 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
Attribute-to-Delete: Machine Unlearning via Datamodel Matching
Oct 30, 2024



Machine unlearning -- efficiently removing the effect of a small "forget set" of training data on a pre-trained machine learning model -- has recently attracted significant research interest. Despite this interest, however, recent work shows that existing machine unlearning techniques do not hold up to thorough evaluation in non-convex settings. In this work, we introduce a new machine unlearning technique that exhibits strong empirical performance even in such challenging settings. Our starting point is the perspective that the goal of unlearning is to produce a model whose outputs are statistically indistinguishable from those of a model re-trained on all but the forget set. This perspective naturally suggests a reduction from the unlearning problem to that of data attribution, where the goal is to predict the effect of changing the training set on a model's outputs. Thus motivated, we propose the following meta-algorithm, which we call Datamodel Matching (DMM): given a trained model, we (a) use data attribution to predict the output of the model if it were re-trained on all but the forget set points; then (b) fine-tune the pre-trained model to match these predicted outputs. In a simple convex setting, we show how this approach provably outperforms a variety of iterative unlearning algorithms. Empirically, we use a combination of existing evaluations and a new metric based on the KL-divergence to show that even in non-convex settings, DMM achieves strong unlearning performance relative to existing algorithms. An added benefit of DMM is that it is a meta-algorithm, in the sense that future advances in data attribution translate directly into better unlearning algorithms, pointing to a clear direction for future progress in unlearning.
Machine Unlearning Fails to Remove Data Poisoning Attacks
Jun 25, 2024We revisit the efficacy of several practical methods for approximate machine unlearning developed for large-scale deep learning. In addition to complying with data deletion requests, one often-cited potential application for unlearning methods is to remove the effects of training on poisoned data. We experimentally demonstrate that, while existing unlearning methods have been demonstrated to be effective in a number of evaluation settings (e.g., alleviating membership inference attacks), they fail to remove the effects of data poisoning, across a variety of types of poisoning attacks (indiscriminate, targeted, and a newly-introduced Gaussian poisoning attack) and models (image classifiers and LLMs); even when granted a relatively large compute budget. In order to precisely characterize unlearning efficacy, we introduce new evaluation metrics for unlearning based on data poisoning. Our results suggest that a broader perspective, including a wider variety of evaluations, is required to avoid a false sense of confidence in machine unlearning procedures for deep learning without provable guarantees. Moreover, while unlearning methods show some signs of being useful to efficiently remove poisoned datapoints without having to retrain, our work suggests that these methods are not yet "ready for prime time", and currently provide limited benefit over retraining.
Pandora's White-Box: Increased Training Data Leakage in Open LLMs
Feb 26, 2024In this paper we undertake a systematic study of privacy attacks against open source Large Language Models (LLMs), where an adversary has access to either the model weights, gradients, or losses, and tries to exploit them to learn something about the underlying training data. Our headline results are the first membership inference attacks (MIAs) against pre-trained LLMs that are able to simultaneously achieve high TPRs and low FPRs, and a pipeline showing that over $50\%$ (!) of the fine-tuning dataset can be extracted from a fine-tuned LLM in natural settings. We consider varying degrees of access to the underlying model, customization of the language model, and resources available to the attacker. In the pre-trained setting, we propose three new white-box MIAs: an attack based on the gradient norm, a supervised neural network classifier, and a single step loss ratio attack. All outperform existing black-box baselines, and our supervised attack closes the gap between MIA attack success against LLMs and other types of models. In fine-tuning, we find that given access to the loss of the fine-tuned and base models, a fine-tuned loss ratio attack FLoRA is able to achieve near perfect MIA peformance. We then leverage these MIAs to extract fine-tuning data from fine-tuned language models. We find that the pipeline of generating from fine-tuned models prompted with a small snippet of the prefix of each training example, followed by using FLoRa to select the most likely training sample, succeeds the majority of the fine-tuning dataset after only $3$ epochs of fine-tuning. Taken together, these findings show that highly effective MIAs are available in almost all LLM training settings, and highlight that great care must be taken before LLMs are fine-tuned on highly sensitive data and then deployed.
