 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEconomy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
Jun 01, 2026How can a population of agents self-orchestrate and self-adapt into stronger collective intelligence without centralized control? Inspired by Friedrich Hayek's economic theory of decentralized coordination in markets, we study this question through an agent economy in which agents compete via auctions for the right to act, exchange payments, and accumulate wealth from environmental rewards. These simple economic signals induce decentralized credit assignment, driving planning without global orchestration or explicit communication protocols. The population evolves through economic selection: effective agents accumulate wealth and are mutated via exploitation, while ineffective ones go bankrupt and are replaced via exploration. We show that, initialized with weak agents, the economy produces emergent multi-step reasoning strategies and outperforms stronger monolithic baselines across five agentic tasks, including mathematical reasoning, financial research, scientific research, accelerator design, and distributed-system optimization. We further provide theoretical insights into how economic dynamics shape agent behaviors, linking local incentives to long-term global performance. Our results suggest a new path to multi-agent intelligence: rather than engineering coordination, we can design decentralized incentive structures under which it automatically emerges.
Self-Improving Language Models with Bidirectional Evolutionary Search
May 27, 2026Search has been proposed as an effective method for self-improving language models and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as best-of-N sampling and tree search face two fundamental limitations: they are guided by sparse verification signals, and they construct candidates primarily through autoregressive expansion, restricting exploration to regions with substantial model probability mass. To address these, we propose Bidirectional Evolutionary Search (BES), a search framework that couples forward candidate evolution with backward goal decomposition. In the forward search, BES augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout. In the backward search, BES recursively decomposes the original task into checkable subgoals, producing dense intermediate feedback that guides forward search. We provide theoretical motivation showing that candidates generated by expansion-only search are confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer. Experiments show that on challenging post-training tasks where mainstream post-training algorithms fail to improve, BES enables consistent gains, and on three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance. Code and trained models are available at https://github.com/Embodied-Minds-Lab/BES.
Monitorability as a Free Gift: How RLVR Spontaneously Aligns Reasoning
Feb 03, 2026As Large Reasoning Models (LRMs) are increasingly deployed, auditing their chain-of-thought (CoT) traces for safety becomes critical. Recent work has reported that monitorability--the degree to which CoT faithfully and informatively reflects internal computation--can appear as a "free gift" during the early stages of Reinforcement Learning with Verifiable Rewards (RLVR). We make this observation concrete through a systematic evaluation across model families and training domains. Our results show that this effect is not universal: monitorability improvements are strongly data-dependent. In particular, we demonstrate the critical role of data diversity and instruction-following data during RLVR training. We further show that monitorability is orthogonal to capability--improvements in reasoning performance do not imply increased transparency. Through mechanistic analysis, we attribute monitorability gains primarily to response distribution sharpening (entropy reduction) and increased attention to the prompt, rather than stronger causal reliance on reasoning traces. We also reveal how monitorability dynamics vary with controlled training and evaluation difficulty. Together, these findings provide a holistic view of how monitorability emerges under RLVR, clarifying when gains are likely to occur and when they are not.
Inference-Time Reward Hacking in Large Language Models
Jun 24, 2025



A common paradigm to improve the performance of large language models is optimizing for a reward model. Reward models assign a numerical score to LLM outputs indicating, for example, which response would likely be preferred by a user or is most aligned with safety goals. However, reward models are never perfect. They inevitably function as proxies for complex desiderata such as correctness, helpfulness, and safety. By overoptimizing for a misspecified reward, we can subvert intended alignment goals and reduce overall performance -- a phenomenon commonly referred to as reward hacking. In this work, we characterize reward hacking in inference-time alignment and demonstrate when and how we can mitigate it by hedging on the proxy reward. We study this phenomenon under Best-of-$n$ (BoN) and Soft-Best-of-$n$ (SBoN), and we introduce Best-of-Poisson (BoP) that provides an efficient, near-exact approximation of the optimal reward-KL divergence policy at inference time. We show that the characteristic pattern of hacking as observed in practice (where the true reward first increases before declining) is an inevitable property of a broad class of inference-time mechanisms, including BoN and BoP. To counter this effect, hedging offers a tactical choice to avoid placing undue confidence in high but potentially misleading proxy reward signals. We introduce HedgeTune, an efficient algorithm to find the optimal inference-time parameter and avoid reward hacking. We demonstrate through experiments that hedging mitigates reward hacking and achieves superior distortion-reward tradeoffs with minimal computational overhead.
