 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
Jan 08, 2025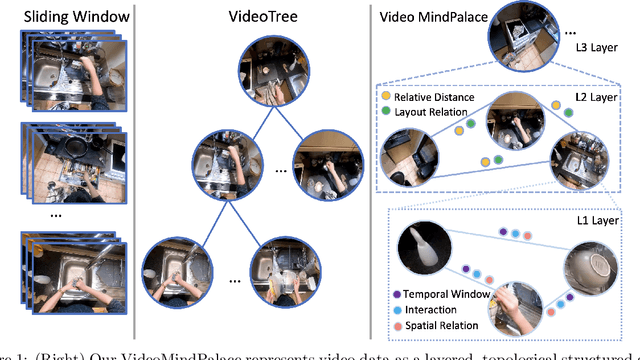
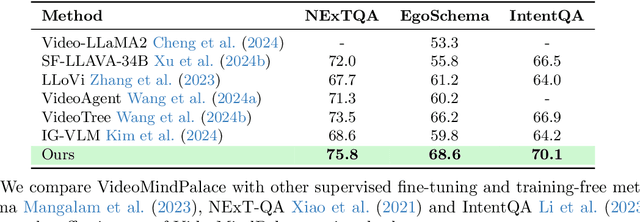
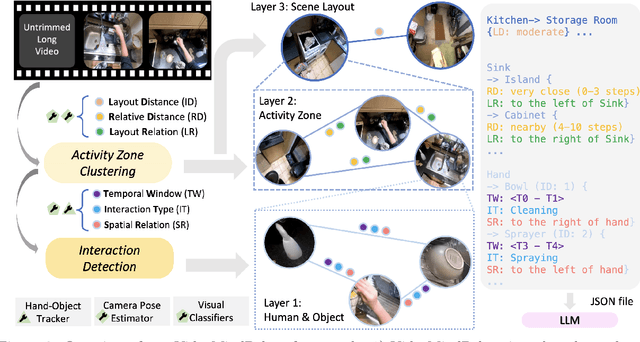
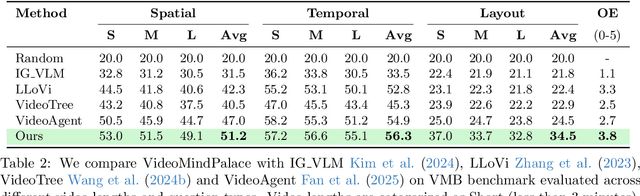
Long-form video understanding with Large Vision Language Models is challenged by the need to analyze temporally dispersed yet spatially concentrated key moments within limited context windows. In this work, we introduce VideoMindPalace, a new framework inspired by the "Mind Palace", which organizes critical video moments into a topologically structured semantic graph. VideoMindPalace organizes key information through (i) hand-object tracking and interaction, (ii) clustered activity zones representing specific areas of recurring activities, and (iii) environment layout mapping, allowing natural language parsing by LLMs to provide grounded insights on spatio-temporal and 3D context. In addition, we propose the Video MindPalace Benchmark (VMB), to assess human-like reasoning, including spatial localization, temporal reasoning, and layout-aware sequential understanding. Evaluated on VMB and established video QA datasets, including EgoSchema, NExT-QA, IntentQA, and the Active Memories Benchmark, VideoMindPalace demonstrates notable gains in spatio-temporal coherence and human-aligned reasoning, advancing long-form video analysis capabilities in VLMs.
Apollo: An Exploration of Video Understanding in Large Multimodal Models
Dec 13, 2024



Despite the rapid integration of video perception capabilities into Large Multimodal Models (LMMs), the underlying mechanisms driving their video understanding remain poorly understood. Consequently, many design decisions in this domain are made without proper justification or analysis. The high computational cost of training and evaluating such models, coupled with limited open research, hinders the development of video-LMMs. To address this, we present a comprehensive study that helps uncover what effectively drives video understanding in LMMs. We begin by critically examining the primary contributors to the high computational requirements associated with video-LMM research and discover Scaling Consistency, wherein design and training decisions made on smaller models and datasets (up to a critical size) effectively transfer to larger models. Leveraging these insights, we explored many video-specific aspects of video-LMMs, including video sampling, architectures, data composition, training schedules, and more. For example, we demonstrated that fps sampling during training is vastly preferable to uniform frame sampling and which vision encoders are the best for video representation. Guided by these findings, we introduce Apollo, a state-of-the-art family of LMMs that achieve superior performance across different model sizes. Our models can perceive hour-long videos efficiently, with Apollo-3B outperforming most existing $7$B models with an impressive 55.1 on LongVideoBench. Apollo-7B is state-of-the-art compared to 7B LMMs with a 70.9 on MLVU, and 63.3 on Video-MME.
