 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualToolAgent (VisTA): A Reinforcement Learning Framework for Visual Tool Selection
May 26, 2025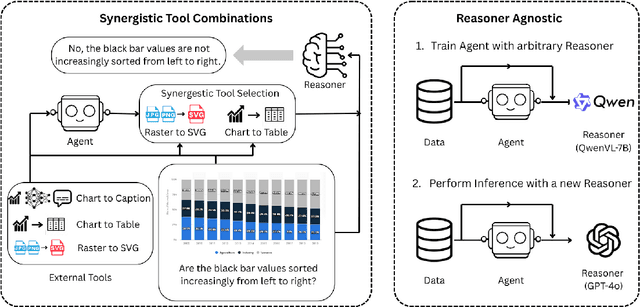
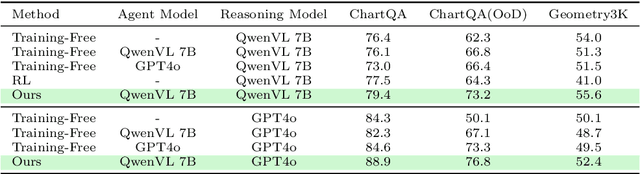
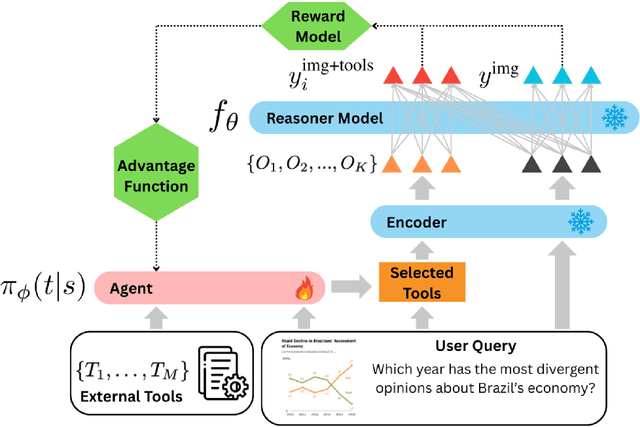
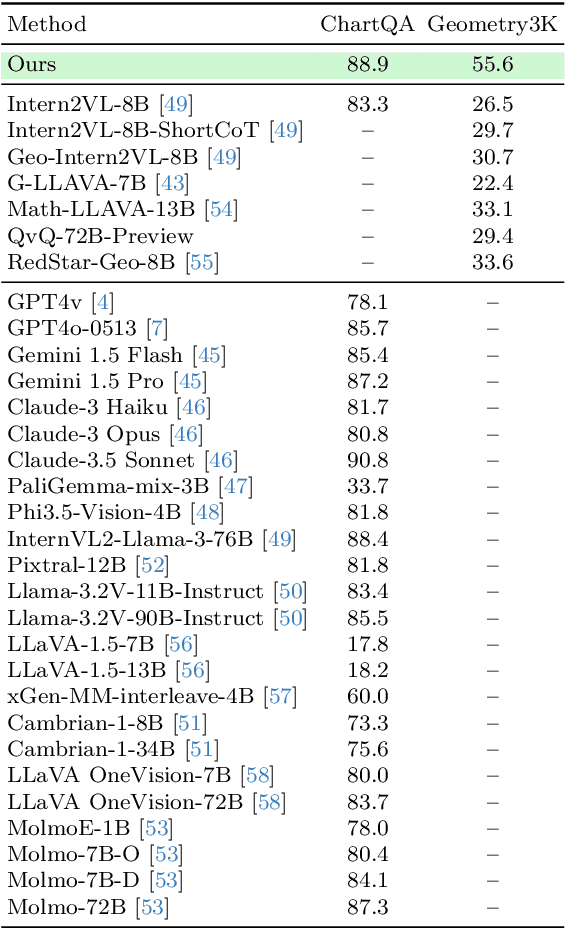
We introduce VisTA, a new reinforcement learning framework that empowers visual agents to dynamically explore, select, and combine tools from a diverse library based on empirical performance. Existing methods for tool-augmented reasoning either rely on training-free prompting or large-scale fine-tuning; both lack active tool exploration and typically assume limited tool diversity, and fine-tuning methods additionally demand extensive human supervision. In contrast, VisTA leverages end-to-end reinforcement learning to iteratively refine sophisticated, query-specific tool selection strategies, using task outcomes as feedback signals. Through Group Relative Policy Optimization (GRPO), our framework enables an agent to autonomously discover effective tool-selection pathways without requiring explicit reasoning supervision. Experiments on the ChartQA, Geometry3K, and BlindTest benchmarks demonstrate that VisTA achieves substantial performance gains over training-free baselines, especially on out-of-distribution examples. These results highlight VisTA's ability to enhance generalization, adaptively utilize diverse tools, and pave the way for flexible, experience-driven visual reasoning systems.
