 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Adaptation of Particle Dynamics for Generalized Deformable Object Mobile Manipulation
Mar 18, 2026We address the challenge of learning to manipulate deformable objects with unknown dynamics. In non-rigid objects, the dynamics parameters define how they react to interactions -- how they stretch, bend, compress, and move -- and they are critical to determining the optimal actions to perform a manipulation task successfully. In other robotic domains, such as legged locomotion and in-hand rigid object manipulation, state-of-the-art approaches can handle unknown dynamics using Rapid Motor Adaptation (RMA). Through a supervised procedure in simulation that encodes each rigid object's dynamics, such as mass and position, these approaches learn a policy that conditions actions on a vector of latent dynamic parameters inferred from sequences of state-actions. However, in deformable object manipulation, the object's dynamics not only includes its mass and position, but also how the shape of the object changes. Our key insight is that the recent ground-truth particle positions of a deformable object in simulation capture changes in the object's shape, making it possible to extend RMA to deformable object manipulation. This key insight allows us to develop RAPiD, a two-phase method that learns to perform real-robot deformable object mobile manipulation by: 1) learning a visuomotor policy conditioned on the object's dynamics embedding, which is encoded from the object's privileged information in simulation, such as its mass and ground-truth particle positions, and 2) learning to infer this embedding using non-privileged information instead, such as robot visual observations and actions, so that the learned policy can transfer to the real world. On a mobile manipulator with 22 degrees of freedom, RAPiD enables over 80%+ success rates across two vision-based deformable object mobile manipulation tasks in the real world, under various object dynamics, categories, and instances.
Large-Language-Model-Guided State Estimation for Partially Observable Task and Motion Planning
Mar 04, 2026Robot planning in partially observable environments, where not all objects are known or visible, is a challenging problem, as it requires reasoning under uncertainty through partially observable Markov decision processes. During the execution of a computed plan, a robot may unexpectedly observe task-irrelevant objects, which are typically ignored by naive planners. In this work, we propose incorporating two types of common-sense knowledge: (1) certain objects are more likely to be found in specific locations; and (2) similar objects are likely to be co-located, while dissimilar objects are less likely to be found together. Manually engineering such knowledge is complex, so we explore leveraging the powerful common-sense reasoning capabilities of large language models (LLMs). Our planning and execution framework, CoCo-TAMP, introduces a hierarchical state estimation that uses LLM-guided information to shape the belief over task-relevant objects, enabling efficient solutions to long-horizon task and motion planning problems. In experiments, CoCo-TAMP achieves an average reduction of 62.7 in planning and execution time in simulation, and 72.6 in real-world demonstrations, compared to a baseline that does not incorporate either type of common-sense knowledge.
Factored Latent Action World Models
Feb 18, 2026Learning latent actions from action-free video has emerged as a powerful paradigm for scaling up controllable world model learning. Latent actions provide a natural interface for users to iteratively generate and manipulate videos. However, most existing approaches rely on monolithic inverse and forward dynamics models that learn a single latent action to control the entire scene, and therefore struggle in complex environments where multiple entities act simultaneously. This paper introduces Factored Latent Action Model (FLAM), a factored dynamics framework that decomposes the scene into independent factors, each inferring its own latent action and predicting its own next-step factor value. This factorized structure enables more accurate modeling of complex multi-entity dynamics and improves video generation quality in action-free video settings compared to monolithic models. Based on experiments on both simulation and real-world multi-entity datasets, we find that FLAM outperforms prior work in prediction accuracy and representation quality, and facilitates downstream policy learning, demonstrating the benefits of factorized latent action models.