Accelerating Multimodel Large Language Models by Searching Optimal Vision Token Reduction
Nov 30, 2024



Prevailing Multimodal Large Language Models (MLLMs) encode the input image(s) as vision tokens and feed them into the language backbone, similar to how Large Language Models (LLMs) process the text tokens. However, the number of vision tokens increases quadratically as the image resolutions, leading to huge computational costs. In this paper, we consider improving MLLM's efficiency from two scenarios, (I) Reducing computational cost without degrading the performance. (II) Improving the performance with given budgets. We start with our main finding that the ranking of each vision token sorted by attention scores is similar in each layer except the first layer. Based on it, we assume that the number of essential top vision tokens does not increase along layers. Accordingly, for Scenario I, we propose a greedy search algorithm (G-Search) to find the least number of vision tokens to keep at each layer from the shallow to the deep. Interestingly, G-Search is able to reach the optimal reduction strategy based on our assumption. For Scenario II, based on the reduction strategy from G-Search, we design a parametric sigmoid function (P-Sigmoid) to guide the reduction at each layer of the MLLM, whose parameters are optimized by Bayesian Optimization. Extensive experiments demonstrate that our approach can significantly accelerate those popular MLLMs, e.g. LLaVA, and InternVL2 models, by more than $2 \times$ without performance drops. Our approach also far outperforms other token reduction methods when budgets are limited, achieving a better trade-off between efficiency and effectiveness.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
ControlRoom3D: Room Generation using Semantic Proxy Rooms
Dec 08, 2023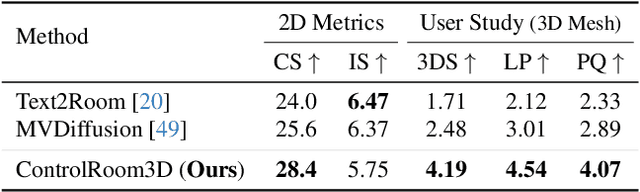
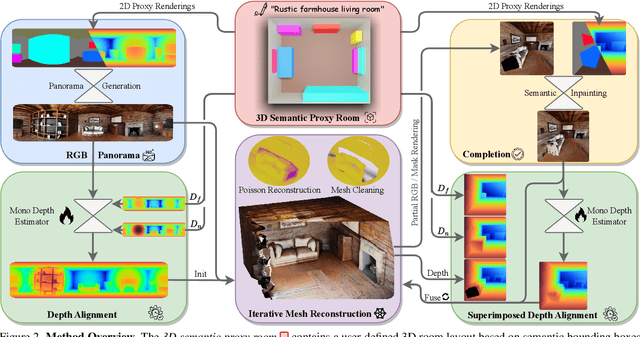
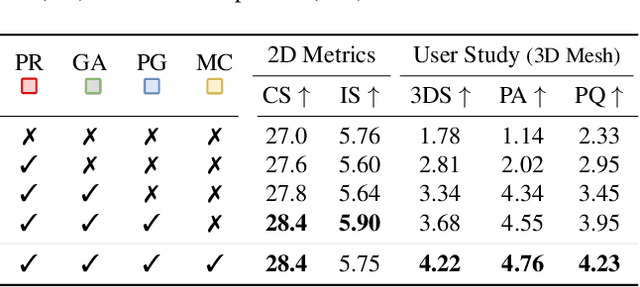
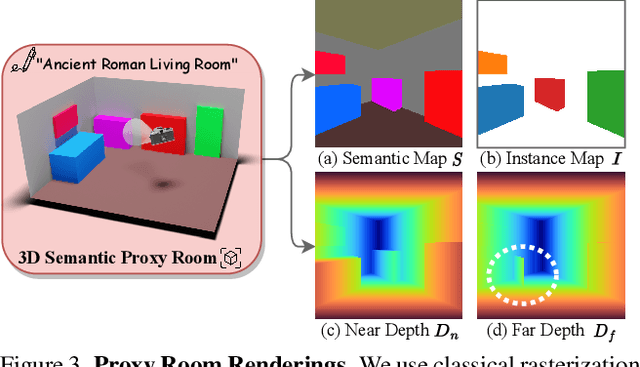
Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023



Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
Cost-Aware Evaluation and Model Scaling for LiDAR-Based 3D Object Detection
May 05, 2022

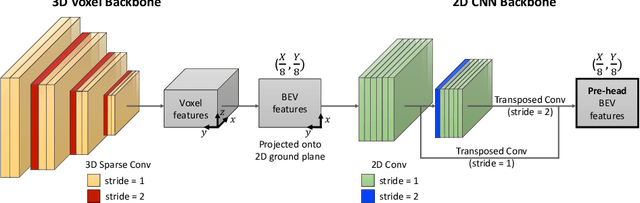
