 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJustified or Just Convincing? Error Verifiability as a Dimension of LLM Quality
Apr 06, 2026As LLMs are deployed in high-stakes settings, users must judge the correctness of individual responses, often relying on model-generated justifications such as reasoning chains or explanations. Yet, no standard measure exists for whether these justifications help users distinguish correct answers from incorrect ones. We formalize this idea as error verifiability and propose $v_{\text{bal}}$, a balanced metric that measures whether justifications enable raters to accurately assess answer correctness, validated against human raters who show high agreement. We find that neither common approaches, such as post-training and model scaling, nor more targeted interventions recommended improve verifiability. We introduce two methods that succeed at improving verifiability: reflect-and-rephrase (RR) for mathematical reasoning and oracle-rephrase (OR) for factual QA, both of which improve verifiability by incorporating domain-appropriate external information. Together, our results establish error verifiability as a distinct dimension of response quality that does not emerge from accuracy improvements alone and requires dedicated, domain-aware methods to address.
Probably Approximately Correct Labels
Jun 12, 2025



Obtaining high-quality labeled datasets is often costly, requiring either extensive human annotation or expensive experiments. We propose a method that supplements such "expert" labels with AI predictions from pre-trained models to construct labeled datasets more cost-effectively. Our approach results in probably approximately correct labels: with high probability, the overall labeling error is small. This solution enables rigorous yet efficient dataset curation using modern AI models. We demonstrate the benefits of the methodology through text annotation with large language models, image labeling with pre-trained vision models, and protein folding analysis with AlphaFold.
DataMIL: Selecting Data for Robot Imitation Learning with Datamodels
May 14, 2025
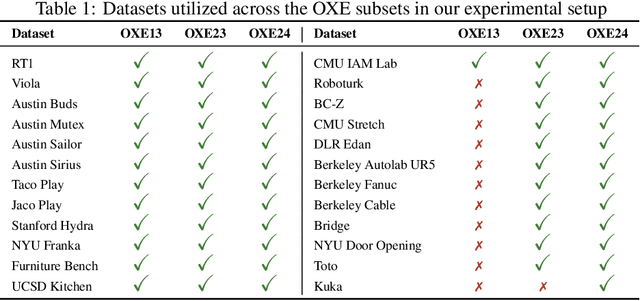


Recently, the robotics community has amassed ever larger and more diverse datasets to train generalist robot policies. However, while these policies achieve strong mean performance across a variety of tasks, they often underperform on individual, specialized tasks and require further tuning on newly acquired task-specific data. Combining task-specific data with carefully curated subsets of large prior datasets via co-training can produce better specialized policies, but selecting data naively may actually harm downstream performance. To address this, we introduce DataMIL, a policy-driven data selection framework built on the datamodels paradigm that reasons about data selection in an end-to-end manner, using the policy itself to identify which data points will most improve performance. Unlike standard practices that filter data using human notions of quality (e.g., based on semantic or visual similarity), DataMIL directly optimizes data selection for task success, allowing us to select data that enhance the policy while dropping data that degrade it. To avoid performing expensive rollouts in the environment during selection, we use a novel surrogate loss function on task-specific data, allowing us to use DataMIL in the real world without degrading performance. We validate our approach on a suite of more than 60 simulation and real-world manipulation tasks - most notably showing successful data selection from the Open X-Embodiment datasets-demonstrating consistent gains in success rates and superior performance over multiple baselines. Our results underscore the importance of end-to-end, performance-aware data selection for unlocking the potential of large prior datasets in robotics. More information at https://robin-lab.cs.utexas.edu/datamodels4imitation/
AI Supply Chains: An Emerging Ecosystem of AI Actors, Products, and Services
Apr 28, 2025The widespread adoption of AI in recent years has led to the emergence of AI supply chains: complex networks of AI actors contributing models, datasets, and more to the development of AI products and services. AI supply chains have many implications yet are poorly understood. In this work, we take a first step toward a formal study of AI supply chains and their implications, providing two illustrative case studies indicating that both AI development and regulation are complicated in the presence of supply chains. We begin by presenting a brief historical perspective on AI supply chains, discussing how their rise reflects a longstanding shift towards specialization and outsourcing that signals the healthy growth of the AI industry. We then model AI supply chains as directed graphs and demonstrate the power of this abstraction by connecting examples of AI issues to graph properties. Finally, we examine two case studies in detail, providing theoretical and empirical results in both. In the first, we show that information passing (specifically, of explanations) along the AI supply chains is imperfect, which can result in misunderstandings that have real-world implications. In the second, we show that upstream design choices (e.g., by base model providers) have downstream consequences (e.g., on AI products fine-tuned on the base model). Together, our findings motivate further study of AI supply chains and their increasingly salient social, economic, regulatory, and technical implications.
MAGIC: Near-Optimal Data Attribution for Deep Learning
Apr 23, 2025



The goal of predictive data attribution is to estimate how adding or removing a given set of training datapoints will affect model predictions. In convex settings, this goal is straightforward (i.e., via the infinitesimal jackknife). In large-scale (non-convex) settings, however, existing methods are far less successful -- current methods' estimates often only weakly correlate with ground truth. In this work, we present a new data attribution method (MAGIC) that combines classical methods and recent advances in metadifferentiation to (nearly) optimally estimate the effect of adding or removing training data on model predictions.
Optimizing ML Training with Metagradient Descent
Mar 17, 2025A major challenge in training large-scale machine learning models is configuring the training process to maximize model performance, i.e., finding the best training setup from a vast design space. In this work, we unlock a gradient-based approach to this problem. We first introduce an algorithm for efficiently calculating metagradients -- gradients through model training -- at scale. We then introduce a "smooth model training" framework that enables effective optimization using metagradients. With metagradient descent (MGD), we greatly improve on existing dataset selection methods, outperform accuracy-degrading data poisoning attacks by an order of magnitude, and automatically find competitive learning rate schedules.
Attribute-to-Delete: Machine Unlearning via Datamodel Matching
Oct 30, 2024



