 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan3.0 Flash: An Open Multimodal Large Language Model for Enterprise Applications
Jan 05, 2026We introduce Yuan3.0 Flash, an open-source Mixture-of-Experts (MoE) MultiModal Large Language Model featuring 3.7B activated parameters and 40B total parameters, specifically designed to enhance performance on enterprise-oriented tasks while maintaining competitive capabilities on general-purpose tasks. To address the overthinking phenomenon commonly observed in Large Reasoning Models (LRMs), we propose Reflection-aware Adaptive Policy Optimization (RAPO), a novel RL training algorithm that effectively regulates overthinking behaviors. In enterprise-oriented tasks such as retrieval-augmented generation (RAG), complex table understanding, and summarization, Yuan3.0 Flash consistently achieves superior performance. Moreover, it also demonstrates strong reasoning capabilities in domains such as mathematics, science, etc., attaining accuracy comparable to frontier model while requiring only approximately 1/4 to 1/2 of the average tokens. Yuan3.0 Flash has been fully open-sourced to facilitate further research and real-world deployment: https://github.com/Yuan-lab-LLM/Yuan3.0.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Automated Unit Test Case Generation: A Systematic Literature Review
Apr 29, 2025Software is omnipresent within all factors of society. It is thus important to ensure that software are well tested to mitigate bad user experiences as well as the potential for severe financial and human losses. Software testing is however expensive and absorbs valuable time and resources. As a result, the field of automated software testing has grown of interest to researchers in past decades. In our review of present and past research papers, we have identified an information gap in the areas of improvement for the Genetic Algorithm and Particle Swarm Optimisation. A gap in knowledge in the current challenges that face automated testing has also been identified. We therefore present this systematic literature review in an effort to consolidate existing knowledge in regards to the evolutionary approaches as well as their improvements and resulting limitations. These improvements include hybrid algorithm combinations as well as interoperability with mutation testing and neural networks. We will also explore the main test criterion that are used in these algorithms alongside the challenges currently faced in the field related to readability, mocking and more.
Towards Interpretable Soft Prompts
Apr 02, 2025Soft prompts have been popularized as a cheap and easy way to improve task-specific LLM performance beyond few-shot prompts. Despite their origin as an automated prompting method, however, soft prompts and other trainable prompts remain a black-box method with no immediately interpretable connections to prompting. We create a novel theoretical framework for evaluating the interpretability of trainable prompts based on two desiderata: faithfulness and scrutability. We find that existing methods do not naturally satisfy our proposed interpretability criterion. Instead, our framework inspires a new direction of trainable prompting methods that explicitly optimizes for interpretability. To this end, we formulate and test new interpretability-oriented objective functions for two state-of-the-art prompt tuners: Hard Prompts Made Easy (PEZ) and RLPrompt. Our experiments with GPT-2 demonstrate a fundamental trade-off between interpretability and the task-performance of the trainable prompt, explicating the hardness of the soft prompt interpretability problem and revealing odd behavior that arises when one optimizes for an interpretability proxy.