Considerable research efforts have been devoted to LiDAR-based 3D object detection and its empirical performance has been significantly improved. While the progress has been encouraging, we observe an overlooked issue: it is not yet common practice to compare different 3D detectors under the same cost, e.g., inference latency. This makes it difficult to quantify the true performance gain brought by recently proposed architecture designs. The goal of this work is to conduct a cost-aware evaluation of LiDAR-based 3D object detectors. Specifically, we focus on SECOND, a simple grid-based one-stage detector, and analyze its performance under different costs by scaling its original architecture. Then we compare the family of scaled SECOND with recent 3D detection methods, such as Voxel R-CNN and PV-RCNN++. The results are surprising. We find that, if allowed to use the same latency, SECOND can match the performance of PV-RCNN++, the current state-of-the-art method on the Waymo Open Dataset. Scaled SECOND also easily outperforms many recent 3D detection methods published during the past year. We recommend future research control the inference cost in their empirical comparison and include the family of scaled SECOND as a strong baseline when presenting novel 3D detection methods.
Learning Multi-Task Gaussian Process Over Heterogeneous Input Domains
Feb 25, 2022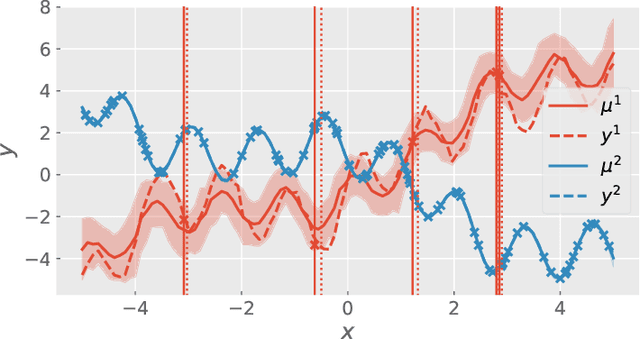
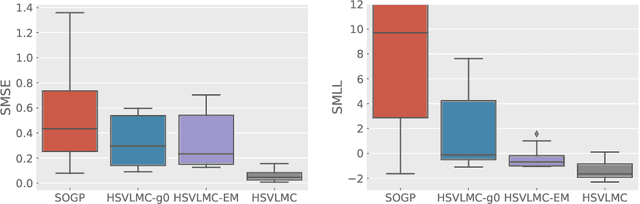
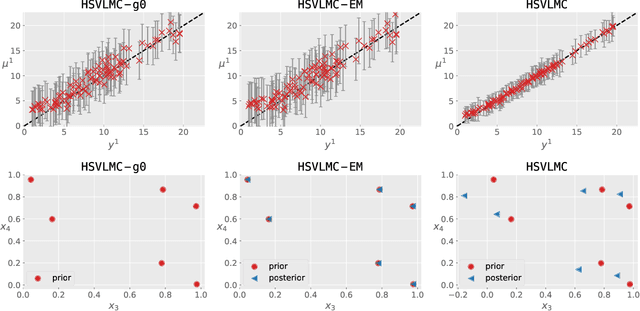
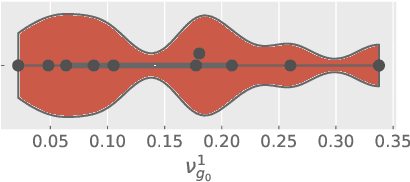
Multi-task Gaussian process (MTGP) is a well-known non-parametric Bayesian model for learning correlated tasks effectively by transferring knowledge across tasks. But current MTGP models are usually limited to the multi-task scenario defined in the same input domain, leaving no space for tackling the practical heterogeneous case, i.e., the features of input domains vary over tasks. To this end, this paper presents a novel heterogeneous stochastic variational linear model of coregionalization (HSVLMC) model for simultaneously learning the tasks with varied input domains. Particularly, we develop the stochastic variational framework with a Bayesian calibration method that (i) takes into account the effect of dimensionality reduction raised by domain mapping in order to achieve effective input alignment; and (ii) employs a residual modeling strategy to leverage the inductive bias brought by prior domain mappings for better model inference. Finally, the superiority of the proposed model against existing LMC models has been extensively verified on diverse heterogeneous multi-task cases.
