creating 3D objects from text and images, offering significant cost savings in animation and product design. However, detailed edit and customization of 3D assets remains a long-standing challenge. Specifically, 3D Generation methods lack the ability to follow finely detailed instructions as precisely as their 2D image creation counterparts. Imagine you can get a toy through 3D AIGC but with undesired accessories and dressing. To tackle this challenge, we propose a novel pipeline called Tailor3D, which swiftly creates customized 3D assets from editable dual-side images. We aim to emulate a tailor's ability to locally change objects or perform overall style transfer. Unlike creating 3D assets from multiple views, using dual-side images eliminates conflicts on overlapping areas that occur when editing individual views. Specifically, it begins by editing the front view, then generates the back view of the object through multi-view diffusion. Afterward, it proceeds to edit the back views. Finally, a Dual-sided LRM is proposed to seamlessly stitch together the front and back 3D features, akin to a tailor sewing together the front and back of a garment. The Dual-sided LRM rectifies imperfect consistencies between the front and back views, enhancing editing capabilities and reducing memory burdens while seamlessly integrating them into a unified 3D representation with the LoRA Triplane Transformer. Experimental results demonstrate Tailor3D's effectiveness across various 3D generation and editing tasks, including 3D generative fill and style transfer. It provides a user-friendly, efficient solution for editing 3D assets, with each editing step taking only seconds to complete.
Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases
Dec 22, 2023The rapidly evolving sector of Multi-modal Large Language Models (MLLMs) is at the forefront of integrating linguistic and visual processing in artificial intelligence. This paper presents an in-depth comparative study of two pioneering models: Google's Gemini and OpenAI's GPT-4V(ision). Our study involves a multi-faceted evaluation of both models across key dimensions such as Vision-Language Capability, Interaction with Humans, Temporal Understanding, and assessments in both Intelligence and Emotional Quotients. The core of our analysis delves into the distinct visual comprehension abilities of each model. We conducted a series of structured experiments to evaluate their performance in various industrial application scenarios, offering a comprehensive perspective on their practical utility. We not only involve direct performance comparisons but also include adjustments in prompts and scenarios to ensure a balanced and fair analysis. Our findings illuminate the unique strengths and niches of both models. GPT-4V distinguishes itself with its precision and succinctness in responses, while Gemini excels in providing detailed, expansive answers accompanied by relevant imagery and links. These understandings not only shed light on the comparative merits of Gemini and GPT-4V but also underscore the evolving landscape of multimodal foundation models, paving the way for future advancements in this area. After the comparison, we attempted to achieve better results by combining the two models. Finally, We would like to express our profound gratitude to the teams behind GPT-4V and Gemini for their pioneering contributions to the field. Our acknowledgments are also extended to the comprehensive qualitative analysis presented in 'Dawn' by Yang et al. This work, with its extensive collection of image samples, prompts, and GPT-4V-related results, provided a foundational basis for our analysis.
GPT4Point: A Unified Framework for Point-Language Understanding and Generation
Dec 05, 2023Multimodal Large Language Models (MLLMs) have excelled in 2D image-text comprehension and image generation, but their understanding of the 3D world is notably deficient, limiting progress in 3D language understanding and generation. To solve this problem, we introduce GPT4Point, an innovative groundbreaking point-language multimodal model designed specifically for unified 3D object understanding and generation within the MLLM framework. GPT4Point as a powerful 3D MLLM seamlessly can execute a variety of point-text reference tasks such as point-cloud captioning and Q&A. Additionally, GPT4Point is equipped with advanced capabilities for controllable 3D generation, it can get high-quality results through a low-quality point-text feature maintaining the geometric shapes and colors. To support the expansive needs of 3D object-text pairs, we develop Pyramid-XL, a point-language dataset annotation engine. It constructs a large-scale database over 1M objects of varied text granularity levels from the Objaverse-XL dataset, essential for training GPT4Point. A comprehensive benchmark has been proposed to evaluate 3D point-language understanding capabilities. In extensive evaluations, GPT4Point has demonstrated superior performance in understanding and generation.
OCBEV: Object-Centric BEV Transformer for Multi-View 3D Object Detection
Jun 02, 2023Multi-view 3D object detection is becoming popular in autonomous driving due to its high effectiveness and low cost. Most of the current state-of-the-art detectors follow the query-based bird's-eye-view (BEV) paradigm, which benefits from both BEV's strong perception power and end-to-end pipeline. Despite achieving substantial progress, existing works model objects via globally leveraging temporal and spatial information of BEV features, resulting in problems when handling the challenging complex and dynamic autonomous driving scenarios. In this paper, we proposed an Object-Centric query-BEV detector OCBEV, which can carve the temporal and spatial cues of moving targets more effectively. OCBEV comprises three designs: Object Aligned Temporal Fusion aligns the BEV feature based on ego-motion and estimated current locations of moving objects, leading to a precise instance-level feature fusion. Object Focused Multi-View Sampling samples more 3D features from an adaptive local height ranges of objects for each scene to enrich foreground information. Object Informed Query Enhancement replaces part of pre-defined decoder queries in common DETR-style decoders with positional features of objects on high-confidence locations, introducing more direct object positional priors. Extensive experimental evaluations are conducted on the challenging nuScenes dataset. Our approach achieves a state-of-the-art result, surpassing the traditional BEVFormer by 1.5 NDS points. Moreover, we have a faster convergence speed and only need half of the training iterations to get comparable performance, which further demonstrates its effectiveness.