 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILLUME+: Illuminating Unified MLLM with Dual Visual Tokenization and Diffusion Refinement
Apr 03, 2025



We present ILLUME+ that leverages dual visual tokenization and a diffusion decoder to improve both deep semantic understanding and high-fidelity image generation. Existing unified models have struggled to simultaneously handle the three fundamental capabilities in a unified model: understanding, generation, and editing. Models like Chameleon and EMU3 utilize VQGAN for image discretization, due to the lack of deep semantic interaction, they lag behind specialist models like LLaVA in visual understanding tasks. To mitigate this, LaViT and ILLUME employ semantic encoders for tokenization, but they struggle with image editing due to poor texture preservation. Meanwhile, Janus series decouples the input and output image representation, limiting their abilities to seamlessly handle interleaved image-text understanding and generation. In contrast, ILLUME+ introduces a unified dual visual tokenizer, DualViTok, which preserves both fine-grained textures and text-aligned semantics while enabling a coarse-to-fine image representation strategy for multimodal understanding and generation. Additionally, we employ a diffusion model as the image detokenizer for enhanced generation quality and efficient super-resolution. ILLUME+ follows a continuous-input, discrete-output scheme within the unified MLLM and adopts a progressive training procedure that supports dynamic resolution across the vision tokenizer, MLLM, and diffusion decoder. This design allows for flexible and efficient context-aware image editing and generation across diverse tasks. ILLUME+ (3B) exhibits competitive performance against existing unified MLLMs and specialized models across multimodal understanding, generation, and editing benchmarks. With its strong performance, ILLUME+ provides a scalable and versatile foundation for future multimodal applications. Project Page: https://illume-unified-mllm.github.io/.
DynamiCtrl: Rethinking the Basic Structure and the Role of Text for High-quality Human Image Animation
Mar 27, 2025



Human image animation has recently gained significant attention due to advancements in generative models. However, existing methods still face two major challenges: (1) architectural limitations, most models rely on U-Net, which underperforms compared to the MM-DiT; and (2) the neglect of textual information, which can enhance controllability. In this work, we introduce DynamiCtrl, a novel framework that not only explores different pose-guided control structures in MM-DiT, but also reemphasizes the crucial role of text in this task. Specifically, we employ a Shared VAE encoder for both reference images and driving pose videos, eliminating the need for an additional pose encoder and simplifying the overall framework. To incorporate pose features into the full attention blocks, we propose Pose-adaptive Layer Norm (PadaLN), which utilizes adaptive layer normalization to encode sparse pose features. The encoded features are directly added to the visual input, preserving the spatiotemporal consistency of the backbone while effectively introducing pose control into MM-DiT. Furthermore, within the full attention mechanism, we align textual and visual features to enhance controllability. By leveraging text, we not only enable fine-grained control over the generated content, but also, for the first time, achieve simultaneous control over both background and motion. Experimental results verify the superiority of DynamiCtrl on benchmark datasets, demonstrating its strong identity preservation, heterogeneous character driving, background controllability, and high-quality synthesis. The project page is available at https://gulucaptain.github.io/DynamiCtrl/.
EDEN: Enhanced Diffusion for High-quality Large-motion Video Frame Interpolation
Mar 20, 2025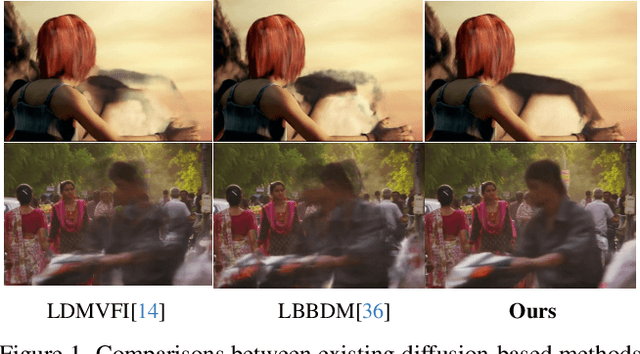
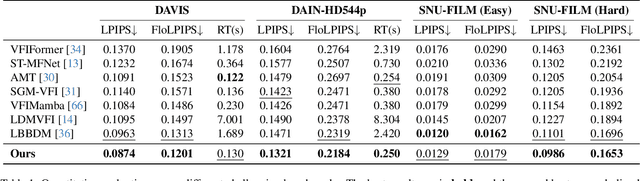