Searching in Space and Time: Unified Memory-Action Loops for Open-World Object Retrieval
Nov 19, 2025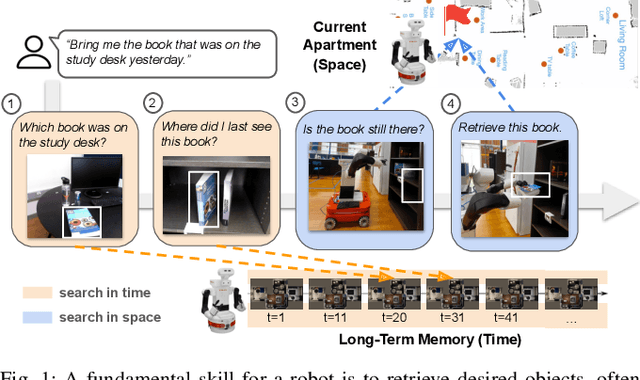
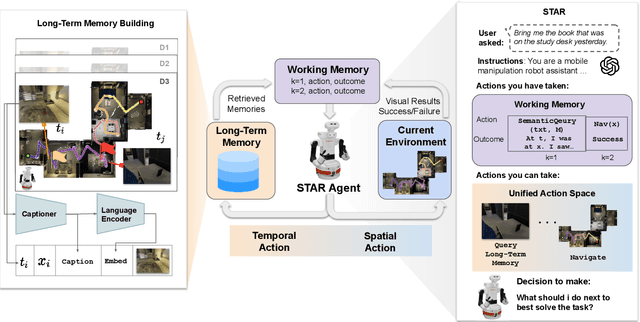

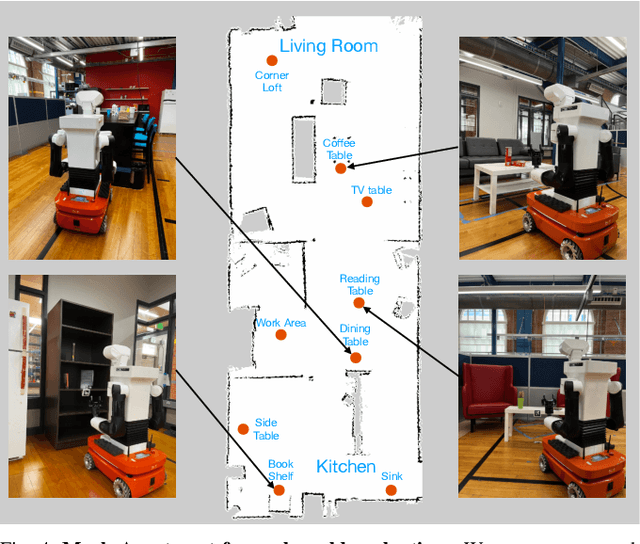
Service robots must retrieve objects in dynamic, open-world settings where requests may reference attributes ("the red mug"), spatial context ("the mug on the table"), or past states ("the mug that was here yesterday"). Existing approaches capture only parts of this problem: scene graphs capture spatial relations but ignore temporal grounding, temporal reasoning methods model dynamics but do not support embodied interaction, and dynamic scene graphs handle both but remain closed-world with fixed vocabularies. We present STAR (SpatioTemporal Active Retrieval), a framework that unifies memory queries and embodied actions within a single decision loop. STAR leverages non-parametric long-term memory and a working memory to support efficient recall, and uses a vision-language model to select either temporal or spatial actions at each step. We introduce STARBench, a benchmark of spatiotemporal object search tasks across simulated and real environments. Experiments in STARBench and on a Tiago robot show that STAR consistently outperforms scene-graph and memory-only baselines, demonstrating the benefits of treating search in time and search in space as a unified problem.
