 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-Con: A Unifying Framework for Representation Learning
Apr 23, 2025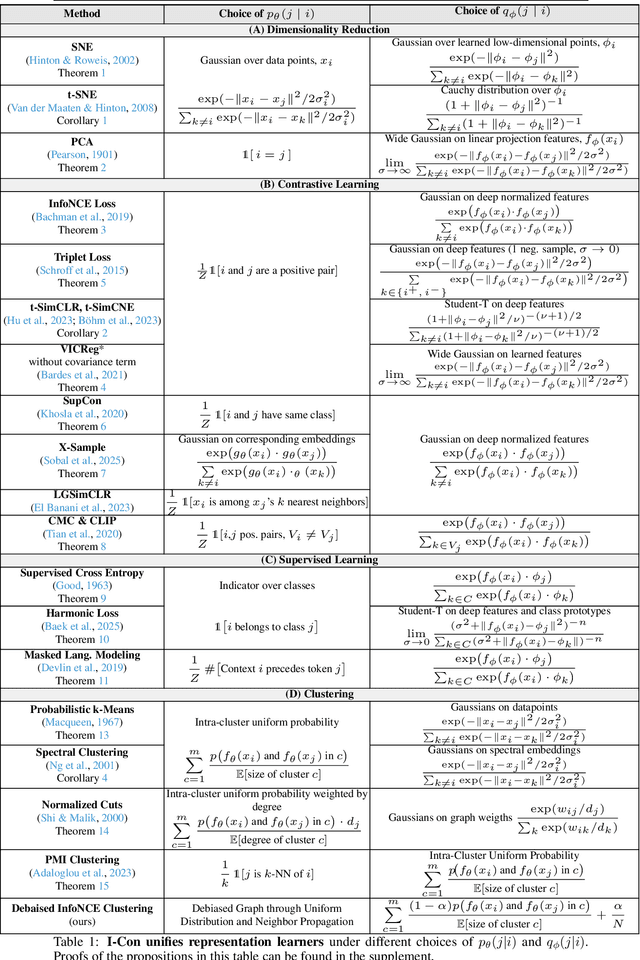
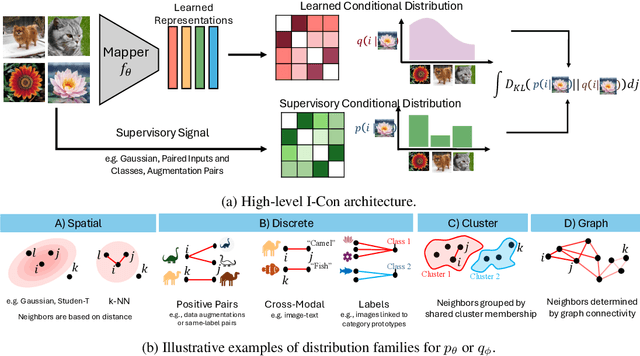
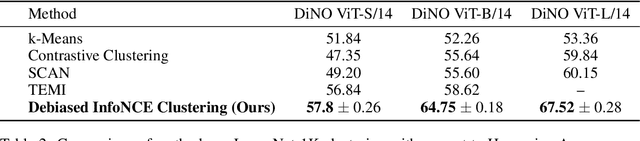
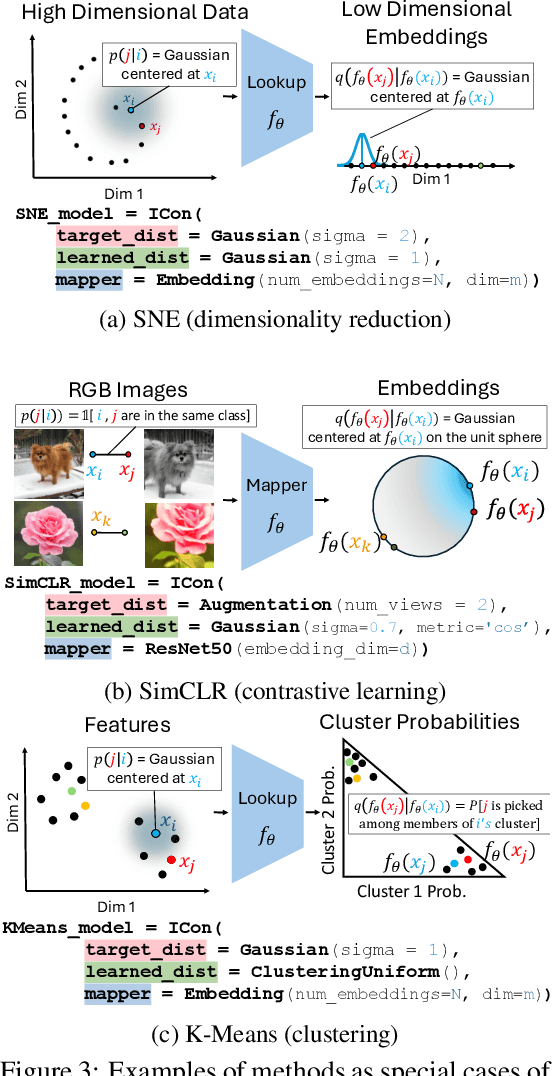
As the field of representation learning grows, there has been a proliferation of different loss functions to solve different classes of problems. We introduce a single information-theoretic equation that generalizes a large collection of modern loss functions in machine learning. In particular, we introduce a framework that shows that several broad classes of machine learning methods are precisely minimizing an integrated KL divergence between two conditional distributions: the supervisory and learned representations. This viewpoint exposes a hidden information geometry underlying clustering, spectral methods, dimensionality reduction, contrastive learning, and supervised learning. This framework enables the development of new loss functions by combining successful techniques from across the literature. We not only present a wide array of proofs, connecting over 23 different approaches, but we also leverage these theoretical results to create state-of-the-art unsupervised image classifiers that achieve a +8% improvement over the prior state-of-the-art on unsupervised classification on ImageNet-1K. We also demonstrate that I-Con can be used to derive principled debiasing methods which improve contrastive representation learners.
Optimizing ML Training with Metagradient Descent