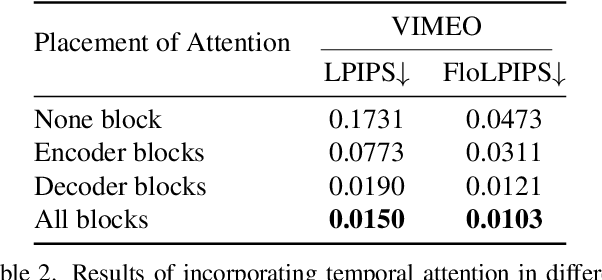
Handling complex or nonlinear motion patterns has long posed challenges for video frame interpolation. Although recent advances in diffusion-based methods offer improvements over traditional optical flow-based approaches, they still struggle to generate sharp, temporally consistent frames in scenarios with large motion. To address this limitation, we introduce EDEN, an Enhanced Diffusion for high-quality large-motion vidEo frame iNterpolation. Our approach first utilizes a transformer-based tokenizer to produce refined latent representations of the intermediate frames for diffusion models. We then enhance the diffusion transformer with temporal attention across the process and incorporate a start-end frame difference embedding to guide the generation of dynamic motion. Extensive experiments demonstrate that EDEN achieves state-of-the-art results across popular benchmarks, including nearly a 10% LPIPS reduction on DAVIS and SNU-FILM, and an 8% improvement on DAIN-HD.
ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance
Dec 09, 2024In this paper, we introduce ILLUME, a unified multimodal large language model (MLLM) that seamlessly integrates multimodal understanding and generation capabilities within a single large language model through a unified next-token prediction formulation. To address the large dataset size typically required for image-text alignment, we propose to enhance data efficiency through the design of a vision tokenizer that incorporates semantic information and a progressive multi-stage training procedure. This approach reduces the dataset size to just 15M for pretraining -- over four times fewer than what is typically needed -- while achieving competitive or even superior performance with existing unified MLLMs, such as Janus. Additionally, to promote synergistic enhancement between understanding and generation capabilities, which is under-explored in previous works, we introduce a novel self-enhancing multimodal alignment scheme. This scheme supervises the MLLM to self-assess the consistency between text descriptions and self-generated images, facilitating the model to interpret images more accurately and avoid unrealistic and incorrect predictions caused by misalignment in image generation. Based on extensive experiments, our proposed ILLUME stands out and competes with state-of-the-art unified MLLMs and specialized models across various benchmarks for multimodal understanding, generation, and editing.
LayerDiff: Exploring Text-guided Multi-layered Composable Image Synthesis via Layer-Collaborative Diffusion Model
Mar 18, 2024



Despite the success of generating high-quality images given any text prompts by diffusion-based generative models, prior works directly generate the entire images, but cannot provide object-wise manipulation capability. To support wider real applications like professional graphic design and digital artistry, images are frequently created and manipulated in multiple layers to offer greater flexibility and control. Therefore in this paper, we propose a layer-collaborative diffusion model, named LayerDiff, specifically designed for text-guided, multi-layered, composable image synthesis. The composable image consists of a background layer, a set of foreground layers, and associated mask layers for each foreground element. To enable this, LayerDiff introduces a layer-based generation paradigm incorporating multiple layer-collaborative attention modules to capture inter-layer patterns. Specifically, an inter-layer attention module is designed to encourage information exchange and learning between layers, while a text-guided intra-layer attention module incorporates layer-specific prompts to direct the specific-content generation for each layer. A layer-specific prompt-enhanced module better captures detailed textual cues from the global prompt. Additionally, a self-mask guidance sampling strategy further unleashes the model's ability to generate multi-layered images. We also present a pipeline that integrates existing perceptual and generative models to produce a large dataset of high-quality, text-prompted, multi-layered images. Extensive experiments demonstrate that our LayerDiff model can generate high-quality multi-layered images with performance comparable to conventional whole-image generation methods. Moreover, LayerDiff enables a broader range of controllable generative applications, including layer-specific image editing and style transfer.
PanGu-Draw: Advancing Resource-Efficient Text-to-Image Synthesis with Time-Decoupled Training and Reusable Coop-Diffusion
Dec 29, 2023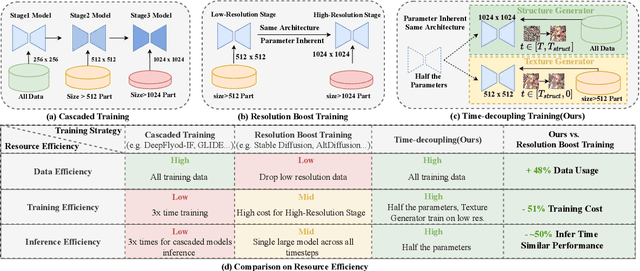