CAVER: Curious Audiovisual Exploring Robot
Nov 10, 2025Multimodal audiovisual perception can enable new avenues for robotic manipulation, from better material classification to the imitation of demonstrations for which only audio signals are available (e.g., playing a tune by ear). However, to unlock such multimodal potential, robots need to learn the correlations between an object's visual appearance and the sound it generates when they interact with it. Such an active sensorimotor experience requires new interaction capabilities, representations, and exploration methods to guide the robot in efficiently building increasingly rich audiovisual knowledge. In this work, we present CAVER, a novel robot that builds and utilizes rich audiovisual representations of objects. CAVER includes three novel contributions: 1) a novel 3D printed end-effector, attachable to parallel grippers, that excites objects' audio responses, 2) an audiovisual representation that combines local and global appearance information with sound features, and 3) an exploration algorithm that uses and builds the audiovisual representation in a curiosity-driven manner that prioritizes interacting with high uncertainty objects to obtain good coverage of surprising audio with fewer interactions. We demonstrate that CAVER builds rich representations in different scenarios more efficiently than several exploration baselines, and that the learned audiovisual representation leads to significant improvements in material classification and the imitation of audio-only human demonstrations. https://caver-bot.github.io/
GET-USE: Learning Generalized Tool Usage for Bimanual Mobile Manipulation via Simulated Embodiment Extensions
Oct 29, 2025The ability to use random objects as tools in a generalizable manner is a missing piece in robots' intelligence today to boost their versatility and problem-solving capabilities. State-of-the-art robotic tool usage methods focused on procedurally generating or crowd-sourcing datasets of tools for a task to learn how to grasp and manipulate them for that task. However, these methods assume that only one object is provided and that it is possible, with the correct grasp, to perform the task; they are not capable of identifying, grasping, and using the best object for a task when many are available, especially when the optimal tool is absent. In this work, we propose GeT-USE, a two-step procedure that learns to perform real-robot generalized tool usage by learning first to extend the robot's embodiment in simulation and then transferring the learned strategies to real-robot visuomotor policies. Our key insight is that by exploring a robot's embodiment extensions (i.e., building new end-effectors) in simulation, the robot can identify the general tool geometries most beneficial for a task. This learned geometric knowledge can then be distilled to perform generalized tool usage tasks by selecting and using the best available real-world object as tool. On a real robot with 22 degrees of freedom (DOFs), GeT-USE outperforms state-of-the-art methods by 30-60% success rates across three vision-based bimanual mobile manipulation tool-usage tasks.
Mixed-Initiative Dialog for Human-Robot Collaborative Manipulation
Aug 07, 2025Effective robotic systems for long-horizon human-robot collaboration must adapt to a wide range of human partners, whose physical behavior, willingness to assist, and understanding of the robot's capabilities may change over time. This demands a tightly coupled communication loop that grants both agents the flexibility to propose, accept, or decline requests as they coordinate toward completing the task effectively. We apply a Mixed-Initiative dialog paradigm to Collaborative human-roBot teaming and propose MICoBot, a system that handles the common scenario where both agents, using natural language, take initiative in formulating, accepting, or rejecting proposals on who can best complete different steps of a task. To handle diverse, task-directed dialog, and find successful collaborative strategies that minimize human effort, MICoBot makes decisions at three levels: (1) a meta-planner considers human dialog to formulate and code a high-level collaboration strategy, (2) a planner optimally allocates the remaining steps to either agent based on the robot's capabilities (measured by a simulation-pretrained affordance model) and the human's estimated availability to help, and (3) an action executor decides the low-level actions to perform or words to say to the human. Our extensive evaluations in simulation and real-world -- on a physical robot with 18 unique human participants over 27 hours -- demonstrate the ability of our method to effectively collaborate with diverse human users, yielding significantly improved task success and user experience than a pure LLM baseline and other agent allocation models. See additional videos and materials at https://robin-lab.cs.utexas.edu/MicoBot/.