Privacy Issues in Large Language Models: A Survey
Dec 11, 2023This is the first survey of the active area of AI research that focuses on privacy issues in Large Language Models (LLMs). Specifically, we focus on work that red-teams models to highlight privacy risks, attempts to build privacy into the training or inference process, enables efficient data deletion from trained models to comply with existing privacy regulations, and tries to mitigate copyright issues. Our focus is on summarizing technical research that develops algorithms, proves theorems, and runs empirical evaluations. While there is an extensive body of legal and policy work addressing these challenges from a different angle, that is not the focus of our survey. Nevertheless, these works, along with recent legal developments do inform how these technical problems are formalized, and so we discuss them briefly in Section 1. While we have made our best effort to include all the relevant work, due to the fast moving nature of this research we may have missed some recent work. If we have missed some of your work please contact us, as we will attempt to keep this survey relatively up to date. We are maintaining a repository with the list of papers covered in this survey and any relevant code that was publicly available at https://github.com/safr-ml-lab/survey-llm.
MoPe: Model Perturbation-based Privacy Attacks on Language Models
Oct 22, 2023Recent work has shown that Large Language Models (LLMs) can unintentionally leak sensitive information present in their training data. In this paper, we present Model Perturbations (MoPe), a new method to identify with high confidence if a given text is in the training data of a pre-trained language model, given white-box access to the models parameters. MoPe adds noise to the model in parameter space and measures the drop in log-likelihood at a given point $x$, a statistic we show approximates the trace of the Hessian matrix with respect to model parameters. Across language models ranging from $70$M to $12$B parameters, we show that MoPe is more effective than existing loss-based attacks and recently proposed perturbation-based methods. We also examine the role of training point order and model size in attack success, and empirically demonstrate that MoPe accurately approximate the trace of the Hessian in practice. Our results show that the loss of a point alone is insufficient to determine extractability -- there are training points we can recover using our method that have average loss. This casts some doubt on prior works that use the loss of a point as evidence of memorization or unlearning.
Black-Box Training Data Identification in GANs via Detector Networks
Oct 18, 2023Since their inception Generative Adversarial Networks (GANs) have been popular generative models across images, audio, video, and tabular data. In this paper we study whether given access to a trained GAN, as well as fresh samples from the underlying distribution, if it is possible for an attacker to efficiently identify if a given point is a member of the GAN's training data. This is of interest for both reasons related to copyright, where a user may want to determine if their copyrighted data has been used to train a GAN, and in the study of data privacy, where the ability to detect training set membership is known as a membership inference attack. Unlike the majority of prior work this paper investigates the privacy implications of using GANs in black-box settings, where the attack only has access to samples from the generator, rather than access to the discriminator as well. We introduce a suite of membership inference attacks against GANs in the black-box setting and evaluate our attacks on image GANs trained on the CIFAR10 dataset and tabular GANs trained on genomic data. Our most successful attack, called The Detector, involve training a second network to score samples based on their likelihood of being generated by the GAN, as opposed to a fresh sample from the distribution. We prove under a simple model of the generator that the detector is an approximately optimal membership inference attack. Across a wide range of tabular and image datasets, attacks, and GAN architectures, we find that adversaries can orchestrate non-trivial privacy attacks when provided with access to samples from the generator. At the same time, the attack success achievable against GANs still appears to be lower compared to other generative and discriminative models; this leaves the intriguing open question of whether GANs are in fact more private, or if it is a matter of developing stronger attacks.
In-Context Unlearning: Language Models as Few Shot Unlearners
Oct 12, 2023Machine unlearning, the study of efficiently removing the impact of specific training points on the trained model, has garnered increased attention of late, driven by the need to comply with privacy regulations like the Right to be Forgotten. Although unlearning is particularly relevant for LLMs in light of the copyright issues they raise, achieving precise unlearning is computationally infeasible for very large models. To this end, recent work has proposed several algorithms which approximate the removal of training data without retraining the model. These algorithms crucially rely on access to the model parameters in order to update them, an assumption that may not hold in practice due to computational constraints or when the LLM is accessed via API. In this work, we propose a new class of unlearning methods for LLMs we call ''In-Context Unlearning'', providing inputs in context and without having to update model parameters. To unlearn a particular training instance, we provide the instance alongside a flipped label and additional correctly labelled instances which are prepended as inputs to the LLM at inference time. Our experimental results demonstrate that these contexts effectively remove specific information from the training set while maintaining performance levels that are competitive with (or in some cases exceed) state-of-the-art unlearning methods that require access to the LLM parameters.
