 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Recurrent Transformer: Architecture Exploration, Training Strategies, and Scaling Behavior
May 26, 2026We study Latent Recurrent Transformer (LRT), a lightweight augmentation of autoregressive transformers that reuses a high-level source-layer hidden state from the previous token as recurrent memory for the next token. Because this source state is already computed during ordinary decoding, LRT adds a cross-layer recurrent latent pathway across positions without inserting pause tokens or extra depth loops, and the standard attention mechanism and KV-cache interface are preserved. To pretrain this recurrence at scale without sequentially unrolling the transformer, we introduce interleaved parallel training: a single full-sequence initialization forward pass builds a shared buffer; then disjoint position subsets are refined in parallel and written back, so that all tokens receive recurrent-memory-aware supervision at roughly 2 times baseline compute. Across nanochat style backbones and a wide range of tokens-per-parameter budgets, LRT improves both language-modeling loss and in-context learning under matched effective compute while adding as little as 0.3% parameters.
Efficient Matrix Implementation for Rotary Position Embedding
Apr 10, 2026Rotary Position Embedding (RoPE) has become a core component of modern Transformer architectures across language, vision, and 3D domains. However, existing implementations rely on vector-level split and merge operations that introduce non-negligible computational overhead, often overlooked in attention optimization. The problem is further amplified in multi-dimensional settings (e.g., 2D and 3D RoPE), where additional vector operations and uneven feature partitions degrade hardware utilization. To overcome these limitations, we propose RoME (Rotary Matrix position Embedding), a mathematically equivalent yet computationally efficient reformulation of RoPE that replaces vector operations with unified matrix transformations. RoME eliminates dimension-specific operations, simplifies implementation, and enables fused parallel execution across Cube and Vector units on modern NPUs. Experiments show that RoME delivers substantial acceleration at both the operator and full-model levels. The implementation is available at https://gitcode.com/cann/ops-transformer/blob/master/experimental/posembedding/rope_matrix/README.md.
DynaIP: Dynamic Image Prompt Adapter for Scalable Zero-shot Personalized Text-to-Image Generation
Dec 10, 2025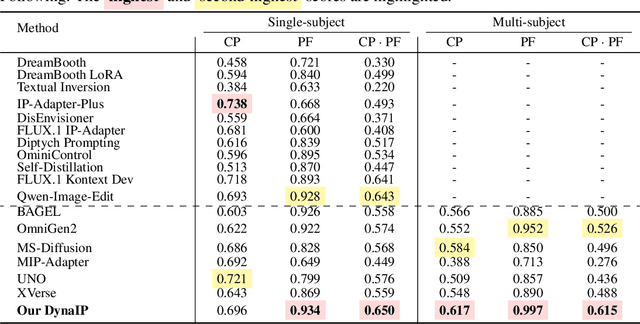

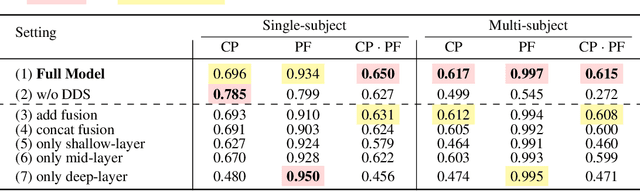
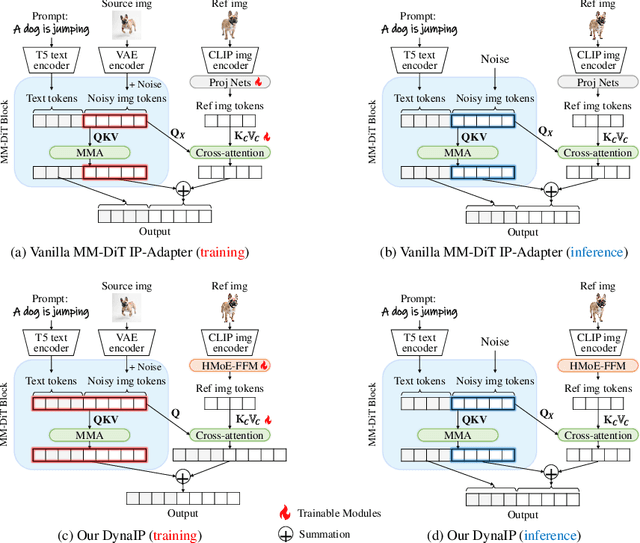
Personalized Text-to-Image (PT2I) generation aims to produce customized images based on reference images. A prominent interest pertains to the integration of an image prompt adapter to facilitate zero-shot PT2I without test-time fine-tuning. However, current methods grapple with three fundamental challenges: 1. the elusive equilibrium between Concept Preservation (CP) and Prompt Following (PF), 2. the difficulty in retaining fine-grained concept details in reference images, and 3. the restricted scalability to extend to multi-subject personalization. To tackle these challenges, we present Dynamic Image Prompt Adapter (DynaIP), a cutting-edge plugin to enhance the fine-grained concept fidelity, CP-PF balance, and subject scalability of SOTA T2I multimodal diffusion transformers (MM-DiT) for PT2I generation. Our key finding is that MM-DiT inherently exhibit decoupling learning behavior when injecting reference image features into its dual branches via cross attentions. Based on this, we design an innovative Dynamic Decoupling Strategy that removes the interference of concept-agnostic information during