Socratic Chart: Cooperating Multiple Agents for Robust SVG Chart Understanding
Apr 14, 2025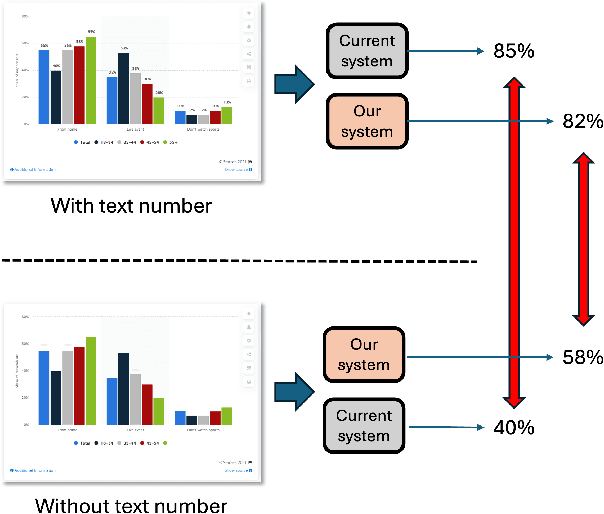



Multimodal Large Language Models (MLLMs) have shown remarkable versatility but face challenges in demonstrating true visual understanding, particularly in chart reasoning tasks. Existing benchmarks like ChartQA reveal significant reliance on text-based shortcuts and probabilistic pattern-matching rather than genuine visual reasoning. To rigorously evaluate visual reasoning, we introduce a more challenging test scenario by removing textual labels and introducing chart perturbations in the ChartQA dataset. Under these conditions, models like GPT-4o and Gemini-2.0 Pro experience up to a 30% performance drop, underscoring their limitations. To address these challenges, we propose Socratic Chart, a new framework that transforms chart images into Scalable Vector Graphics (SVG) representations, enabling MLLMs to integrate textual and visual modalities for enhanced chart understanding. Socratic Chart employs a multi-agent pipeline with specialized agent-generators to extract primitive chart attributes (e.g., bar heights, line coordinates) and an agent-critic to validate results, ensuring high-fidelity symbolic representations. Our framework surpasses state-of-the-art models in accurately capturing chart primitives and improving reasoning performance, establishing a robust pathway for advancing MLLM visual understanding.
Do Vision Models Develop Human-Like Progressive Difficulty Understanding?
Mar 17, 2025When a human undertakes a test, their responses likely follow a pattern: if they answered an easy question $(2 \times 3)$ incorrectly, they would likely answer a more difficult one $(2 \times 3 \times 4)$ incorrectly; and if they answered a difficult question correctly, they would likely answer the easy one correctly. Anything else hints at memorization. Do current visual recognition models exhibit a similarly structured learning capacity? In this work, we consider the task of image classification and study if those models' responses follow that pattern. Since real images aren't labeled with difficulty, we first create a dataset of 100 categories, 10 attributes, and 3 difficulty levels using recent generative models: for each category (e.g., dog) and attribute (e.g., occlusion), we generate images of increasing difficulty (e.g., a dog without occlusion, a dog only partly visible). We find that most of the models do in fact behave similarly to the aforementioned pattern around 80-90% of the time. Using this property, we then explore a new way to evaluate those models. Instead of testing the model on every possible test image, we create an adaptive test akin to GRE, in which the model's performance on the current round of images determines the test images in the next round. This allows the model to skip over questions too easy/hard for itself, and helps us get its overall performance in fewer steps.
IMPROVE: Iterative Model Pipeline Refinement and Optimization Leveraging LLM Agents
Feb 25, 2025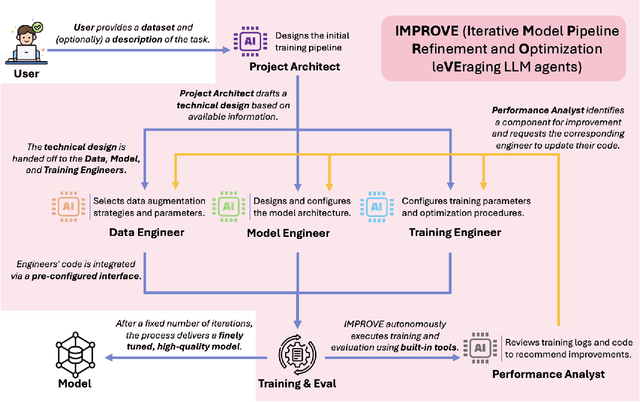



Computer vision is a critical component in a wide range of real-world applications, including plant monitoring in agriculture and handwriting classification in digital systems. However, developing high-performance computer vision models traditionally demands both machine learning (ML) expertise and domain-specific knowledge, making the process costly, labor-intensive, and inaccessible to many. Large language model (LLM) agents have emerged as a promising solution to automate this workflow, but most existing methods share a common limitation: they attempt to optimize entire pipelines in a single step before evaluation, making it difficult to attribute improvements to specific changes. This lack of granularity leads to unstable optimization and slower convergence, limiting their effectiveness. To address this, we introduce Iterative Refinement, a novel strategy for LLM-driven ML pipeline design inspired by how human ML experts iteratively refine models, focusing on one component at a time rather than making sweeping changes all at once. By systematically updating individual components based on real training feedback, Iterative Refinement improves stability, interpretability, and overall model performance. We implement this strategy in IMPROVE, an end-to-end LLM agent framework for automating and optimizing object classification pipelines. Through extensive evaluations across datasets of varying sizes and domains, including standard benchmarks and Kaggle competition datasets, we demonstrate that Iterative Refinement enables IMPROVE to consistently achieve better performance over existing zero-shot LLM-based approaches. These findings establish Iterative Refinement as an effective new strategy for LLM-driven ML automation and position IMPROVE as an accessible solution for building high-quality computer vision models without requiring ML expertise.
