 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Small-to-Large Generalization: Data Influences Models Consistently Across Scale
May 22, 2025Choice of training data distribution greatly influences model behavior. Yet, in large-scale settings, precisely characterizing how changes in training data affects predictions is often difficult due to model training costs. Current practice is to instead extrapolate from scaled down, inexpensive-to-train proxy models. However, changes in data do not influence smaller and larger models identically. Therefore, understanding how choice of data affects large-scale models raises the question: how does training data distribution influence model behavior across compute scale? We find that small- and large-scale language model predictions (generally) do highly correlate across choice of training data. Equipped with these findings, we characterize how proxy scale affects effectiveness in two downstream proxy model applications: data attribution and dataset selection.
DataMIL: Selecting Data for Robot Imitation Learning with Datamodels
May 14, 2025
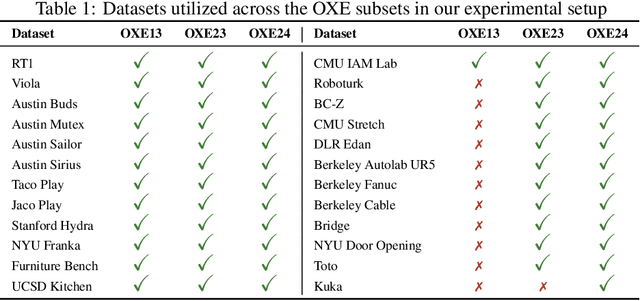


Recently, the robotics community has amassed ever larger and more diverse datasets to train generalist robot policies. However, while these policies achieve strong mean performance across a variety of tasks, they often underperform on individual, specialized tasks and require further tuning on newly acquired task-specific data. Combining task-specific data with carefully curated subsets of large prior datasets via co-training can produce better specialized policies, but selecting data naively may actually harm downstream performance. To address this, we introduce DataMIL, a policy-driven data selection framework built on the datamodels paradigm that reasons about data selection in an end-to-end manner, using the policy itself to identify which data points will most improve performance. Unlike standard practices that filter data using human notions of quality (e.g., based on semantic or visual similarity), DataMIL directly optimizes data selection for task success, allowing us to select data that enhance the policy while dropping data that degrade it. To avoid performing expensive rollouts in the environment during selection, we use a novel surrogate loss function on task-specific data, allowing us to use DataMIL in the real world without degrading performance. We validate our approach on a suite of more than 60 simulation and real-world manipulation tasks - most notably showing successful data selection from the Open X-Embodiment datasets-demonstrating consistent gains in success rates and superior performance over multiple baselines. Our results underscore the importance of end-to-end, performance-aware data selection for unlocking the potential of large prior datasets in robotics. More information at https://robin-lab.cs.utexas.edu/datamodels4imitation/
MAGIC: Near-Optimal Data Attribution for Deep Learning
Apr 23, 2025



The goal of predictive data attribution is to estimate how adding or removing a given set of training datapoints will affect model predictions. In convex settings, this goal is straightforward (i.e., via the infinitesimal jackknife). In large-scale (non-convex) settings, however, existing methods are far less successful -- current methods' estimates often only weakly correlate with ground truth. In this work, we present a new data attribution method (MAGIC) that combines classical methods and recent advances in metadifferentiation to (nearly) optimally estimate the effect of adding or removing training data on model predictions.
Optimizing ML Training with Metagradient Descent
Mar 17, 2025A major challenge in training large-scale machine learning models is configuring the training process to maximize model performance, i.e., finding the best training setup from a vast design space. In this work, we unlock a gradient-based approach to this problem. We first introduce an algorithm for efficiently calculating metagradients -- gradients through model training -- at scale. We then introduce a "smooth model training" framework that enables effective optimization using metagradients. With metagradient descent (MGD), we greatly improve on existing dataset selection methods, outperform accuracy-degrading data poisoning attacks by an order of magnitude, and automatically find competitive learning rate schedules.
DsDm: Model-Aware Dataset Selection with Datamodels
Jan 23, 2024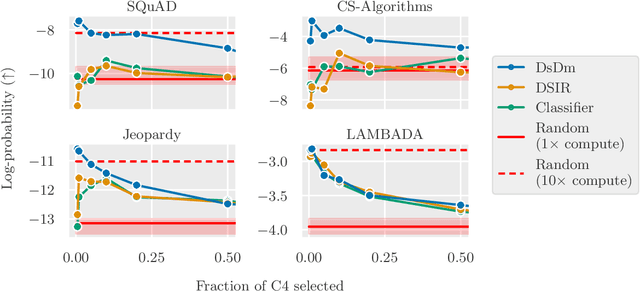



When selecting data for training large-scale models, standard practice is to filter for examples that match human notions of data quality. Such filtering yields qualitatively clean datapoints that intuitively should improve model behavior. However, in practice the opposite can often happen: we find that selecting according to similarity with "high quality" data sources may not increase (and can even hurt) performance compared to randomly selecting data. To develop better methods for selecting data, we start by framing dataset selection as an optimization problem that we can directly solve for: given target tasks, a learning algorithm, and candidate data, select the subset that maximizes model performance. This framework thus avoids handpicked notions of data quality, and instead models explicitly how the learning process uses train datapoints to predict on the target tasks. Our resulting method greatly improves language model (LM) performance on both pre-specified tasks and previously unseen tasks. Specifically, choosing target tasks representative of standard LM problems and evaluating on diverse held-out benchmarks, our selected datasets provide a 2x compute multiplier over baseline methods.
FFCV: Accelerating Training by Removing Data Bottlenecks
Jun 21, 2023