Mar 17, 2025A major challenge in training large-scale machine learning models is configuring the training process to maximize model performance, i.e., finding the best training setup from a vast design space. In this work, we unlock a gradient-based approach to this problem. We first introduce an algorithm for efficiently calculating metagradients -- gradients through model training -- at scale. We then introduce a "smooth model training" framework that enables effective optimization using metagradients. With metagradient descent (MGD), we greatly improve on existing dataset selection methods, outperform accuracy-degrading data poisoning attacks by an order of magnitude, and automatically find competitive learning rate schedules.
DsDm: Model-Aware Dataset Selection with Datamodels
Jan 23, 2024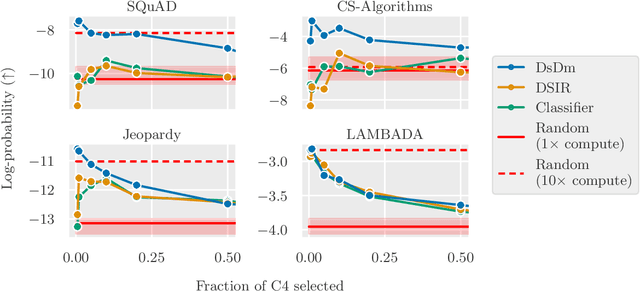



When selecting data for training large-scale models, standard practice is to filter for examples that match human notions of data quality. Such filtering yields qualitatively clean datapoints that intuitively should improve model behavior. However, in practice the opposite can often happen: we find that selecting according to similarity with "high quality" data sources may not increase (and can even hurt) performance compared to randomly selecting data. To develop better methods for selecting data, we start by framing dataset selection as an optimization problem that we can directly solve for: given target tasks, a learning algorithm, and candidate data, select the subset that maximizes model performance. This framework thus avoids handpicked notions of data quality, and instead models explicitly how the learning process uses train datapoints to predict on the target tasks. Our resulting method greatly improves language model (LM) performance on both pre-specified tasks and previously unseen tasks. Specifically, choosing target tasks representative of standard LM problems and evaluating on diverse held-out benchmarks, our selected datasets provide a 2x compute multiplier over baseline methods.