 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
Jan 08, 2025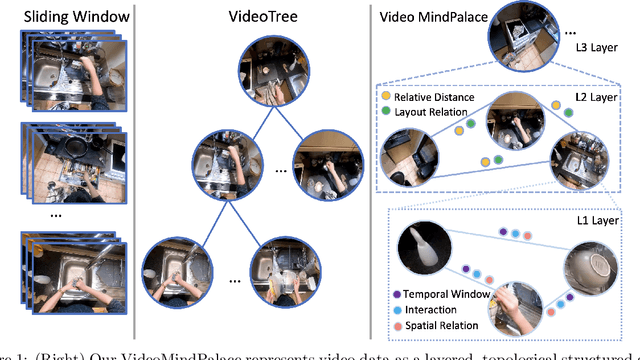
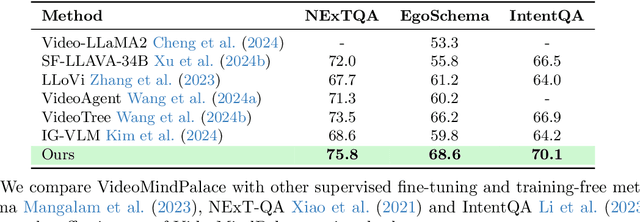
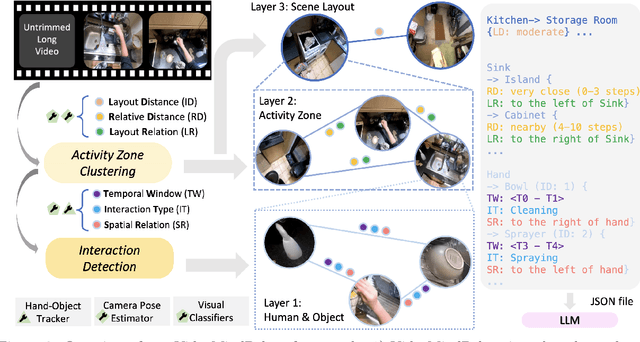
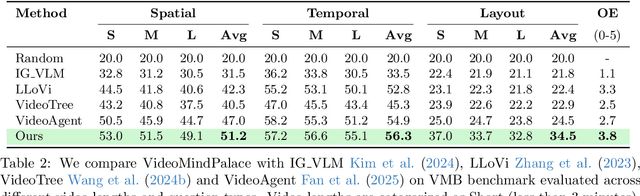
Long-form video understanding with Large Vision Language Models is challenged by the need to analyze temporally dispersed yet spatially concentrated key moments within limited context windows. In this work, we introduce VideoMindPalace, a new framework inspired by the "Mind Palace", which organizes critical video moments into a topologically structured semantic graph. VideoMindPalace organizes key information through (i) hand-object tracking and interaction, (ii) clustered activity zones representing specific areas of recurring activities, and (iii) environment layout mapping, allowing natural language parsing by LLMs to provide grounded insights on spatio-temporal and 3D context. In addition, we propose the Video MindPalace Benchmark (VMB), to assess human-like reasoning, including spatial localization, temporal reasoning, and layout-aware sequential understanding. Evaluated on VMB and established video QA datasets, including EgoSchema, NExT-QA, IntentQA, and the Active Memories Benchmark, VideoMindPalace demonstrates notable gains in spatio-temporal coherence and human-aligned reasoning, advancing long-form video analysis capabilities in VLMs.