inference, significantly enhancing the CP-PF balance and further bolstering the scalability of multi-subject compositions. Moreover, we identify the visual encoder as a key factor affecting fine-grained CP and reveal that the hierarchical features of commonly used CLIP can capture visual information at diverse granularity levels. Therefore, we introduce a novel Hierarchical Mixture-of-Experts Feature Fusion Module to fully leverage the hierarchical features of CLIP, remarkably elevating the fine-grained concept fidelity while also providing flexible control of visual granularity. Extensive experiments across single- and multi-subject PT2I tasks verify that our DynaIP outperforms existing approaches, marking a notable advancement in the field of PT2l generation.
Multi-Joint Physics-Informed Deep Learning Framework for Time-Efficient Inverse Dynamics
Nov 14, 2025Time-efficient estimation of muscle activations and forces across multi-joint systems is critical for clinical assessment and assistive device control. However, conventional approaches are computationally expensive and lack a high-quality labeled dataset for multi-joint applications. To address these challenges, we propose a physics-informed deep learning framework that estimates muscle activations and forces directly from kinematics. The framework employs a novel Multi-Joint Cross-Attention (MJCA) module with Bidirectional Gated Recurrent Unit (BiGRU) layers to capture inter-joint coordination, enabling each joint to adaptively integrate motion information from others. By embedding multi-joint dynamics, inter-joint coupling, and external force interactions into the loss function, our Physics-Informed MJCA-BiGRU (PI-MJCA-BiGRU) delivers physiologically consistent predictions without labeled data while enabling time-efficient inference. Experimental validation on two datasets demonstrates that PI-MJCA-BiGRU achieves performance comparable to conventional supervised methods without requiring ground-truth labels, while the MJCA module significantly enhances inter-joint coordination modeling compared to other baseline architectures.
MultiCrafter: High-Fidelity Multi-Subject Generation via Spatially Disentangled Attention and Identity-Aware Reinforcement Learning
Sep 26, 2025Multi-subject image generation aims to synthesize user-provided subjects in a single image while preserving subject fidelity, ensuring prompt consistency, and aligning with human aesthetic preferences. However, existing methods, particularly those built on the In-Context-Learning paradigm, are limited by their reliance on simple reconstruction-based objectives, leading to both severe attribute leakage that compromises subject fidelity and failing to align with nuanced human preferences. To address this, we propose MultiCrafter, a framework that ensures high-fidelity, preference-aligned generation. First, we find that the root cause of attribute leakage is a significant entanglement of attention between different subjects during the generation process. Therefore, we introduce explicit positional supervision to explicitly separate attention regions for each subject, effectively mitigating attribute leakage. To enable the model to accurately plan the attention region of different subjects in diverse scenarios, we employ a Mixture-of-Experts architecture to enhance the model's capacity, allowing different experts to focus on different scenarios. Finally, we design a novel online reinforcement learning framework to align the model with human preferences, featuring a scoring mechanism to accurately assess multi-subject fidelity and a more stable training strategy tailored for the MoE architecture. Experiments validate that our framework significantly improves subject fidelity while aligning with human preferences better.