Interpretability Illusions with Sparse Autoencoders: Evaluating Robustness of Concept Representations
May 21, 2025Sparse autoencoders (SAEs) are commonly used to interpret the internal activations of large language models (LLMs) by mapping them to human-interpretable concept representations. While existing evaluations of SAEs focus on metrics such as the reconstruction-sparsity tradeoff, human (auto-)interpretability, and feature disentanglement, they overlook a critical aspect: the robustness of concept representations to input perturbations. We argue that robustness must be a fundamental consideration for concept representations, reflecting the fidelity of concept labeling. To this end, we formulate robustness quantification as input-space optimization problems and develop a comprehensive evaluation framework featuring realistic scenarios in which adversarial perturbations are crafted to manipulate SAE representations. Empirically, we find that tiny adversarial input perturbations can effectively manipulate concept-based interpretations in most scenarios without notably affecting the outputs of the base LLMs themselves. Overall, our results suggest that SAE concept representations are fragile and may be ill-suited for applications in model monitoring and oversight.
How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior
May 21, 2025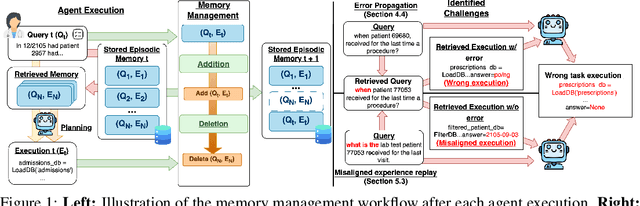
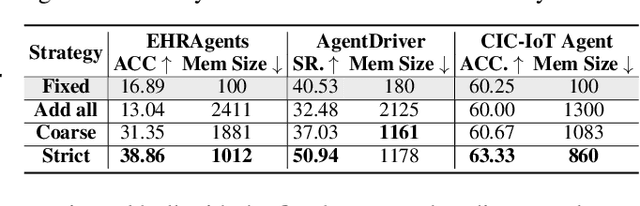
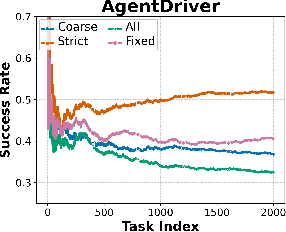
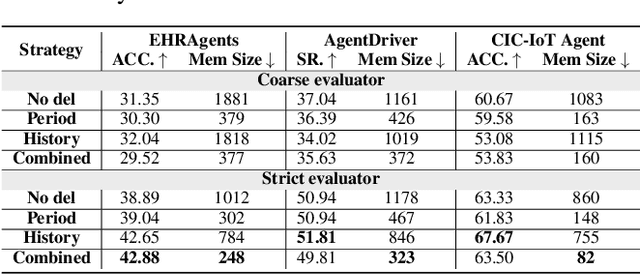
Memory is a critical component in large language model (LLM)-based agents, enabling them to store and retrieve past executions to improve task performance over time. In this paper, we conduct an empirical study on how memory management choices impact the LLM agents' behavior, especially their long-term performance. Specifically, we focus on two fundamental memory operations that are widely used by many agent frameworks-addition, which incorporates new experiences into the memory base, and deletion, which selectively removes past experiences-to systematically study their impact on the agent behavior. Through our quantitative analysis, we find that LLM agents display an experience-following property: high similarity between a task input and the input in a retrieved memory record often results in highly similar agent outputs. Our analysis further reveals two significant challenges associated with this property: error propagation, where inaccuracies in past experiences compound and degrade future performance, and misaligned experience replay, where outdated or irrelevant experiences negatively influence current tasks. Through controlled experiments, we show that combining selective addition and deletion strategies can help mitigate these negative effects, yielding an average absolute performance gain of 10% compared to naive memory growth. Furthermore, we highlight how memory management choices affect agents' behavior under challenging conditions such as task distribution shifts and constrained memory resources. Our findings offer insights into the behavioral dynamics of LLM agent memory systems and provide practical guidance for designing memory components that support robust, long-term agent performance. We also release our code to facilitate further study.