Machine unlearning -- efficiently removing the effect of a small "forget set" of training data on a pre-trained machine learning model -- has recently attracted significant research interest. Despite this interest, however, recent work shows that existing machine unlearning techniques do not hold up to thorough evaluation in non-convex settings. In this work, we introduce a new machine unlearning technique that exhibits strong empirical performance even in such challenging settings. Our starting point is the perspective that the goal of unlearning is to produce a model whose outputs are statistically indistinguishable from those of a model re-trained on all but the forget set. This perspective naturally suggests a reduction from the unlearning problem to that of data attribution, where the goal is to predict the effect of changing the training set on a model's outputs. Thus motivated, we propose the following meta-algorithm, which we call Datamodel Matching (DMM): given a trained model, we (a) use data attribution to predict the output of the model if it were re-trained on all but the forget set points; then (b) fine-tune the pre-trained model to match these predicted outputs. In a simple convex setting, we show how this approach provably outperforms a variety of iterative unlearning algorithms. Empirically, we use a combination of existing evaluations and a new metric based on the KL-divergence to show that even in non-convex settings, DMM achieves strong unlearning performance relative to existing algorithms. An added benefit of DMM is that it is a meta-algorithm, in the sense that future advances in data attribution translate directly into better unlearning algorithms, pointing to a clear direction for future progress in unlearning.
Data Debiasing with Datamodels (D3M): Improving Subgroup Robustness via Data Selection
Jun 24, 2024Machine learning models can fail on subgroups that are underrepresented during training. While techniques such as dataset balancing can improve performance on underperforming groups, they require access to training group annotations and can end up removing large portions of the dataset. In this paper, we introduce Data Debiasing with Datamodels (D3M), a debiasing approach which isolates and removes specific training examples that drive the model's failures on minority groups. Our approach enables us to efficiently train debiased classifiers while removing only a small number of examples, and does not require training group annotations or additional hyperparameter tuning.
Measuring Strategization in Recommendation: Users Adapt Their Behavior to Shape Future Content
May 09, 2024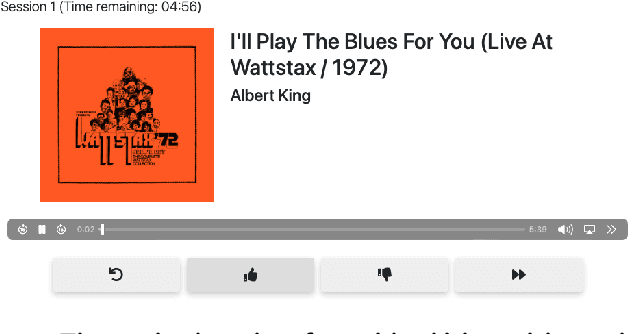



Most modern recommendation algorithms are data-driven: they generate personalized recommendations by observing users' past behaviors. A common assumption in recommendation is that how a user interacts with a piece of content (e.g., whether they choose to "like" it) is a reflection of the content, but not of the algorithm that generated it. Although this assumption is convenient, it fails to capture user strategization: that users may attempt to shape their future recommendations by adapting their behavior to the recommendation algorithm. In this work, we test for user strategization by conducting a lab experiment and survey. To capture strategization, we adopt a model in which strategic users select their engagement behavior based not only on the content, but also on how their behavior affects downstream recommendations. Using a custom music player that we built, we study how users respond to different information about their recommendation algorithm as well as to different incentives about how their actions affect downstream outcomes. We find strong evidence of strategization across outcome metrics, including participants' dwell time and use of "likes." For example, participants who are told that the algorithm mainly pays attention to "likes" and "dislikes" use those functions 1.9x more than participants told that the algorithm mainly pays attention to dwell time. A close analysis of participant behavior (e.g., in response to our incentive conditions) rules out experimenter demand as the main driver of these trends. Further, in our post-experiment survey, nearly half of participants self-report strategizing "in the wild," with some stating that they ignore content they actually like to avoid over-recommendation of that content in the future. Together, our findings suggest that user strategization is common and that platforms cannot ignore the effect of their algorithms on user behavior.
Decomposing and Editing Predictions by Modeling Model Computation
Apr 17, 2024



How does the internal computation of a machine learning model transform inputs into predictions? In this paper, we introduce a task called component modeling that aims to address this question. The goal of component modeling is to decompose an ML model's prediction in terms of its components -- simple functions (e.g., convolution filters, attention heads) that are the "building blocks" of model computation. We focus on a special case of this task, component attribution, where the goal is to estimate the counterfactual impact of individual components on a given prediction. We then present COAR, a scalable algorithm for estimating component attributions; we demonstrate its effectiveness across models, datasets, and modalities. Finally, we show that component attributions estimated with COAR directly enable model editing across five tasks, namely: fixing model errors, ``forgetting'' specific classes, boosting subpopulation robustness, localizing backdoor attacks, and improving robustness to typographic attacks. We provide code for COAR at https://github.com/MadryLab/modelcomponents .