 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny3D-VLA: Enhancing VLA Robustness via Diverse Point Clouds
Jan 31, 2026Existing Vision-Language-Action (VLA) models typically take 2D images as visual input, which limits their spatial understanding in complex scenes. How can we incorporate 3D information to enhance VLA capabilities? We conduct a pilot study across different observation spaces and visual representations. The results show that explicitly lifting visual input into point clouds yields representations that better complement their corresponding 2D representations. To address the challenges of (1) scarce 3D data and (2) the domain gap induced by cross-environment differences and depth-scale biases, we propose Any3D-VLA. It unifies the simulator, sensor, and model-estimated point clouds within a training pipeline, constructs diverse inputs, and learns domain-agnostic 3D representations that are fused with the corresponding 2D representations. Simulation and real-world experiments demonstrate Any3D-VLA's advantages in improving performance and mitigating the domain gap. Our project homepage is available at https://xianzhefan.github.io/Any3D-VLA.github.io.
CoDance: An Unbind-Rebind Paradigm for Robust Multi-Subject Animation
Jan 16, 2026Character image animation is gaining significant importance across various domains, driven by the demand for robust and flexible multi-subject rendering. While existing methods excel in single-person animation, they struggle to handle arbitrary subject counts, diverse character types, and spatial misalignment between the reference image and the driving poses. We attribute these limitations to an overly rigid spatial binding that forces strict pixel-wise alignment between the pose and reference, and an inability to consistently rebind motion to intended subjects. To address these challenges, we propose CoDance, a novel Unbind-Rebind framework that enables the animation of arbitrary subject counts, types, and spatial configurations conditioned on a single, potentially misaligned pose sequence. Specifically, the Unbind module employs a novel pose shift encoder to break the rigid spatial binding between the pose and the reference by introducing stochastic perturbations to both poses and their latent features, thereby compelling the model to learn a location-agnostic motion representation. To ensure precise control and subject association, we then devise a Rebind module, leveraging semantic guidance from text prompts and spatial guidance from subject masks to direct the learned motion to intended characters. Furthermore, to facilitate comprehensive evaluation, we introduce a new multi-subject CoDanceBench. Extensive experiments on CoDanceBench and existing datasets show that CoDance achieves SOTA performance, exhibiting remarkable generalization across diverse subjects and spatial layouts. The code and weights will be open-sourced.
GDRO: Group-level Reward Post-training Suitable for Diffusion Models
Jan 05, 2026Recent advancements adopt online reinforcement learning (RL) from LLMs to text-to-image rectified flow diffusion models for reward alignment. The use of group-level rewards successfully aligns the model with the targeted reward. However, it faces challenges including low efficiency, dependency on stochastic samplers, and reward hacking. The problem is that rectified flow models are fundamentally different from LLMs: 1) For efficiency, online image sampling takes much more time and dominates the time of training. 2) For stochasticity, rectified flow is deterministic once the initial noise is fixed. Aiming at these problems and inspired by the effects of group-level rewards from LLMs, we design Group-level Direct Reward Optimization (GDRO). GDRO is a new post-training paradigm for group-level reward alignment that combines the characteristics of rectified flow models. Through rigorous theoretical analysis, we point out that GDRO supports full offline training that saves the large time cost for image rollout sampling. Also, it is diffusion-sampler-independent, which eliminates the need for the ODE-to-SDE approximation to obtain stochasticity. We also empirically study the reward hacking trap that may mislead the evaluation, and involve this factor in the evaluation using a corrected score that not only considers the original evaluation reward but also the trend of reward hacking. Extensive experiments demonstrate that GDRO effectively and efficiently improves the reward score of the diffusion model through group-wise offline optimization across the OCR and GenEval tasks, while demonstrating strong stability and robustness in mitigating reward hacking.
Alchemist: Unlocking Efficiency in Text-to-Image Model Training via Meta-Gradient Data Selection
Dec 18, 2025Recent advances in Text-to-Image (T2I) generative models, such as Imagen, Stable Diffusion, and FLUX, have led to remarkable improvements in visual quality. However, their performance is fundamentally limited by the quality of training data. Web-crawled and synthetic image datasets often contain low-quality or redundant samples, which lead to degraded visual fidelity, unstable training, and inefficient computation. Hence, effective data selection is crucial for improving data efficiency. Existing approaches rely on costly manual curation or heuristic scoring based on single-dimensional features in Text-to-Image data filtering. Although meta-learning based method has been explored in LLM, there is no adaptation for image modalities. To this end, we propose **Alchemist**, a meta-gradient-based framework to select a suitable subset from large-scale text-image data pairs. Our approach automatically learns to assess the influence of each sample by iteratively optimizing the model from a data-centric perspective. Alchemist consists of two key stages: data rating and data pruning. We train a lightweight rater to estimate each sample's influence based on gradient information, enhanced with multi-granularity perception. We then use the Shift-Gsampling strategy to select informative subsets for efficient model training. Alchemist is the first automatic, scalable, meta-gradient-based data selection framework for Text-to-Image model training. Experiments on both synthetic and web-crawled datasets demonstrate that Alchemist consistently improves visual quality and downstream performance. Training on an Alchemist-selected 50% of the data can outperform training on the full dataset.