Scalable Indoor Novel-View Synthesis using Drone-Captured 360 Imagery with 3D Gaussian Splatting
Oct 15, 2024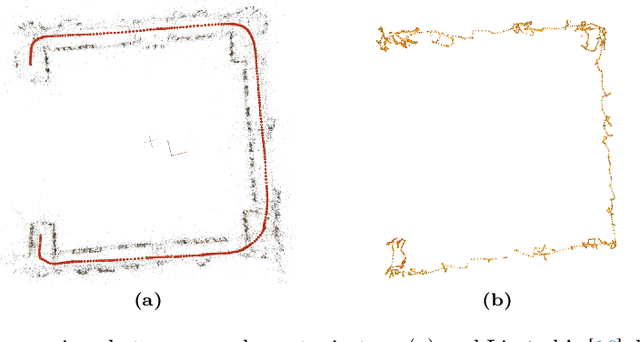

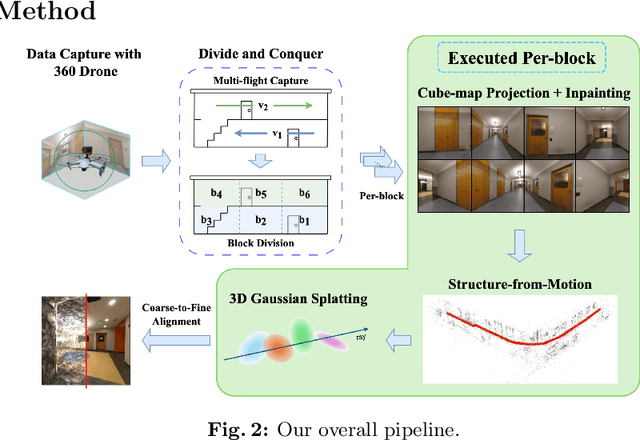
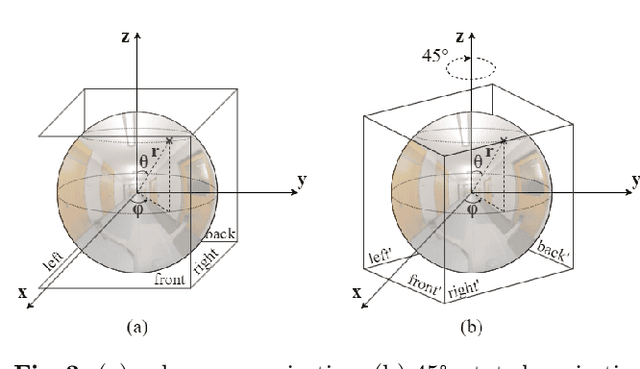
Scene reconstruction and novel-view synthesis for large, complex, multi-story, indoor scenes is a challenging and time-consuming task. Prior methods have utilized drones for data capture and radiance fields for scene reconstruction, both of which present certain challenges. First, in order to capture diverse viewpoints with the drone's front-facing camera, some approaches fly the drone in an unstable zig-zag fashion, which hinders drone-piloting and generates motion blur in the captured data. Secondly, most radiance field methods do not easily scale to arbitrarily large number of images. This paper proposes an efficient and scalable pipeline for indoor novel-view synthesis from drone-captured 360 videos using 3D Gaussian Splatting. 360 cameras capture a wide set of viewpoints, allowing for comprehensive scene capture under a simple straightforward drone trajectory. To scale our method to large scenes, we devise a divide-and-conquer strategy to automatically split the scene into smaller blocks that can be reconstructed individually and in parallel. We also propose a coarse-to-fine alignment strategy to seamlessly match these blocks together to compose the entire scene. Our experiments demonstrate marked improvement in both reconstruction quality, i.e. PSNR and SSIM, and computation time compared to prior approaches.
Understanding Warmup-Stable-Decay Learning Rates: A River Valley Loss Landscape Perspective
Oct 07, 2024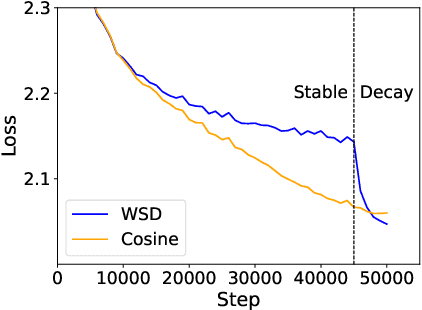

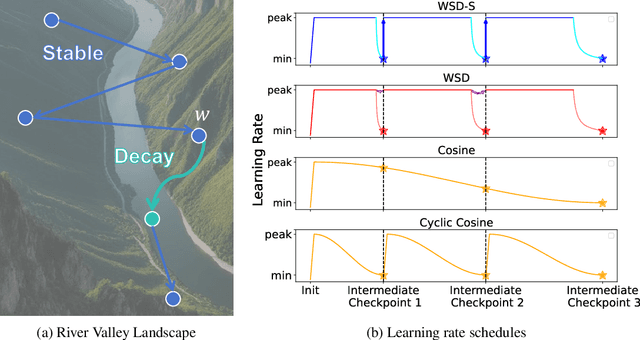
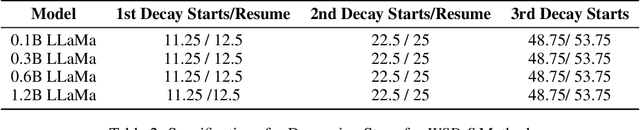
Training language models currently requires pre-determining a fixed compute budget because the typical cosine learning rate schedule depends on the total number of steps. In contrast, the Warmup-Stable-Decay (WSD) schedule uses a constant learning rate to produce a main branch of iterates that can in principle continue indefinitely without a pre-specified compute budget. Then, given any compute budget, one can branch out from the main branch at a proper at any time with a rapidly decaying learning rate to produce a strong model. Empirically, WSD generates a non-traditional loss curve: the loss remains elevated during the stable phase but sharply declines during the decay phase. Towards explaining this phenomenon, we conjecture that pretraining loss exhibits a river valley landscape, which resembles a deep valley with a river at its bottom. Under this assumption, we show that during the stable phase, the iterate undergoes large oscillations due to the high learning rate, yet it progresses swiftly along the river. During the decay phase, the rapidly dropping learning rate minimizes the iterate's oscillations, moving it closer to the river and revealing true optimization progress. Therefore, the sustained high learning rate phase and fast decaying phase are responsible for progress in the river and the mountain directions respectively, and are both critical. Our analysis predicts phenomenons consistent with empirical observations and shows that this landscape can emerge from pretraining on a simple bi-gram dataset. Inspired by the theory, we introduce WSD-S, a variant of WSD that reuses previous checkpoints' decay phases and keeps only one main branch, where we resume from a decayed checkpoint. WSD-S empirically outperforms WSD and Cyclic-Cosine in obtaining multiple language model checkpoints across various compute budgets in a single run for parameters scaling from 0.1B to 1.2B.