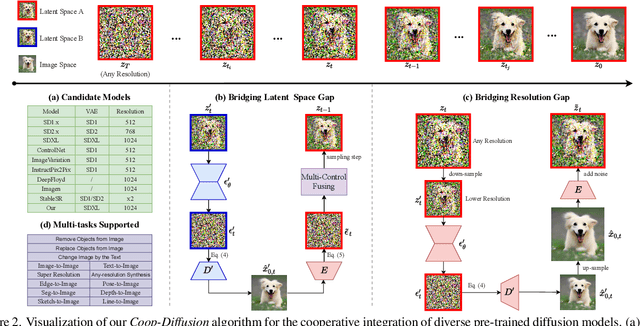

Current large-scale diffusion models represent a giant leap forward in conditional image synthesis, capable of interpreting diverse cues like text, human poses, and edges. However, their reliance on substantial computational resources and extensive data collection remains a bottleneck. On the other hand, the integration of existing diffusion models, each specialized for different controls and operating in unique latent spaces, poses a challenge due to incompatible image resolutions and latent space embedding structures, hindering their joint use. Addressing these constraints, we present "PanGu-Draw", a novel latent diffusion model designed for resource-efficient text-to-image synthesis that adeptly accommodates multiple control signals. We first propose a resource-efficient Time-Decoupling Training Strategy, which splits the monolithic text-to-image model into structure and texture generators. Each generator is trained using a regimen that maximizes data utilization and computational efficiency, cutting data preparation by 48% and reducing training resources by 51%. Secondly, we introduce "Coop-Diffusion", an algorithm that enables the cooperative use of various pre-trained diffusion models with different latent spaces and predefined resolutions within a unified denoising process. This allows for multi-control image synthesis at arbitrary resolutions without the necessity for additional data or retraining. Empirical validations of Pangu-Draw show its exceptional prowess in text-to-image and multi-control image generation, suggesting a promising direction for future model training efficiencies and generation versatility. The largest 5B T2I PanGu-Draw model is released on the Ascend platform. Project page: $\href{https://pangu-draw.github.io}{this~https~URL}$
Towards High-Fidelity Text-Guided 3D Face Generation and Manipulation Using only Images
Aug 31, 2023
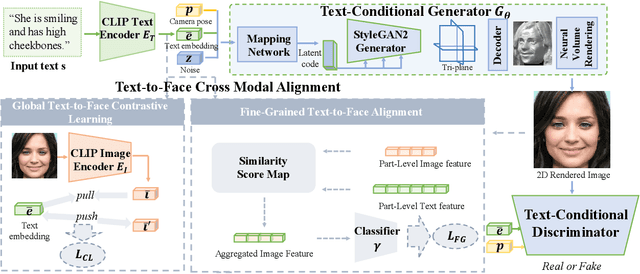
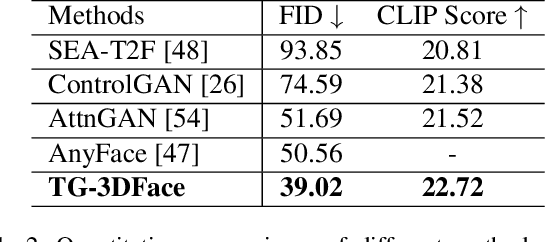

Generating 3D faces from textual descriptions has a multitude of applications, such as gaming, movie, and robotics. Recent progresses have demonstrated the success of unconditional 3D face generation and text-to-3D shape generation. However, due to the limited text-3D face data pairs, text-driven 3D face generation remains an open problem. In this paper, we propose a text-guided 3D faces generation method, refer as TG-3DFace, for generating realistic 3D faces using text guidance. Specifically, we adopt an unconditional 3D face generation framework and equip it with text conditions, which learns the text-guided 3D face generation with only text-2D face data. On top of that, we propose two text-to-face cross-modal alignment techniques, including the global contrastive learning and the fine-grained alignment module, to facilitate high semantic consistency between generated 3D faces and input texts. Besides, we present directional classifier guidance during the inference process, which encourages creativity for out-of-domain generations. Compared to the existing methods, TG-3DFace creates more realistic and aesthetically pleasing 3D faces, boosting 9% multi-view consistency (MVIC) over Latent3D. The rendered face images generated by TG-3DFace achieve higher FID and CLIP score than text-to-2D face/image generation models, demonstrating our superiority in generating realistic and semantic-consistent textures.
DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
Aug 22, 2023