VisualToolAgent (VisTA): A Reinforcement Learning Framework for Visual Tool Selection
May 26, 2025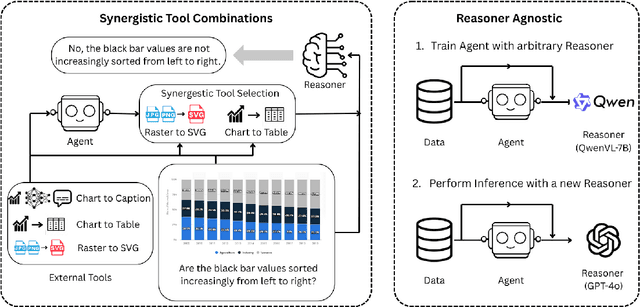
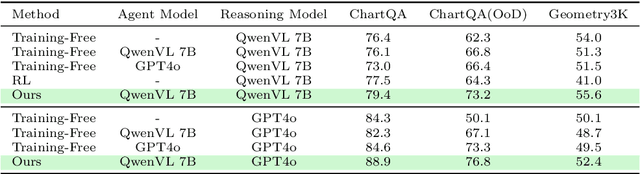
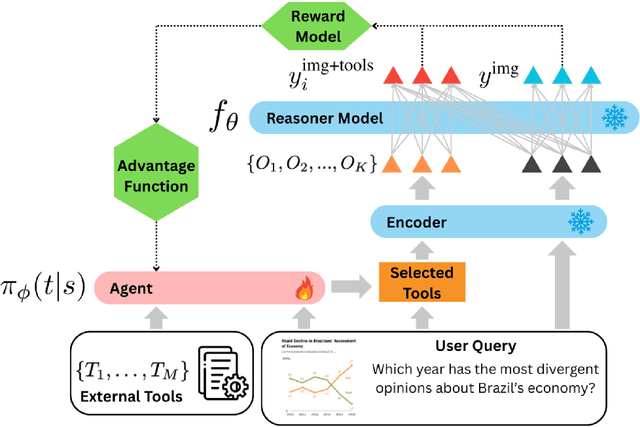
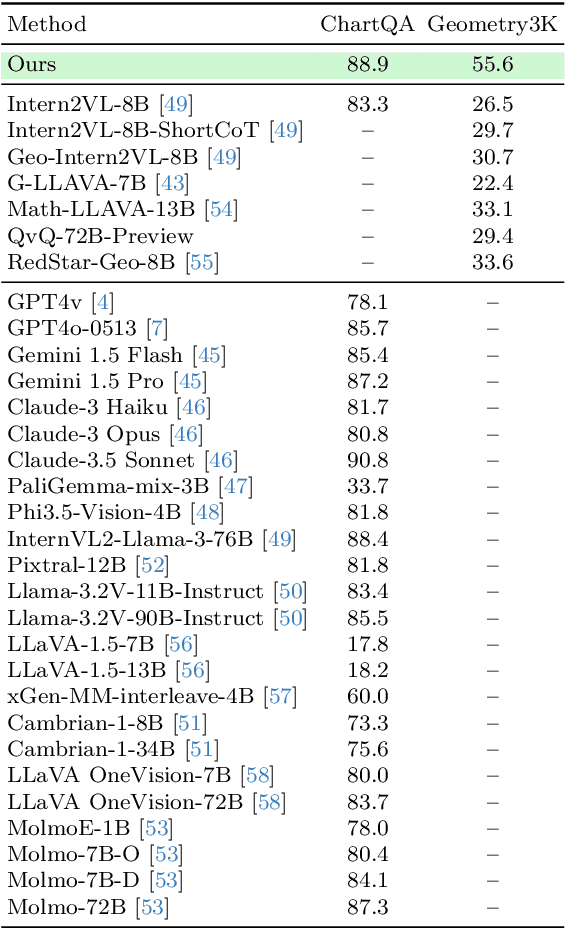
We introduce VisTA, a new reinforcement learning framework that empowers visual agents to dynamically explore, select, and combine tools from a diverse library based on empirical performance. Existing methods for tool-augmented reasoning either rely on training-free prompting or large-scale fine-tuning; both lack active tool exploration and typically assume limited tool diversity, and fine-tuning methods additionally demand extensive human supervision. In contrast, VisTA leverages end-to-end reinforcement learning to iteratively refine sophisticated, query-specific tool selection strategies, using task outcomes as feedback signals. Through Group Relative Policy Optimization (GRPO), our framework enables an agent to autonomously discover effective tool-selection pathways without requiring explicit reasoning supervision. Experiments on the ChartQA, Geometry3K, and BlindTest benchmarks demonstrate that VisTA achieves substantial performance gains over training-free baselines, especially on out-of-distribution examples. These results highlight VisTA's ability to enhance generalization, adaptively utilize diverse tools, and pave the way for flexible, experience-driven visual reasoning systems.