Hardness of Learning Neural Networks under the Manifold Hypothesis
Jun 03, 2024



The manifold hypothesis presumes that high-dimensional data lies on or near a low-dimensional manifold. While the utility of encoding geometric structure has been demonstrated empirically, rigorous analysis of its impact on the learnability of neural networks is largely missing. Several recent results have established hardness results for learning feedforward and equivariant neural networks under i.i.d. Gaussian or uniform Boolean data distributions. In this paper, we investigate the hardness of learning under the manifold hypothesis. We ask which minimal assumptions on the curvature and regularity of the manifold, if any, render the learning problem efficiently learnable. We prove that learning is hard under input manifolds of bounded curvature by extending proofs of hardness in the SQ and cryptographic settings for Boolean data inputs to the geometric setting. On the other hand, we show that additional assumptions on the volume of the data manifold alleviate these fundamental limitations and guarantee learnability via a simple interpolation argument. Notable instances of this regime are manifolds which can be reliably reconstructed via manifold learning. Looking forward, we comment on and empirically explore intermediate regimes of manifolds, which have heterogeneous features commonly found in real world data.
Pandora's White-Box: Increased Training Data Leakage in Open LLMs
Feb 26, 2024In this paper we undertake a systematic study of privacy attacks against open source Large Language Models (LLMs), where an adversary has access to either the model weights, gradients, or losses, and tries to exploit them to learn something about the underlying training data. Our headline results are the first membership inference attacks (MIAs) against pre-trained LLMs that are able to simultaneously achieve high TPRs and low FPRs, and a pipeline showing that over $50\%$ (!) of the fine-tuning dataset can be extracted from a fine-tuned LLM in natural settings. We consider varying degrees of access to the underlying model, customization of the language model, and resources available to the attacker. In the pre-trained setting, we propose three new white-box MIAs: an attack based on the gradient norm, a supervised neural network classifier, and a single step loss ratio attack. All outperform existing black-box baselines, and our supervised attack closes the gap between MIA attack success against LLMs and other types of models. In fine-tuning, we find that given access to the loss of the fine-tuned and base models, a fine-tuned loss ratio attack FLoRA is able to achieve near perfect MIA peformance. We then leverage these MIAs to extract fine-tuning data from fine-tuned language models. We find that the pipeline of generating from fine-tuned models prompted with a small snippet of the prefix of each training example, followed by using FLoRa to select the most likely training sample, succeeds the majority of the fine-tuning dataset after only $3$ epochs of fine-tuning. Taken together, these findings show that highly effective MIAs are available in almost all LLM training settings, and highlight that great care must be taken before LLMs are fine-tuned on highly sensitive data and then deployed.