Human Action Anticipation: A Survey
Oct 17, 2024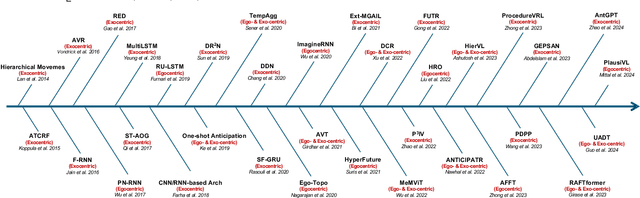

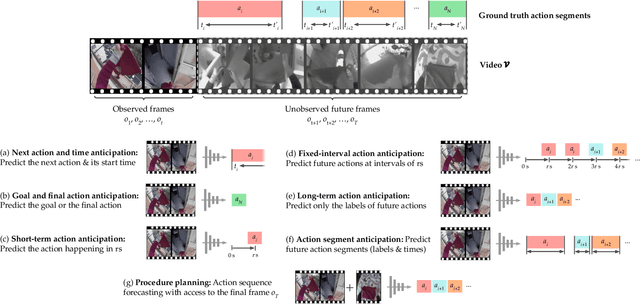
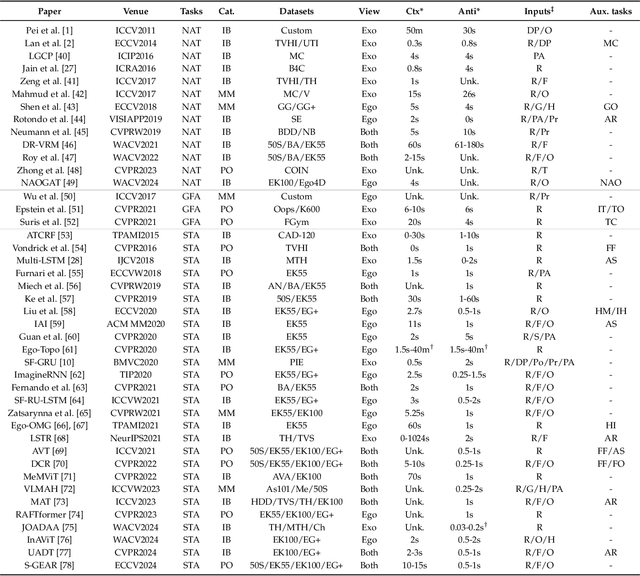
Predicting future human behavior is an increasingly popular topic in computer vision, driven by the interest in applications such as autonomous vehicles, digital assistants and human-robot interactions. The literature on behavior prediction spans various tasks, including action anticipation, activity forecasting, intent prediction, goal prediction, and so on. Our survey aims to tie together this fragmented literature, covering recent technical innovations as well as the development of new large-scale datasets for model training and evaluation. We also summarize the widely-used metrics for different tasks and provide a comprehensive performance comparison of existing approaches on eleven action anticipation datasets. This survey serves as not only a reference for contemporary methodologies in action anticipation, but also a guideline for future research direction of this evolving landscape.
BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation
May 15, 2024



The systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction. Project website: https://behavior-vision-suite.github.io/
SF-Net: Single-Frame Supervision for Temporal Action Localization
Mar 20, 2020In this paper, we study an intermediate form of supervision, i.e., single-frame supervision, for temporal action localization (TAL). To obtain the single-frame supervision, the annotators are asked to identify only a single frame within the temporal window of an action. This can significantly reduce the labor cost of obtaining full supervision which requires annotating the action boundary. Compared to the weak supervision that only annotates the video-level label, the single-frame supervision introduces extra temporal action signals while maintaining low annotation overhead. To make full use of such single-frame supervision, we propose a unified system called SF-Net. First, we propose to predict an actionness score for each video frame. Along with a typical category score, the actionness score can provide comprehensive information about the occurrence of a potential action and aid the temporal boundary refinement during inference. Second, we mine pseudo action and background frames based on the single-frame annotations. We identify pseudo action frames by adaptively expanding each annotated single frame to its nearby, contextual frames and we mine pseudo background frames from all the unannotated frames across multiple videos. Together with the ground-truth labeled frames, these pseudo-labeled frames are further used for training the classifier. In extensive experiments on THUMOS14, GTEA, and BEOID, SF-Net significantly improves upon state-of-the-art weakly-supervised methods in terms of both segment localization and single-frame localization. Notably, SF-Net achieves comparable results to its fully-supervised counterpart which requires much more resource intensive annotations.