In Pursuit of Pixel Supervision for Visual Pre-training
Dec 17, 2025At the most basic level, pixels are the source of the visual information through which we perceive the world. Pixels contain information at all levels, ranging from low-level attributes to high-level concepts. Autoencoders represent a classical and long-standing paradigm for learning representations from pixels or other raw inputs. In this work, we demonstrate that autoencoder-based self-supervised learning remains competitive today and can produce strong representations for downstream tasks, while remaining simple, stable, and efficient. Our model, codenamed "Pixio", is an enhanced masked autoencoder (MAE) with more challenging pre-training tasks and more capable architectures. The model is trained on 2B web-crawled images with a self-curation strategy with minimal human curation. Pixio performs competitively across a wide range of downstream tasks in the wild, including monocular depth estimation (e.g., Depth Anything), feed-forward 3D reconstruction (i.e., MapAnything), semantic segmentation, and robot learning, outperforming or matching DINOv3 trained at similar scales. Our results suggest that pixel-space self-supervised learning can serve as a promising alternative and a complement to latent-space approaches.
MemFlow: Flowing Adaptive Memory for Consistent and Efficient Long Video Narratives
Dec 16, 2025The core challenge for streaming video generation is maintaining the content consistency in long context, which poses high requirement for the memory design. Most existing solutions maintain the memory by compressing historical frames with predefined strategies. However, different to-generate video chunks should refer to different historical cues, which is hard to satisfy with fixed strategies. In this work, we propose MemFlow to address this problem. Specifically, before generating the coming chunk, we dynamically update the memory bank by retrieving the most relevant historical frames with the text prompt of this chunk. This design enables narrative coherence even if new event happens or scenario switches in future frames. In addition, during generation, we only activate the most relevant tokens in the memory bank for each query in the attention layers, which effectively guarantees the generation efficiency. In this way, MemFlow achieves outstanding long-context consistency with negligible computation burden (7.9% speed reduction compared with the memory-free baseline) and keeps the compatibility with any streaming video generation model with KV cache.
DrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
Dec 14, 2025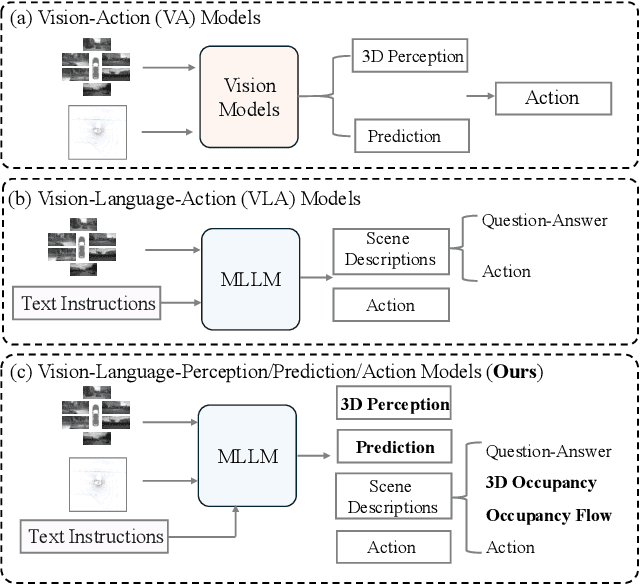
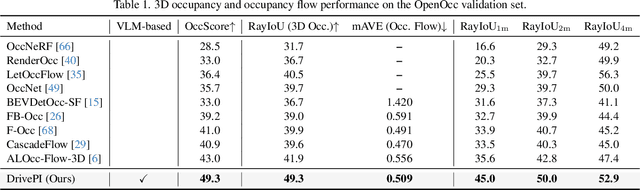
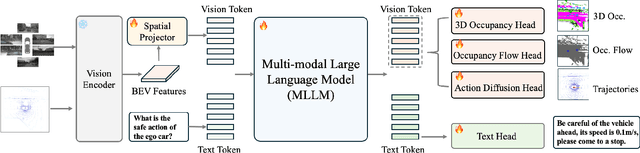
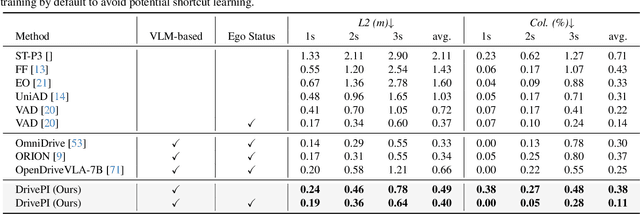
Although multi-modal large language models (MLLMs) have shown strong capabilities across diverse domains, their application in generating fine-grained 3D perception and prediction outputs in autonomous driving remains underexplored. In this paper, we propose DrivePI, a novel spatial-aware 4D MLLM that serves as a unified Vision-Language-Action (VLA) framework that is also compatible with vision-action (VA) models. Our method jointly performs spatial understanding, 3D perception (i.e., 3D occupancy), prediction (i.e., occupancy flow), and planning (i.e., action outputs) in parallel through end-to-end optimization. To obtain both precise geometric information and rich visual appearance, our approach integrates point clouds, multi-view images, and language instructions within a unified MLLM architecture. We further develop a data engine to generate text-occupancy and text-flow QA pairs for 4D spatial understanding. Remarkably, with only a 0.5B Qwen2.5 model as MLLM backbone, DrivePI as a single unified model matches or exceeds both existing VLA models and specialized VA models. Specifically, compared to VLA models, DrivePI outperforms OpenDriveVLA-7B by 2.5% mean accuracy on nuScenes-QA and reduces collision rate by 70% over ORION (from 0.37% to 0.11%) on nuScenes. Against specialized VA models, DrivePI surpasses FB-OCC by 10.3 RayIoU for 3D occupancy on OpenOcc, reduces the mAVE from 0.591 to 0.509 for occupancy flow on OpenOcc, and achieves 32% lower L2 error than VAD (from 0.72m to 0.49m) for planning on nuScenes. Code will be available at https://github.com/happinesslz/DrivePI
GenieDrive: Towards Physics-Aware Driving World Model with 4D Occupancy Guided Video Generation