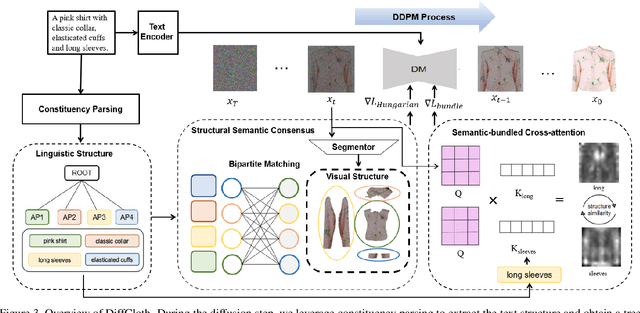
Cross-modal garment synthesis and manipulation will significantly benefit the way fashion designers generate garments and modify their designs via flexible linguistic interfaces.Current approaches follow the general text-to-image paradigm and mine cross-modal relations via simple cross-attention modules, neglecting the structural correspondence between visual and textual representations in the fashion design domain. In this work, we instead introduce DiffCloth, a diffusion-based pipeline for cross-modal garment synthesis and manipulation, which empowers diffusion models with flexible compositionality in the fashion domain by structurally aligning the cross-modal semantics. Specifically, we formulate the part-level cross-modal alignment as a bipartite matching problem between the linguistic Attribute-Phrases (AP) and the visual garment parts which are obtained via constituency parsing and semantic segmentation, respectively. To mitigate the issue of attribute confusion, we further propose a semantic-bundled cross-attention to preserve the spatial structure similarities between the attention maps of attribute adjectives and part nouns in each AP. Moreover, DiffCloth allows for manipulation of the generated results by simply replacing APs in the text prompts. The manipulation-irrelevant regions are recognized by blended masks obtained from the bundled attention maps of the APs and kept unchanged. Extensive experiments on the CM-Fashion benchmark demonstrate that DiffCloth both yields state-of-the-art garment synthesis results by leveraging the inherent structural information and supports flexible manipulation with region consistency.
DiffDis: Empowering Generative Diffusion Model with Cross-Modal Discrimination Capability
Aug 18, 2023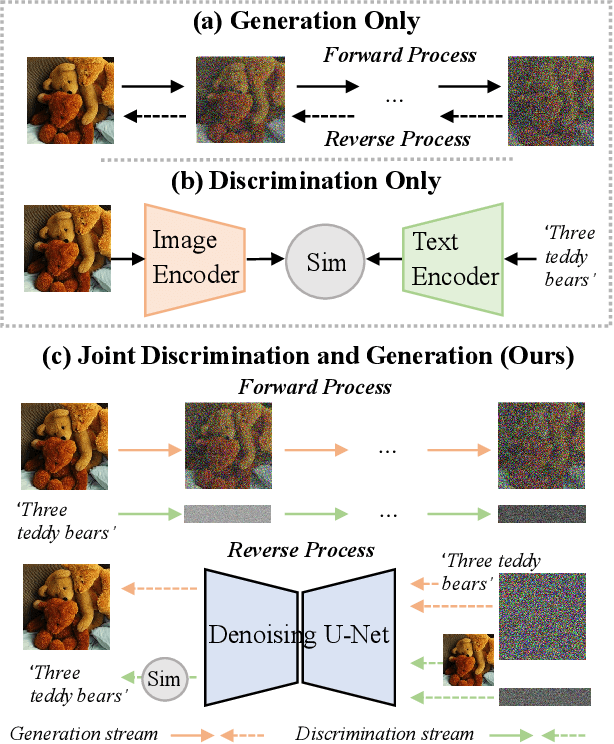
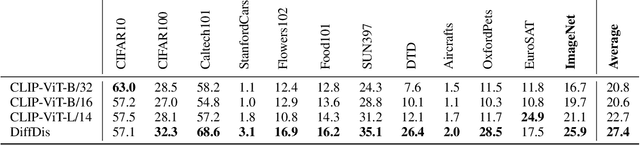
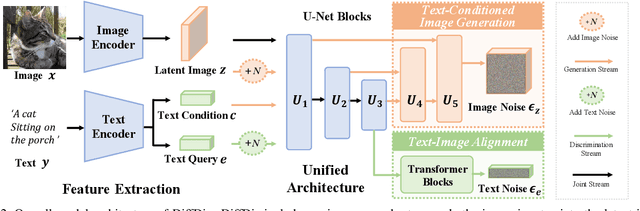
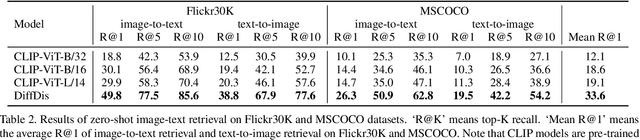
Recently, large-scale diffusion models, e.g., Stable diffusion and DallE2, have shown remarkable results on image synthesis. On the other hand, large-scale cross-modal pre-trained models (e.g., CLIP, ALIGN, and FILIP) are competent for various downstream tasks by learning to align vision and language embeddings. In this paper, we explore the possibility of jointly modeling generation and discrimination. Specifically, we propose DiffDis to unify the cross-modal generative and discriminative pretraining into one single framework under the diffusion process. DiffDis first formulates the image-text discriminative problem as a generative diffusion process of the text embedding from the text encoder conditioned on the image. Then, we propose a novel dual-stream network architecture, which fuses the noisy text embedding with the knowledge of latent images from different scales for image-text discriminative learning. Moreover, the generative and discriminative tasks can efficiently share the image-branch network structure in the multi-modality model. Benefiting from diffusion-based unified training, DiffDis achieves both better generation ability and cross-modal semantic alignment in one architecture. Experimental results show that DiffDis outperforms single-task models on both the image generation and the image-text discriminative tasks, e.g., 1.65% improvement on average accuracy of zero-shot classification over 12 datasets and 2.42 improvement on FID of zero-shot image synthesis.
Boosting Text-to-Image Diffusion Models with Fine-Grained Semantic Rewards
Jun 01, 2023