Casper: Inferring Diverse Intents for Assistive Teleoperation with Vision Language Models
Jun 17, 2025



Assistive teleoperation, where control is shared between a human and a robot, enables efficient and intuitive human-robot collaboration in diverse and unstructured environments. A central challenge in real-world assistive teleoperation is for the robot to infer a wide range of human intentions from user control inputs and to assist users with correct actions. Existing methods are either confined to simple, predefined scenarios or restricted to task-specific data distributions at training, limiting their support for real-world assistance. We introduce Casper, an assistive teleoperation system that leverages commonsense knowledge embedded in pre-trained visual language models (VLMs) for real-time intent inference and flexible skill execution. Casper incorporates an open-world perception module for a generalized understanding of novel objects and scenes, a VLM-powered intent inference mechanism that leverages commonsense reasoning to interpret snippets of teleoperated user input, and a skill library that expands the scope of prior assistive teleoperation systems to support diverse, long-horizon mobile manipulation tasks. Extensive empirical evaluation, including human studies and system ablations, demonstrates that Casper improves task performance, reduces human cognitive load, and achieves higher user satisfaction than direct teleoperation and assistive teleoperation baselines.
SLAC: Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL
Jun 07, 2025



Building capable household and industrial robots requires mastering the control of versatile, high-degree-of-freedom (DoF) systems such as mobile manipulators. While reinforcement learning (RL) holds promise for autonomously acquiring robot control policies, scaling it to high-DoF embodiments remains challenging. Direct RL in the real world demands both safe exploration and high sample efficiency, which are difficult to achieve in practice. Sim-to-real RL, on the other hand, is often brittle due to the reality gap. This paper introduces SLAC, a method that renders real-world RL feasible for complex embodiments by leveraging a low-fidelity simulator to pretrain a task-agnostic latent action space. SLAC trains this latent action space via a customized unsupervised skill discovery method designed to promote temporal abstraction, disentanglement, and safety, thereby facilitating efficient downstream learning. Once a latent action space is learned, SLAC uses it as the action interface for a novel off-policy RL algorithm to autonomously learn downstream tasks through real-world interactions. We evaluate SLAC against existing methods on a suite of bimanual mobile manipulation tasks, where it achieves state-of-the-art performance. Notably, SLAC learns contact-rich whole-body tasks in under an hour of real-world interactions, without relying on any demonstrations or hand-crafted behavior priors. More information, code, and videos at robo-rl.github.io
DataMIL: Selecting Data for Robot Imitation Learning with Datamodels
May 14, 2025
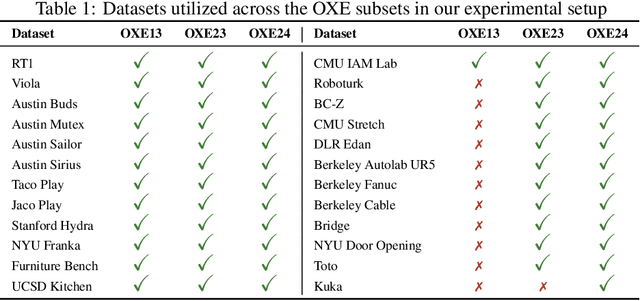


Recently, the robotics community has amassed ever larger and more diverse datasets to train generalist robot policies. However, while these policies achieve strong mean performance across a variety of tasks, they often underperform on individual, specialized tasks and require further tuning on newly acquired task-specific data. Combining task-specific data with carefully curated subsets of large prior datasets via co-training can produce better specialized policies, but selecting data naively may actually harm downstream performance. To address this, we introduce DataMIL, a policy-driven data selection framework built on the datamodels paradigm that reasons about data selection in an end-to-end manner, using the policy itself to identify which data points will most improve performance. Unlike standard practices that filter data using human notions of quality (e.g., based on semantic or visual similarity), DataMIL directly optimizes data selection for task success, allowing us to select data that enhance the policy while dropping data that degrade it. To avoid performing expensive rollouts in the environment during selection, we use a novel surrogate loss function on task-specific data, allowing us to use DataMIL in the real world without degrading performance. We validate our approach on a suite of more than 60 simulation and real-world manipulation tasks - most notably showing successful data selection from the Open X-Embodiment datasets-demonstrating consistent gains in success rates and superior performance over multiple baselines. Our results underscore the importance of end-to-end, performance-aware data selection for unlocking the potential of large prior datasets in robotics. More information at https://robin-lab.cs.utexas.edu/datamodels4imitation/