Only Time Can Tell: Discovering Temporal Data for Temporal Modeling
Jul 19, 2019
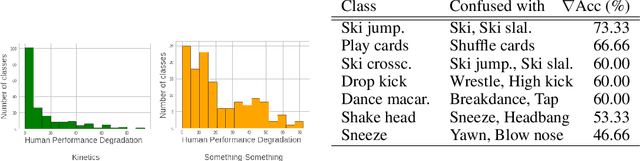


Understanding temporal information and how the visual world changes over time is a fundamental ability of intelligent systems. In video understanding, temporal information is at the core of many current challenges, including compression, efficient inference, motion estimation or summarization. However, in current video datasets it has been observed that action classes can often be recognized without any temporal information from a single frame of video. As a result, both benchmarking and training in these datasets may give an unintentional advantage to models with strong image understanding capabilities, as opposed to those with strong temporal understanding. In this paper we address this problem head on by identifying action classes where temporal information is actually necessary to recognize them and call these "temporal classes". Selecting temporal classes using a computational method would bias the process. Instead, we propose a methodology based on a simple and effective human annotation experiment. We remove just the temporal information by shuffling frames in time and measure if the action can still be recognized. Classes that cannot be recognized when frames are not in order are included in the temporal Dataset. We observe that this set is statistically different from other static classes, and that performance in it correlates with a network's ability to capture temporal information. Thus we use it as a benchmark on current popular networks, which reveals a series of interesting facts. We also explore the effect of training on the temporal dataset, and observe that this leads to better generalization in unseen classes, demonstrating the need for more temporal data. We hope that the proposed dataset of temporal categories will help guide future research in temporal modeling for better video understanding.
Exploiting Image-trained CNN Architectures for Unconstrained Video Classification
May 08, 2015
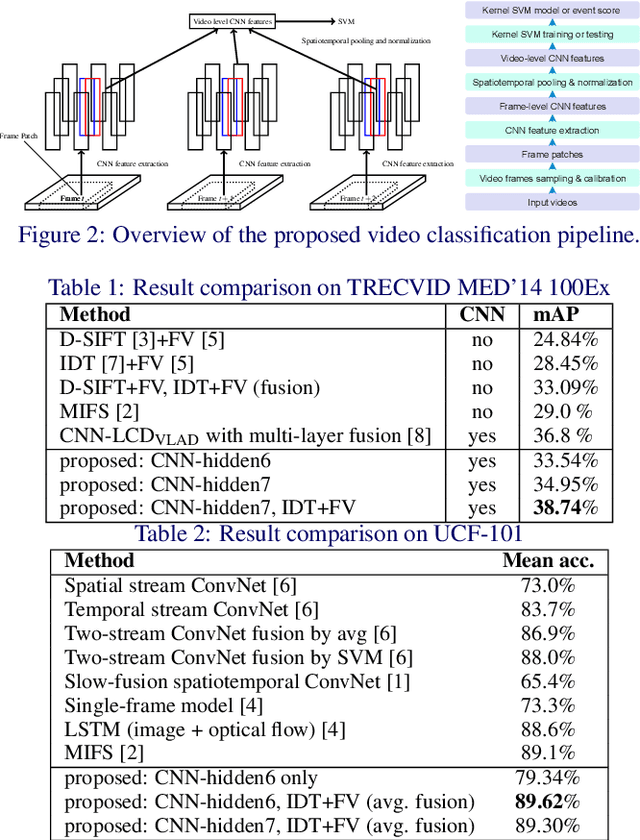
We conduct an in-depth exploration of different strategies for doing event detection in videos using convolutional neural networks (CNNs) trained for image classification. We study different ways of performing spatial and temporal pooling, feature normalization, choice of CNN layers as well as choice of classifiers. Making judicious choices along these dimensions led to a very significant increase in performance over more naive approaches that have been used till now. We evaluate our approach on the challenging TRECVID MED'14 dataset with two popular CNN architectures pretrained on ImageNet. On this MED'14 dataset, our methods, based entirely on image-trained CNN features, can outperform several state-of-the-art non-CNN models. Our proposed late fusion of CNN- and motion-based features can further increase the mean average precision (mAP) on MED'14 from 34.95% to 38.74%. The fusion approach achieves the state-of-the-art classification performance on the challenging UCF-101 dataset.