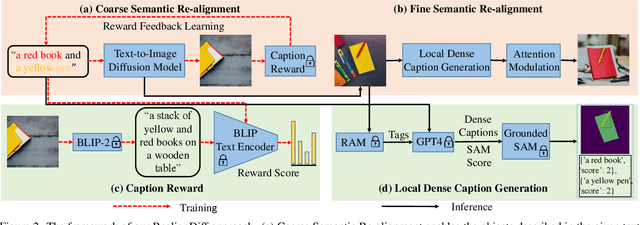
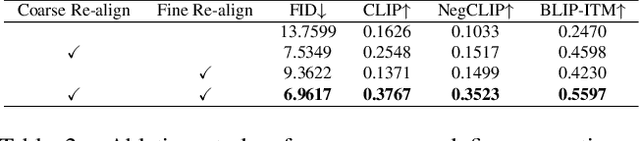
Recent advances in text-to-image diffusion models have achieved remarkable success in generating high-quality, realistic images from given text prompts. However, previous methods fail to perform accurate modality alignment between text concepts and generated images due to the lack of fine-level semantic guidance that successfully diagnoses the modality discrepancy. In this paper, we propose FineRewards to improve the alignment between text and images in text-to-image diffusion models by introducing two new fine-grained semantic rewards: the caption reward and the Semantic Segment Anything (SAM) reward. From the global semantic view, the caption reward generates a corresponding detailed caption that depicts all important contents in the synthetic image via a BLIP-2 model and then calculates the reward score by measuring the similarity between the generated caption and the given prompt. From the local semantic view, the SAM reward segments the generated images into local parts with category labels, and scores the segmented parts by measuring the likelihood of each category appearing in the prompted scene via a large language model, i.e., Vicuna-7B. Additionally, we adopt an assemble reward-ranked learning strategy to enable the integration of multiple reward functions to jointly guide the model training. Adapting results of text-to-image models on the MS-COCO benchmark show that the proposed semantic reward outperforms other baseline reward functions with a considerable margin on both visual quality and semantic similarity with the input prompt. Moreover, by adopting the assemble reward-ranked learning strategy, we further demonstrate that model performance is further improved when adapting under the unifying of the proposed semantic reward with the current image rewards.