 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Fine-Tuning on Chain-of-Thought Reasoning
Nov 22, 2024



Large language models have emerged as powerful tools for general intelligence, showcasing advanced natural language processing capabilities that find applications across diverse domains. Despite their impressive performance, recent studies have highlighted the potential for significant enhancements in LLMs' task-specific performance through fine-tuning strategies like Reinforcement Learning with Human Feedback (RLHF), supervised fine-tuning (SFT), and Quantized Low-Rank Adapters (Q-LoRA) method. However, previous works have shown that while fine-tuning offers significant performance gains, it also leads to challenges such as catastrophic forgetting and privacy and safety risks. To this end, there has been little to no work in \textit{understanding the impact of fine-tuning on the reasoning capabilities of LLMs}. Our research investigates the effect of fine-tuning on the reasoning abilities of LLMs, addressing critical questions regarding the impact of task-specific fine-tuning on overall reasoning capabilities, the influence of fine-tuning on Chain-of-Thought (CoT) reasoning performance, and the implications for the faithfulness of CoT reasonings. By exploring these dimensions, our study shows the impact of fine-tuning on LLM reasoning capabilities, where the faithfulness of CoT reasoning, on average across four datasets, decreases, highlighting potential shifts in internal mechanisms of the LLMs resulting from fine-tuning processes.
Fair and Welfare-Efficient Constrained Multi-matchings under Uncertainty
Nov 04, 2024



We study fair allocation of constrained resources, where a market designer optimizes overall welfare while maintaining group fairness. In many large-scale settings, utilities are not known in advance, but are instead observed after realizing the allocation. We therefore estimate agent utilities using machine learning. Optimizing over estimates requires trading-off between mean utilities and their predictive variances. We discuss these trade-offs under two paradigms for preference modeling -- in the stochastic optimization regime, the market designer has access to a probability distribution over utilities, and in the robust optimization regime they have access to an uncertainty set containing the true utilities with high probability. We discuss utilitarian and egalitarian welfare objectives, and we explore how to optimize for them under stochastic and robust paradigms. We demonstrate the efficacy of our approaches on three publicly available conference reviewer assignment datasets. The approaches presented enable scalable constrained resource allocation under uncertainty for many combinations of objectives and preference models.
Data Poisoning Attacks on Off-Policy Policy Evaluation Methods
Apr 06, 2024Off-policy Evaluation (OPE) methods are a crucial tool for evaluating policies in high-stakes domains such as healthcare, where exploration is often infeasible, unethical, or expensive. However, the extent to which such methods can be trusted under adversarial threats to data quality is largely unexplored. In this work, we make the first attempt at investigating the sensitivity of OPE methods to marginal adversarial perturbations to the data. We design a generic data poisoning attack framework leveraging influence functions from robust statistics to carefully construct perturbations that maximize error in the policy value estimates. We carry out extensive experimentation with multiple healthcare and control datasets. Our results demonstrate that many existing OPE methods are highly prone to generating value estimates with large errors when subject to data poisoning attacks, even for small adversarial perturbations. These findings question the reliability of policy values derived using OPE methods and motivate the need for developing OPE methods that are statistically robust to train-time data poisoning attacks.
Axiomatic Aggregations of Abductive Explanations
Oct 12, 2023
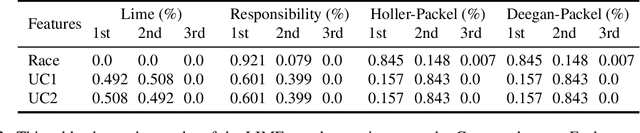

The recent criticisms of the robustness of post hoc model approximation explanation methods (like LIME and SHAP) have led to the rise of model-precise abductive explanations. For each data point, abductive explanations provide a minimal subset of features that are sufficient to generate the outcome. While theoretically sound and rigorous, abductive explanations suffer from a major issue -- there can be several valid abductive explanations for the same data point. In such cases, providing a single abductive explanation can be insufficient; on the other hand, providing all valid abductive explanations can be incomprehensible due to their size. In this work, we solve this issue by aggregating the many possible abductive explanations into feature importance scores. We propose three aggregation methods: two based on power indices from cooperative game theory and a third based on a well-known measure of causal strength. We characterize these three methods axiomatically, showing that each of them uniquely satisfies a set of desirable properties. We also evaluate them on multiple datasets and show that these explanations are robust to the attacks that fool SHAP and LIME.
Matching Table Metadata with Business Glossaries Using Large Language Models
Sep 08, 2023



Enterprises often own large collections of structured data in the form of large databases or an enterprise data lake. Such data collections come with limited metadata and strict access policies that could limit access to the data contents and, therefore, limit the application of classic retrieval and analysis solutions. As a result, there is a need for solutions that can effectively utilize the available metadata. In this paper, we study the problem of matching table metadata to a business glossary containing data labels and descriptions. The resulting matching enables the use of an available or curated business glossary for retrieval and analysis without or before requesting access to the data contents. One solution to this problem is to use manually-defined rules or similarity measures on column names and glossary descriptions (or their vector embeddings) to find the closest match. However, such approaches need to be tuned through manual labeling and cannot handle many business glossaries that contain a combination of simple as well as complex and long descriptions. In this work, we leverage the power of large language models (LLMs) to design generic matching methods that do not require manual tuning and can identify complex relations between column names and glossaries. We propose methods that utilize LLMs in two ways: a) by generating additional context for column names that can aid with matching b) by using LLMs to directly infer if there is a relation between column names and glossary descriptions. Our preliminary experimental results show the effectiveness of our proposed methods.
Soft Options Critic
Jun 11, 2019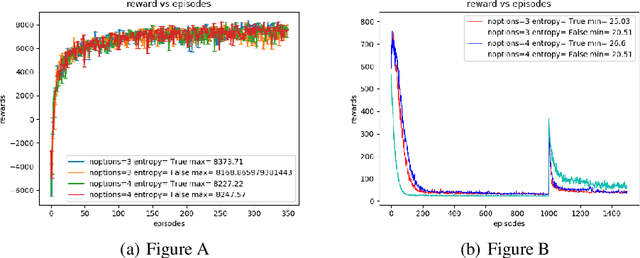
The option-critic architecture (Bacon, Harb, and Precup 2017) and several variants have successfully demonstrated the use of the options framework proposed by Sutton et al (Sutton, Precup, and Singh1999) to scale learning and planning in hierarchical tasks. Although most of these frameworks use entropy as a regularizer to improve exploration, they do not maximize entropy along with returns at every time step. (Haarnoja et al., 2018d) recently introduced an off-policy actor critic algorithm in theSoft Actor Critic paper that maximize returns while maximizing entropy in a constrained manner thus enabling learning of robust options in continuous and discrete action spaces In this paper we adopt the architecture of soft-actor critic to investigate the effect of maximizing entropy of each options and inter-option policy in options framework. We derive the soft options improvement theorem and propose a novel soft-options framework to incorporate maximization of entropy of actions and options in a constrained manner. Our experiments show that the modified options-critic framework generates robust policies which allows fast recovery when environment is subjected to perturbations and outperforms vanilla options-critic framework in most hierarchical tasks