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
Jan 08, 2025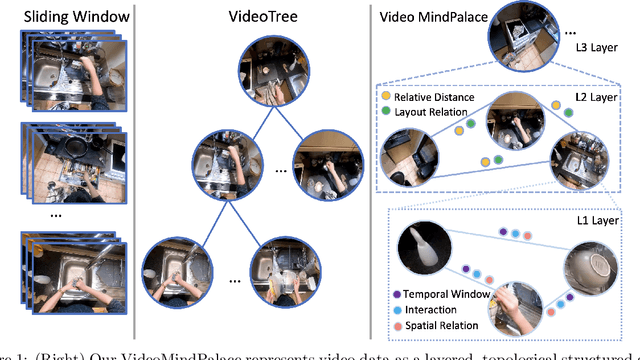
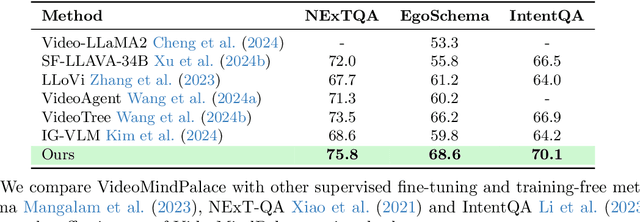
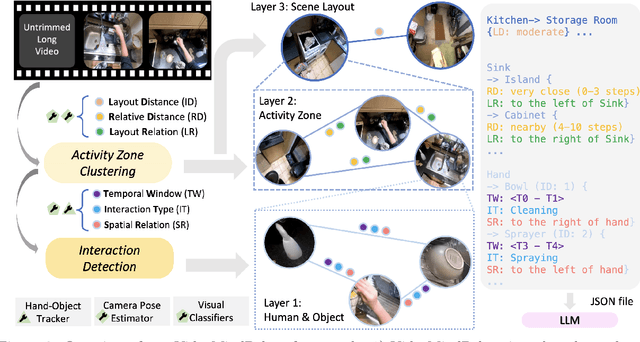
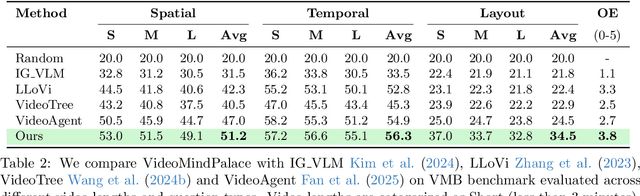
Long-form video understanding with Large Vision Language Models is challenged by the need to analyze temporally dispersed yet spatially concentrated key moments within limited context windows. In this work, we introduce VideoMindPalace, a new framework inspired by the "Mind Palace", which organizes critical video moments into a topologically structured semantic graph. VideoMindPalace organizes key information through (i) hand-object tracking and interaction, (ii) clustered activity zones representing specific areas of recurring activities, and (iii) environment layout mapping, allowing natural language parsing by LLMs to provide grounded insights on spatio-temporal and 3D context. In addition, we propose the Video MindPalace Benchmark (VMB), to assess human-like reasoning, including spatial localization, temporal reasoning, and layout-aware sequential understanding. Evaluated on VMB and established video QA datasets, including EgoSchema, NExT-QA, IntentQA, and the Active Memories Benchmark, VideoMindPalace demonstrates notable gains in spatio-temporal coherence and human-aligned reasoning, advancing long-form video analysis capabilities in VLMs.
AWT: Transferring Vision-Language Models via Augmentation, Weighting, and Transportation
Jul 05, 2024Pre-trained vision-language models (VLMs) have shown impressive results in various visual classification tasks. However, we often fail to fully unleash their potential when adapting them for new concept understanding due to limited information on new classes. To address this limitation, we introduce a novel adaptation framework, AWT (Augment, Weight, then Transport). AWT comprises three key components: augmenting inputs with diverse visual perspectives and enriched class descriptions through image transformations and language models; dynamically weighting inputs based on the prediction entropy; and employing optimal transport to mine semantic correlations in the vision-language space. AWT can be seamlessly integrated into various VLMs, enhancing their zero-shot capabilities without additional training and facilitating few-shot learning through an integrated multimodal adapter module. We verify AWT in multiple challenging scenarios, including zero-shot and few-shot image classification, zero-shot video action recognition, and out-of-distribution generalization. AWT consistently outperforms the state-of-the-art methods in each setting. In addition, our extensive studies further demonstrate AWT's effectiveness and adaptability across different VLMs, architectures, and scales.