T2I-ConBench: Text-to-Image Benchmark for Continual Post-training
May 22, 2025Continual post-training adapts a single text-to-image diffusion model to learn new tasks without incurring the cost of separate models, but naive post-training causes forgetting of pretrained knowledge and undermines zero-shot compositionality. We observe that the absence of a standardized evaluation protocol hampers related research for continual post-training. To address this, we introduce T2I-ConBench, a unified benchmark for continual post-training of text-to-image models. T2I-ConBench focuses on two practical scenarios, item customization and domain enhancement, and analyzes four dimensions: (1) retention of generality, (2) target-task performance, (3) catastrophic forgetting, and (4) cross-task generalization. It combines automated metrics, human-preference modeling, and vision-language QA for comprehensive assessment. We benchmark ten representative methods across three realistic task sequences and find that no approach excels on all fronts. Even joint "oracle" training does not succeed for every task, and cross-task generalization remains unsolved. We release all datasets, code, and evaluation tools to accelerate research in continual post-training for text-to-image models.
Talk is Not Always Cheap: Promoting Wireless Sensing Models with Text Prompts
Apr 22, 2025Wireless signal-based human sensing technologies, such as WiFi, millimeter-wave (mmWave) radar, and Radio Frequency Identification (RFID), enable the detection and interpretation of human presence, posture, and activities, thereby providing critical support for applications in public security, healthcare, and smart environments. These technologies exhibit notable advantages due to their non-contact operation and environmental adaptability; however, existing systems often fail to leverage the textual information inherent in datasets. To address this, we propose an innovative text-enhanced wireless sensing framework, WiTalk, that seamlessly integrates semantic knowledge through three hierarchical prompt strategies-label-only, brief description, and detailed action description-without requiring architectural modifications or incurring additional data costs. We rigorously validate this framework across three public benchmark datasets: XRF55 for human action recognition (HAR), and WiFiTAL and XRFV2 for WiFi temporal action localization (TAL). Experimental results demonstrate significant performance improvements: on XRF55, accuracy for WiFi, RFID, and mmWave increases by 3.9%, 2.59%, and 0.46%, respectively; on WiFiTAL, the average performance of WiFiTAD improves by 4.98%; and on XRFV2, the mean average precision gains across various methods range from 4.02% to 13.68%. Our codes have been included in https://github.com/yangzhenkui/WiTalk.
HoGS: Unified Near and Far Object Reconstruction via Homogeneous Gaussian Splatting
Mar 25, 2025



Novel view synthesis has demonstrated impressive progress recently, with 3D Gaussian splatting (3DGS) offering efficient training time and photorealistic real-time rendering. However, reliance on Cartesian coordinates limits 3DGS's performance on distant objects, which is important for reconstructing unbounded outdoor environments. We found that, despite its ultimate simplicity, using homogeneous coordinates, a concept on the projective geometry, for the 3DGS pipeline remarkably improves the rendering accuracies of distant objects. We therefore propose Homogeneous Gaussian Splatting (HoGS) incorporating homogeneous coordinates into the 3DGS framework, providing a unified representation for enhancing near and distant objects. HoGS effectively manages both expansive spatial positions and scales particularly in outdoor unbounded environments by adopting projective geometry principles. Experiments show that HoGS significantly enhances accuracy in reconstructing distant objects while maintaining high-quality rendering of nearby objects, along with fast training speed and real-time rendering capability. Our implementations are available on our project page https://kh129.github.io/hogs/.
Do Vision Models Develop Human-Like Progressive Difficulty Understanding?
Mar 17, 2025When a human undertakes a test, their responses likely follow a pattern: if they answered an easy question $(2 \times 3)$ incorrectly, they would likely answer a more difficult one $(2 \times 3 \times 4)$ incorrectly; and if they answered a difficult question correctly, they would likely answer the easy one correctly. Anything else hints at memorization. Do current visual recognition models exhibit a similarly structured learning capacity? In this work, we consider the task of image classification and study if those models' responses follow that pattern. Since real images aren't labeled with difficulty, we first create a dataset of 100 categories, 10 attributes, and 3 difficulty levels using recent generative models: for each category (e.g., dog) and attribute (e.g., occlusion), we generate images of increasing difficulty (e.g., a dog without occlusion, a dog only partly visible). We find that most of the models do in fact behave similarly to the aforementioned pattern around 80-90% of the time. Using this property, we then explore a new way to evaluate those models. Instead of testing the model on every possible test image, we create an adaptive test akin to GRE, in which the model's performance on the current round of images determines the test images in the next round. This allows the model to skip over questions too easy/hard for itself, and helps us get its overall performance in fewer steps.