Dec 14, 2025Physics-aware driving world model is essential for drive planning, out-of-distribution data synthesis, and closed-loop evaluation. However, existing methods often rely on a single diffusion model to directly map driving actions to videos, which makes learning difficult and leads to physically inconsistent outputs. To overcome these challenges, we propose GenieDrive, a novel framework designed for physics-aware driving video generation. Our approach starts by generating 4D occupancy, which serves as a physics-informed foundation for subsequent video generation. 4D occupancy contains rich physical information, including high-resolution 3D structures and dynamics. To facilitate effective compression of such high-resolution occupancy, we propose a VAE that encodes occupancy into a latent tri-plane representation, reducing the latent size to only 58% of that used in previous methods. We further introduce Mutual Control Attention (MCA) to accurately model the influence of control on occupancy evolution, and we jointly train the VAE and the subsequent prediction module in an end-to-end manner to maximize forecasting accuracy. Together, these designs yield a 7.2% improvement in forecasting mIoU at an inference speed of 41 FPS, while using only 3.47 M parameters. Additionally, a Normalized Multi-View Attention is introduced in the video generation model to generate multi-view driving videos with guidance from our 4D occupancy, significantly improving video quality with a 20.7% reduction in FVD. Experiments demonstrate that GenieDrive enables highly controllable, multi-view consistent, and physics-aware driving video generation.
Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Dec 09, 2025We present Wan-Move, a simple and scalable framework that brings motion control to video generative models. Existing motion-controllable methods typically suffer from coarse control granularity and limited scalability, leaving their outputs insufficient for practical use. We narrow this gap by achieving precise and high-quality motion control. Our core idea is to directly make the original condition features motion-aware for guiding video synthesis. To this end, we first represent object motions with dense point trajectories, allowing fine-grained control over the scene. We then project these trajectories into latent space and propagate the first frame's features along each trajectory, producing an aligned spatiotemporal feature map that tells how each scene element should move. This feature map serves as the updated latent condition, which is naturally integrated into the off-the-shelf image-to-video model, e.g., Wan-I2V-14B, as motion guidance without any architecture change. It removes the need for auxiliary motion encoders and makes fine-tuning base models easily scalable. Through scaled training, Wan-Move generates 5-second, 480p videos whose motion controllability rivals Kling 1.5 Pro's commercial Motion Brush, as indicated by user studies. To support comprehensive evaluation, we further design MoveBench, a rigorously curated benchmark featuring diverse content categories and hybrid-verified annotations. It is distinguished by larger data volume, longer video durations, and high-quality motion annotations. Extensive experiments on MoveBench and the public dataset consistently show Wan-Move's superior motion quality. Code, models, and benchmark data are made publicly available.
Seg-VAR: Image Segmentation with Visual Autoregressive Modeling
Nov 16, 2025While visual autoregressive modeling (VAR) strategies have shed light on image generation with the autoregressive models, their potential for segmentation, a task that requires precise low-level spatial perception, remains unexplored. Inspired by the multi-scale modeling of classic Mask2Former-based models, we propose Seg-VAR, a novel framework that rethinks segmentation as a conditional autoregressive mask generation problem. This is achieved by replacing the discriminative learning with the latent learning process. Specifically, our method incorporates three core components: (1) an image encoder generating latent priors from input images, (2) a spatial-aware seglat (a latent expression of segmentation mask) encoder that maps segmentation masks into discrete latent tokens using a location-sensitive color mapping to distinguish instances, and (3) a decoder reconstructing masks from these latents. A multi-stage training strategy is introduced: first learning seglat representations via image-seglat joint training, then refining latent transformations, and finally aligning image-encoder-derived latents with seglat distributions. Experiments show Seg-VAR outperforms previous discriminative and generative methods on various segmentation tasks and validation benchmarks. By framing segmentation as a sequential hierarchical prediction task, Seg-VAR opens new avenues for integrating autoregressive reasoning into spatial-aware vision systems. Code will be available at https://github.com/rkzheng99/Seg-VAR.