Closed Drafting as a Case Study for First-Principle Interpretability, Memory, and Generalizability in Deep Reinforcement Learning
Nov 17, 2023
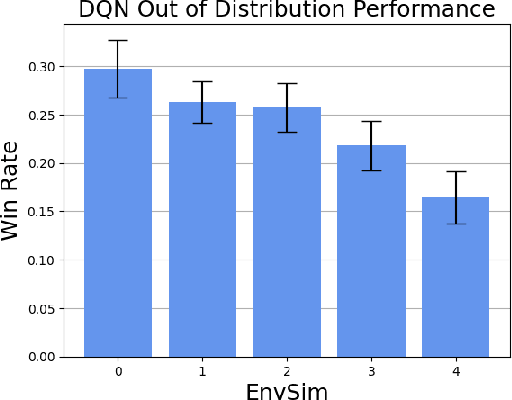
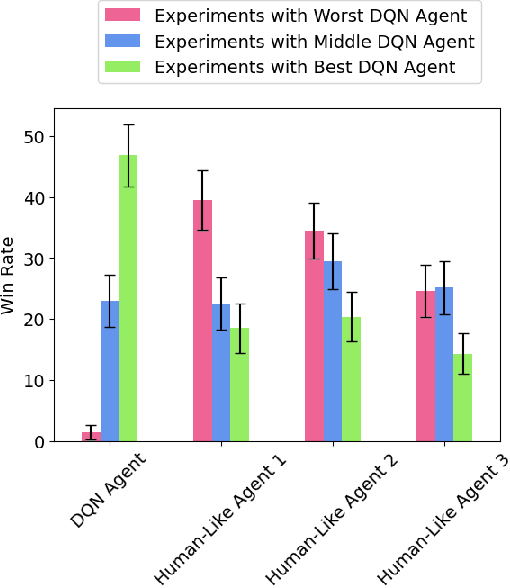
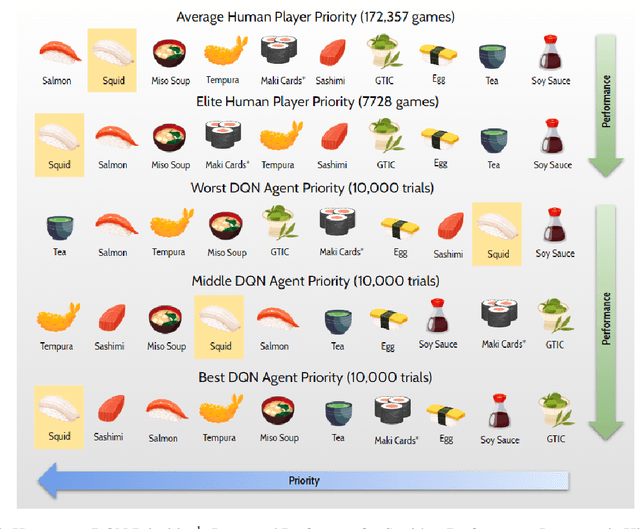
Closed drafting or "pick and pass" is a popular game mechanic where each round players select a card or other playable element from their hand and pass the rest to the next player. In this paper, we establish first-principle methods for studying the interpretability, generalizability, and memory of Deep Q-Network (DQN) models playing closed drafting games. In particular, we use a popular family of closed drafting games called "Sushi Go Party", in which we achieve state-of-the-art performance. We fit decision rules to interpret the decision-making strategy of trained DRL agents by comparing them to the ranking preferences of different types of human players. As Sushi Go Party can be expressed as a set of closely-related games based on the set of cards in play, we quantify the generalizability of DRL models trained on various sets of cards, establishing a method to benchmark agent performance as a function of environment unfamiliarity. Using the explicitly calculable memory of other player's hands in closed drafting games, we create measures of the ability of DRL models to learn memory.
MoPe: Model Perturbation-based Privacy Attacks on Language Models
Oct 22, 2023Recent work has shown that Large Language Models (LLMs) can unintentionally leak sensitive information present in their training data. In this paper, we present Model Perturbations (MoPe), a new method to identify with high confidence if a given text is in the training data of a pre-trained language model, given white-box access to the models parameters. MoPe adds noise to the model in parameter space and measures the drop in log-likelihood at a given point $x$, a statistic we show approximates the trace of the Hessian matrix with respect to model parameters. Across language models ranging from $70$M to $12$B parameters, we show that MoPe is more effective than existing loss-based attacks and recently proposed perturbation-based methods. We also examine the role of training point order and model size in attack success, and empirically demonstrate that MoPe accurately approximate the trace of the Hessian in practice. Our results show that the loss of a point alone is insufficient to determine extractability -- there are training points we can recover using our method that have average loss. This casts some doubt on prior works that use the loss of a point as evidence of memorization or unlearning.