Scalable Multi-Task Gaussian Processes with Neural Embedding of Coregionalization
Sep 20, 2021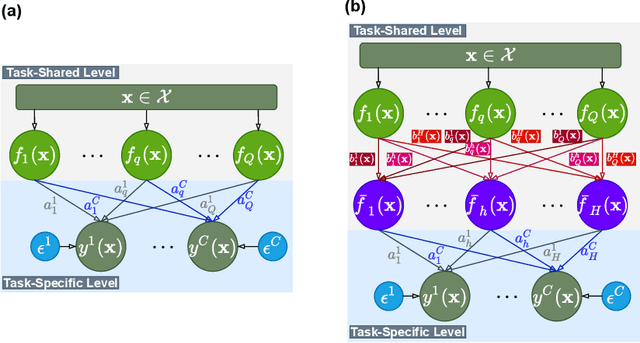
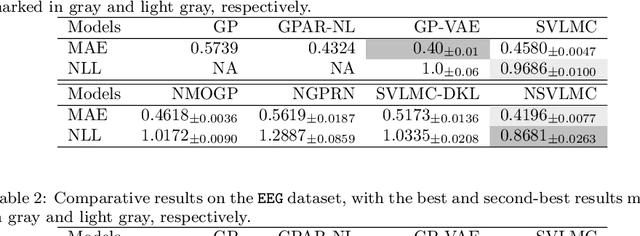
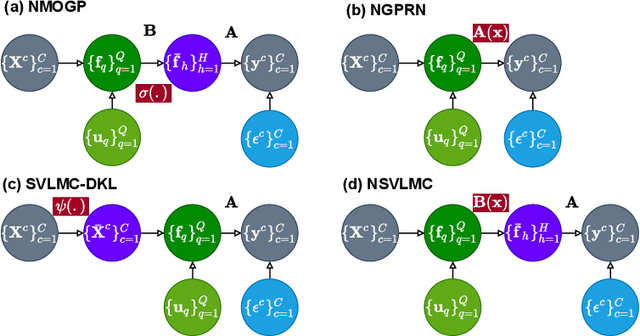
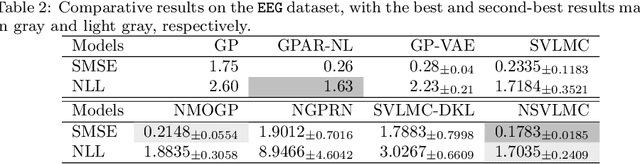
Multi-task regression attempts to exploit the task similarity in order to achieve knowledge transfer across related tasks for performance improvement. The application of Gaussian process (GP) in this scenario yields the non-parametric yet informative Bayesian multi-task regression paradigm. Multi-task GP (MTGP) provides not only the prediction mean but also the associated prediction variance to quantify uncertainty, thus gaining popularity in various scenarios. The linear model of coregionalization (LMC) is a well-known MTGP paradigm which exploits the dependency of tasks through linear combination of several independent and diverse GPs. The LMC however suffers from high model complexity and limited model capability when handling complicated multi-task cases. To this end, we develop the neural embedding of coregionalization that transforms the latent GPs into a high-dimensional latent space to induce rich yet diverse behaviors. Furthermore, we use advanced variational inference as well as sparse approximation to devise a tight and compact evidence lower bound (ELBO) for higher quality of scalable model inference. Extensive numerical experiments have been conducted to verify the higher prediction quality and better generalization of our model, named NSVLMC, on various real-world multi-task datasets and the cross-fluid modeling of unsteady fluidized bed.