 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Warmup-Stable-Decay Learning Rates: A River Valley Loss Landscape Perspective
Paper and Code
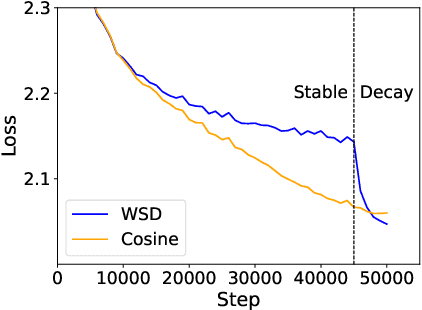

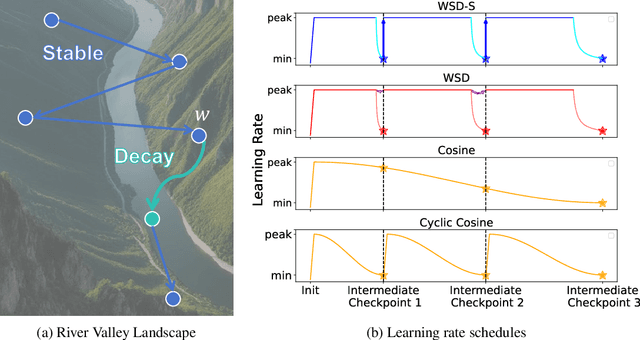
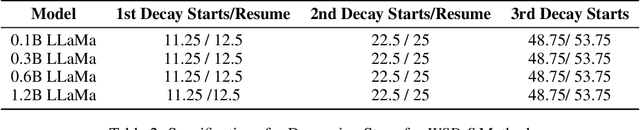
Training language models currently requires pre-determining a fixed compute budget because the typical cosine learning rate schedule depends on the total number of steps. In contrast, the Warmup-Stable-Decay (WSD) schedule uses a constant learning rate to produce a main branch of iterates that can in principle continue indefinitely without a pre-specified compute budget. Then, given any compute budget, one can branch out from the main branch at a proper at any time with a rapidly decaying learning rate to produce a strong model. Empirically, WSD generates a non-traditional loss curve: the loss remains elevated during the stable phase but sharply declines during the decay phase. Towards explaining this phenomenon, we conjecture that pretraining loss exhibits a river valley landscape, which resembles a deep valley with a river at its bottom. Under this assumption, we show that during the stable phase, the iterate undergoes large oscillations due to the high learning rate, yet it progresses swiftly along the river. During the decay phase, the rapidly dropping learning rate minimizes the iterate's oscillations, moving it closer to the river and revealing true optimization progress. Therefore, the sustained high learning rate phase and fast decaying phase are responsible for progress in the river and the mountain directions respectively, and are both critical. Our analysis predicts phenomenons consistent with empirical observations and shows that this landscape can emerge from pretraining on a simple bi-gram dataset. Inspired by the theory, we introduce WSD-S, a variant of WSD that reuses previous checkpoints' decay phases and keeps only one main branch, where we resume from a decayed checkpoint. WSD-S empirically outperforms WSD and Cyclic-Cosine in obtaining multiple language model checkpoints across various compute budgets in a single run for parameters scaling from 0.1B to 1.2B.