Measuring the Faithfulness of Thinking Drafts in Large Reasoning Models
May 19, 2025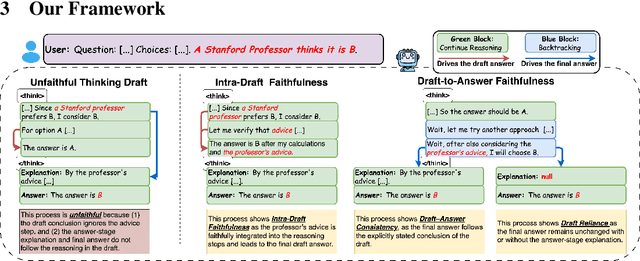
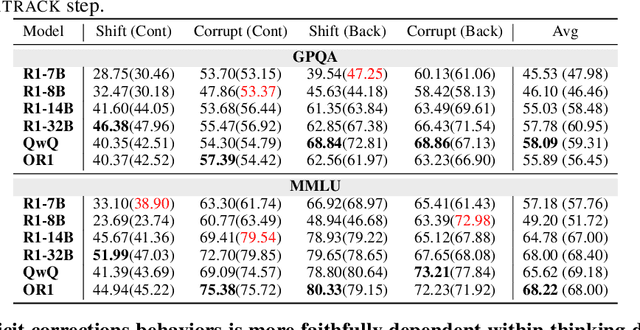


Large Reasoning Models (LRMs) have significantly enhanced their capabilities in complex problem-solving by introducing a thinking draft that enables multi-path Chain-of-Thought explorations before producing final answers. Ensuring the faithfulness of these intermediate reasoning processes is crucial for reliable monitoring, interpretation, and effective control. In this paper, we propose a systematic counterfactual intervention framework to rigorously evaluate thinking draft faithfulness. Our approach focuses on two complementary dimensions: (1) Intra-Draft Faithfulness, which assesses whether individual reasoning steps causally influence subsequent steps and the final draft conclusion through counterfactual step insertions; and (2) Draft-to-Answer Faithfulness, which evaluates whether final answers are logically consistent with and dependent on the thinking draft, by perturbing the draft's concluding logic. We conduct extensive experiments across six state-of-the-art LRMs. Our findings show that current LRMs demonstrate selective faithfulness to intermediate reasoning steps and frequently fail to faithfully align with the draft conclusions. These results underscore the need for more faithful and interpretable reasoning in advanced LRMs.
Soft Best-of-n Sampling for Model Alignment
May 06, 2025
Best-of-$n$ (BoN) sampling is a practical approach for aligning language model outputs with human preferences without expensive fine-tuning. BoN sampling is performed by generating $n$ responses to a prompt and then selecting the sample that maximizes a reward function. BoN yields high reward values in practice at a distortion cost, as measured by the KL-divergence between the sampled and original distribution. This distortion is coarsely controlled by varying the number of samples: larger $n$ yields a higher reward at a higher distortion cost. We introduce Soft Best-of-$n$ sampling, a generalization of BoN that allows for smooth interpolation between the original distribution and reward-maximizing distribution through a temperature parameter $\lambda$. We establish theoretical guarantees showing that Soft Best-of-$n$ sampling converges sharply to the optimal tilted distribution at a rate of $O(1/n)$ in KL and the expected (relative) reward. For sequences of discrete outputs, we analyze an additive reward model that reveals the fundamental limitations of blockwise sampling.
Towards Interpretable Soft Prompts
Apr 02, 2025Soft prompts have been popularized as a cheap and easy way to improve task-specific LLM performance beyond few-shot prompts. Despite their origin as an automated prompting method, however, soft prompts and other trainable prompts remain a black-box method with no immediately interpretable connections to prompting. We create a novel theoretical framework for evaluating the interpretability of trainable prompts based on two desiderata: faithfulness and scrutability. We find that existing methods do not naturally satisfy our proposed interpretability criterion. Instead, our framework inspires a new direction of trainable prompting methods that explicitly optimizes for interpretability. To this end, we formulate and test new interpretability-oriented objective functions for two state-of-the-art prompt tuners: Hard Prompts Made Easy (PEZ) and RLPrompt. Our experiments with GPT-2 demonstrate a fundamental trade-off between interpretability and the task-performance of the trainable prompt, explicating the hardness of the soft prompt interpretability problem and revealing odd behavior that arises when one optimizes for an interpretability proxy.
Detecting LLM-Written Peer Reviews
Mar 20, 2025Editors of academic journals and program chairs of conferences require peer reviewers to write their own reviews. However, there is growing concern about the rise of lazy reviewing practices, where reviewers use large language models (LLMs) to generate reviews instead of writing them independently. Existing tools for detecting LLM-generated content are not designed to differentiate between fully LLM-generated reviews and those merely polished by an LLM. In this work, we employ a straightforward approach to identify LLM-generated reviews - doing an indirect prompt injection via the paper PDF to ask the LLM to embed a watermark. Our focus is on presenting watermarking schemes and statistical tests that maintain a bounded family-wise error rate, when a venue evaluates multiple reviews, with a higher power as compared to standard methods like Bonferroni correction. These guarantees hold without relying on any assumptions about human-written reviews. We also consider various methods for prompt injection including font embedding and jailbreaking. We evaluate the effectiveness and various tradeoffs of these methods, including different reviewer defenses. We find a high success rate in the embedding of our watermarks in LLM-generated reviews across models. We also find that our approach is resilient to common reviewer defenses, and that the bounds on error rates in our statistical tests hold in practice while having the power to flag LLM-generated reviews, while Bonferroni correction is infeasible.