 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation
May 15, 2024



The systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction. Project website: https://behavior-vision-suite.github.io/
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024



We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
TeleMoMa: A Modular and Versatile Teleoperation System for Mobile Manipulation
Mar 12, 2024



A critical bottleneck limiting imitation learning in robotics is the lack of data. This problem is more severe in mobile manipulation, where collecting demonstrations is harder than in stationary manipulation due to the lack of available and easy-to-use teleoperation interfaces. In this work, we demonstrate TeleMoMa, a general and modular interface for whole-body teleoperation of mobile manipulators. TeleMoMa unifies multiple human interfaces including RGB and depth cameras, virtual reality controllers, keyboard, joysticks, etc., and any combination thereof. In its more accessible version, TeleMoMa works using simply vision (e.g., an RGB-D camera), lowering the entry bar for humans to provide mobile manipulation demonstrations. We demonstrate the versatility of TeleMoMa by teleoperating several existing mobile manipulators - PAL Tiago++, Toyota HSR, and Fetch - in simulation and the real world. We demonstrate the quality of the demonstrations collected with TeleMoMa by training imitation learning policies for mobile manipulation tasks involving synchronized whole-body motion. Finally, we also show that TeleMoMa's teleoperation channel enables teleoperation on site, looking at the robot, or remote, sending commands and observations through a computer network, and perform user studies to evaluate how easy it is for novice users to learn to collect demonstrations with different combinations of human interfaces enabled by our system. We hope TeleMoMa becomes a helpful tool for the community enabling researchers to collect whole-body mobile manipulation demonstrations. For more information and video results, https://robin-lab.cs.utexas.edu/telemoma-web.
NOIR: Neural Signal Operated Intelligent Robots for Everyday Activities
Nov 02, 2023



We present Neural Signal Operated Intelligent Robots (NOIR), a general-purpose, intelligent brain-robot interface system that enables humans to command robots to perform everyday activities through brain signals. Through this interface, humans communicate their intended objects of interest and actions to the robots using electroencephalography (EEG). Our novel system demonstrates success in an expansive array of 20 challenging, everyday household activities, including cooking, cleaning, personal care, and entertainment. The effectiveness of the system is improved by its synergistic integration of robot learning algorithms, allowing for NOIR to adapt to individual users and predict their intentions. Our work enhances the way humans interact with robots, replacing traditional channels of interaction with direct, neural communication. Project website: https://noir-corl.github.io/.
ARNOLD: A Benchmark for Language-Grounded Task Learning With Continuous States in Realistic 3D Scenes
Apr 09, 2023



Understanding the continuous states of objects is essential for task learning and planning in the real world. However, most existing task learning benchmarks assume discrete(e.g., binary) object goal states, which poses challenges for the learning of complex tasks and transferring learned policy from simulated environments to the real world. Furthermore, state discretization limits a robot's ability to follow human instructions based on the grounding of actions and states. To tackle these challenges, we present ARNOLD, a benchmark that evaluates language-grounded task learning with continuous states in realistic 3D scenes. ARNOLD is comprised of 8 language-conditioned tasks that involve understanding object states and learning policies for continuous goals. To promote language-instructed learning, we provide expert demonstrations with template-generated language descriptions. We assess task performance by utilizing the latest language-conditioned policy learning models. Our results indicate that current models for language-conditioned manipulations continue to experience significant challenges in novel goal-state generalizations, scene generalizations, and object generalizations. These findings highlight the need to develop new algorithms that address this gap and underscore the potential for further research in this area. See our project page at: https://arnold-benchmark.github.io
VRKitchen2.0-IndoorKit: A Tutorial for Augmented Indoor Scene Building in Omniverse
Jun 23, 2022

With the recent progress of simulations by 3D modeling software and game engines, many researchers have focused on Embodied AI tasks in the virtual environment. However, the research community lacks a platform that can easily serve both indoor scene synthesis and model benchmarking with various algorithms. Meanwhile, computer graphics-related tasks need a toolkit for implementing advanced synthesizing techniques. To facilitate the study of indoor scene building methods and their potential robotics applications, we introduce INDOORKIT: a built-in toolkit for NVIDIA OMNIVERSE that provides flexible pipelines for indoor scene building, scene randomizing, and animation controls. Besides, combining Python coding in the animation software INDOORKIT assists researchers in creating real-time training and controlling avatars and robotics. The source code for this toolkit is available at https://github.com/realvcla/VRKitchen2.0-Tutorial, and the tutorial along with the toolkit is available at https://vrkitchen20-tutorial.readthedocs.io/en/
Triangular Character Animation Sampling with Motion, Emotion, and Relation
Mar 09, 2022

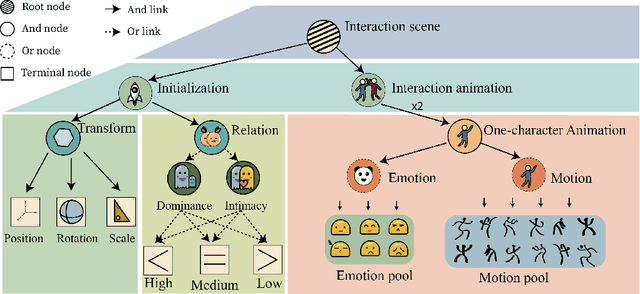

Dramatic progress has been made in animating individual characters. However, we still lack automatic control over activities between characters, especially those involving interactions. In this paper, we present a novel energy-based framework to sample and synthesize animations by associating the characters' body motions, facial expressions, and social relations. We propose a Spatial-Temporal And-Or graph (ST-AOG), a stochastic grammar model, to encode the contextual relationship between motion, emotion, and relation, forming a triangle in a conditional random field. We train our model from a labeled dataset of two-character interactions. Experiments demonstrate that our method can recognize the social relation between two characters and sample new scenes of vivid motion and emotion using Markov Chain Monte Carlo (MCMC) given the social relation. Thus, our method can provide animators with an automatic way to generate 3D character animations, help synthesize interactions between Non-Player Characters (NPCs), and enhance machine emotion intelligence (EQ) in virtual reality (VR).