PRIMO: Private Regression in Multiple Outcomes
Mar 07, 2023
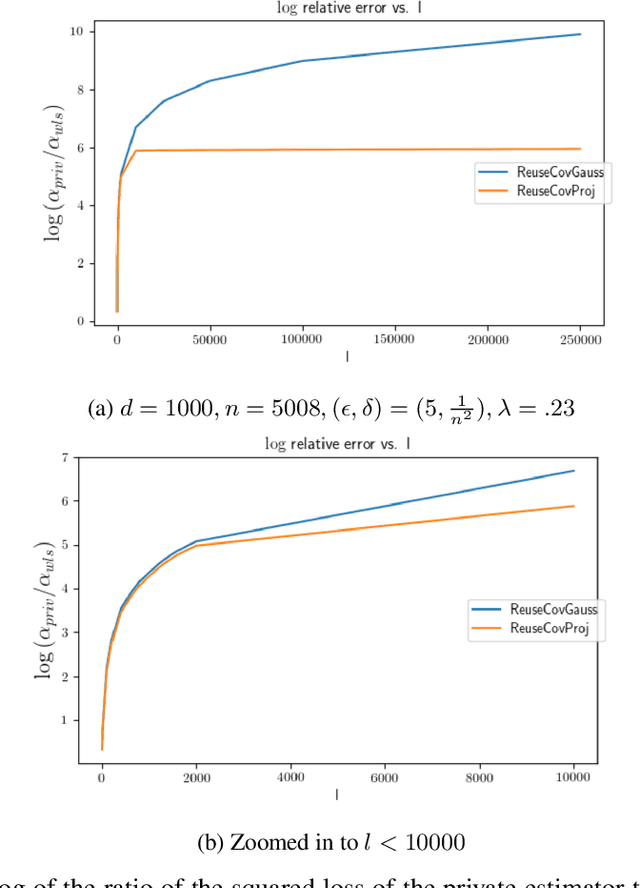
We introduce a new differentially private regression setting we call Private Regression in Multiple Outcomes (PRIMO), inspired the common situation where a data analyst wants to perform a set of $l$ regressions while preserving privacy, where the covariates $X$ are shared across all $l$ regressions, and each regression $i \in [l]$ has a different vector of outcomes $y_i$. While naively applying private linear regression techniques $l$ times leads to a $\sqrt{l}$ multiplicative increase in error over the standard linear regression setting, in Subsection $4.1$ we modify techniques based on sufficient statistics perturbation (SSP) to yield greatly improved dependence on $l$. In Subsection $4.2$ we prove an equivalence to the problem of privately releasing the answers to a special class of low-sensitivity queries we call inner product queries. Via this equivalence, we adapt the geometric projection-based methods from prior work on private query release to the PRIMO setting. Under the assumption the labels $Y$ are public, the projection gives improved results over the Gaussian mechanism when $n < l\sqrt{d}$, with no asymptotic dependence on $l$ in the error. In Subsection $4.3$ we study the complexity of our projection algorithm, and analyze a faster sub-sampling based variant in Subsection $4.4$. Finally in Section $5$ we apply our algorithms to the task of private genomic risk prediction for multiple phenotypes using data from the 1000 Genomes project. We find that for moderately large values of $l$ our techniques drastically improve the accuracy relative to both the naive baseline that uses existing private regression methods and our modified SSP algorithm that doesn't use the projection.
Model Explanation Disparities as a Fairness Diagnostic
Mar 06, 2023In recent years, there has been a flurry of research focusing on the fairness of machine learning models, and in particular on quantifying and eliminating bias against protected subgroups. One line of work generalizes the notion of protected subgroups beyond simple discrete classes by introducing the notion of a "rich subgroup", and seeks to train models that are calibrated or equalize error rates with respect to these richer subgroup classes. Largely orthogonally, local model explanation methods have been developed that given a classifier h and test point x, attribute influence for the prediction h(x) to the individual features of x. This raises a natural question: Do local model explanation methods attribute different feature importance values on average across different protected subgroups, and can we detect these disparities efficiently? If the model places high weight on a given feature in a specific protected subgroup, but not on the dataset overall (or vice versa), this could be a potential indicator of bias in the predictive model or the underlying data generating process, and is at the very least a useful diagnostic that signals the need for a domain expert to delve deeper. In this paper, we formally introduce the notion of feature importance disparity (FID) in the context of rich subgroups, design oracle-efficent algorithms to identify large FID subgroups, and conduct a thorough empirical analysis that establishes auditing for FID as an important method to investigate dataset bias. Our experiments show that across 4 datasets and 4 common feature importance methods our algorithms find (feature, subgroup) pairs that simultaneously: (i) have subgroup feature importance that is often an order of magnitude different than the importance on the dataset as a whole (ii) generalize out of sample, and (iii) yield interesting discussions about potential bias inherent in these datasets.