We present FFCV, a library for easy and fast machine learning model training. FFCV speeds up model training by eliminating (often subtle) data bottlenecks from the training process. In particular, we combine techniques such as an efficient file storage format, caching, data pre-loading, asynchronous data transfer, and just-in-time compilation to (a) make data loading and transfer significantly more efficient, ensuring that GPUs can reach full utilization; and (b) offload as much data processing as possible to the CPU asynchronously, freeing GPU cycles for training. Using FFCV, we train ResNet-18 and ResNet-50 on the ImageNet dataset with competitive tradeoff between accuracy and training time. For example, we are able to train an ImageNet ResNet-50 model to 75\% in only 20 mins on a single machine. We demonstrate FFCV's performance, ease-of-use, extensibility, and ability to adapt to resource constraints through several case studies. Detailed installation instructions, documentation, and Slack support channel are available at https://ffcv.io/ .
Dataset Interfaces: Diagnosing Model Failures Using Controllable Counterfactual Generation
Feb 15, 2023Distribution shifts are a major source of failure of deployed machine learning models. However, evaluating a model's reliability under distribution shifts can be challenging, especially since it may be difficult to acquire counterfactual examples that exhibit a specified shift. In this work, we introduce dataset interfaces: a framework which allows users to scalably synthesize such counterfactual examples from a given dataset. Specifically, we represent each class from the input dataset as a custom token within the text space of a text-to-image diffusion model. By incorporating these tokens into natural language prompts, we can then generate instantiations of objects in that dataset under desired distribution shifts. We demonstrate how applying our framework to the ImageNet dataset enables us to study model behavior across a diverse array of shifts, including variations in background, lighting, and attributes of the objects themselves. Code available at https://github.com/MadryLab/dataset-interfaces.
When does Bias Transfer in Transfer Learning?
Jul 06, 2022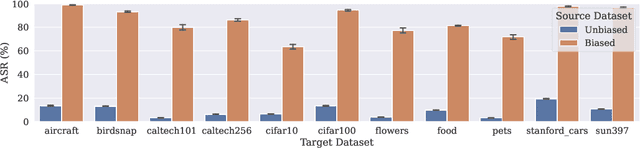
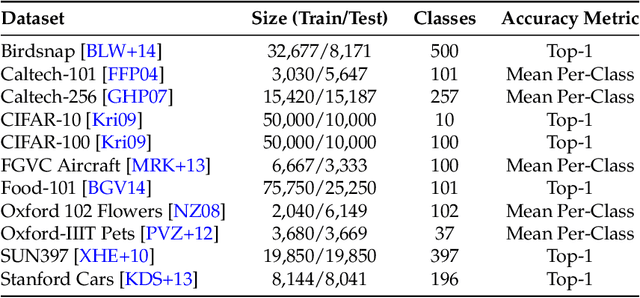
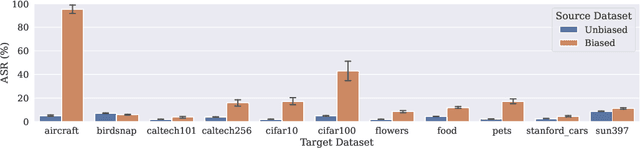

Using transfer learning to adapt a pre-trained "source model" to a downstream "target task" can dramatically increase performance with seemingly no downside. In this work, we demonstrate that there can exist a downside after all: bias transfer, or the tendency for biases of the source model to persist even after adapting the model to the target class. Through a combination of synthetic and natural experiments, we show that bias transfer both (a) arises in realistic settings (such as when pre-training on ImageNet or other standard datasets) and (b) can occur even when the target dataset is explicitly de-biased. As transfer-learned models are increasingly deployed in the real world, our work highlights the importance of understanding the limitations of pre-trained source models. Code is available at https://github.com/MadryLab/bias-transfer
Datamodels: Predicting Predictions from Training Data
Feb 01, 2022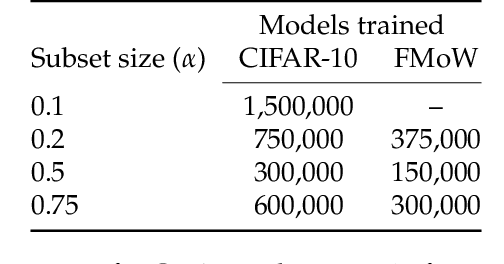


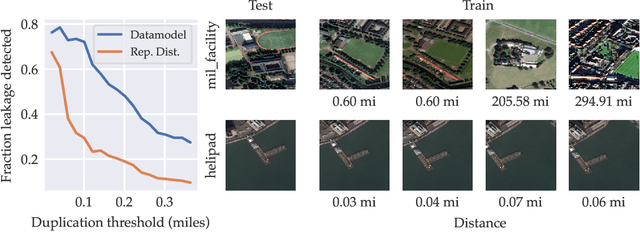
We present a conceptual framework, datamodeling, for analyzing the behavior of a model class in terms of the training data. For any fixed "target" example $x$, training set $S$, and learning algorithm, a datamodel is a parameterized function $2^S \to \mathbb{R}$ that for any subset of $S' \subset S$ -- using only information about which examples of $S$ are contained in $S'$ -- predicts the outcome of training a model on $S'$ and evaluating on $x$. Despite the potential complexity of the underlying process being approximated (e.g., end-to-end training and evaluation of deep neural networks), we show that even simple linear datamodels can successfully predict model outputs. We then demonstrate that datamodels give rise to a variety of applications, such as: accurately predicting the effect of dataset counterfactuals; identifying brittle predictions; finding semantically similar examples; quantifying train-test leakage; and embedding data into a well-behaved and feature-rich representation space. Data for this paper (including pre-computed datamodels as well as raw predictions from four million trained deep neural networks) is available at https://github.com/MadryLab/datamodels-data .