 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery Agents for Real-Time Analytics: Toward Proactive Insight Systems
May 26, 2026Modern analytics systems are fundamentally reactive, requiring users to define queries over increasingly complex and continuously evolving data. In real-time streaming environments, this paradigm breaks down, as the space of potential insights becomes too large to enumerate manually. We present a multi-agent architecture for autonomous insight discovery over real-time data streams. The system implements a continuous discovery loop in which agents generate hypotheses, compile them into executable analytics, validate generated artifacts, and produce visualizations and deployable applications. The architecture leverages Apache Kafka for event-driven coordination, Apache Flink for stream processing, and large language models to implement specialized agents. A key contribution is a contract-driven design based on typed intermediate artifacts, enabling modularity, observability, lineage, and safer execution of dynamically generated analytics. Through use cases in retail, finance, and public data, we show how this architecture supports a shift from query-driven analytics to proactive, discovery-driven systems.
ConstrainedSQL: Training LLMs for Text2SQL via Constrained Reinforcement Learning
Nov 12, 2025Reinforcement learning (RL) has demonstrated significant promise in enhancing the reasoning capabilities of Text2SQL LLMs, especially with advanced algorithms such as GRPO and DAPO. However, the performance of these methods is highly sensitive to the design of reward functions. Inappropriate rewards can lead to reward hacking, where models exploit loopholes in the reward structure to achieve high scores without genuinely solving the task. This work considers a constrained RL framework for Text2SQL that incorporates natural and interpretable reward and constraint signals, while dynamically balancing trade-offs among them during the training. We establish the theoretical guarantees of our constrained RL framework and our numerical experiments on the well-known Text2SQL datasets substantiate the improvement of our approach over the state-of-the-art RL-trained LLMs.
Knowledge Base Construction for Knowledge-Augmented Text-to-SQL
May 28, 2025Text-to-SQL aims to translate natural language queries into SQL statements, which is practical as it enables anyone to easily retrieve the desired information from databases. Recently, many existing approaches tackle this problem with Large Language Models (LLMs), leveraging their strong capability in understanding user queries and generating corresponding SQL code. Yet, the parametric knowledge in LLMs might be limited to covering all the diverse and domain-specific queries that require grounding in various database schemas, which makes generated SQLs less accurate oftentimes. To tackle this, we propose constructing the knowledge base for text-to-SQL, a foundational source of knowledge, from which we retrieve and generate the necessary knowledge for given queries. In particular, unlike existing approaches that either manually annotate knowledge or generate only a few pieces of knowledge for each query, our knowledge base is comprehensive, which is constructed based on a combination of all the available questions and their associated database schemas along with their relevant knowledge, and can be reused for unseen databases from different datasets and domains. We validate our approach on multiple text-to-SQL datasets, considering both the overlapping and non-overlapping database scenarios, where it outperforms relevant baselines substantially.
Filtering Learning Histories Enhances In-Context Reinforcement Learning
May 21, 2025Transformer models (TMs) have exhibited remarkable in-context reinforcement learning (ICRL) capabilities, allowing them to generalize to and improve in previously unseen environments without re-training or fine-tuning. This is typically accomplished by imitating the complete learning histories of a source RL algorithm over a substantial amount of pretraining environments, which, however, may transfer suboptimal behaviors inherited from the source algorithm/dataset. Therefore, in this work, we address the issue of inheriting suboptimality from the perspective of dataset preprocessing. Motivated by the success of the weighted empirical risk minimization, we propose a simple yet effective approach, learning history filtering (LHF), to enhance ICRL by reweighting and filtering the learning histories based on their improvement and stability characteristics. To the best of our knowledge, LHF is the first approach to avoid source suboptimality by dataset preprocessing, and can be combined with the current state-of-the-art (SOTA) ICRL algorithms. We substantiate the effectiveness of LHF through a series of experiments conducted on the well-known ICRL benchmarks, encompassing both discrete environments and continuous robotic manipulation tasks, with three SOTA ICRL algorithms (AD, DPT, DICP) as the backbones. LHF exhibits robust performance across a variety of suboptimal scenarios, as well as under varying hyperparameters and sampling strategies. Notably, the superior performance of LHF becomes more pronounced in the presence of noisy data, indicating the significance of filtering learning histories.
Triplet Interaction Improves Graph Transformers: Accurate Molecular Graph Learning with Triplet Graph Transformers
Feb 07, 2024



Graph transformers typically lack direct pair-to-pair communication, instead forcing neighboring pairs to exchange information via a common node. We propose the Triplet Graph Transformer (TGT) that enables direct communication between two neighboring pairs in a graph via novel triplet attention and aggregation mechanisms. TGT is applied to molecular property prediction by first predicting interatomic distances from 2D graphs and then using these distances for downstream tasks. A novel three-stage training procedure and stochastic inference further improve training efficiency and model performance. Our model achieves new state-of-the-art (SOTA) results on open challenge benchmarks PCQM4Mv2 and OC20 IS2RE. We also obtain SOTA results on QM9, MOLPCBA, and LIT-PCBA molecular property prediction benchmarks via transfer learning. We also demonstrate the generality of TGT with SOTA results on the traveling salesman problem (TSP).
Self-Supervised Contrastive Pre-Training for Multivariate Point Processes
Feb 01, 2024Self-supervision is one of the hallmarks of representation learning in the increasingly popular suite of foundation models including large language models such as BERT and GPT-3, but it has not been pursued in the context of multivariate event streams, to the best of our knowledge. We introduce a new paradigm for self-supervised learning for multivariate point processes using a transformer encoder. Specifically, we design a novel pre-training strategy for the encoder where we not only mask random event epochs but also insert randomly sampled "void" epochs where an event does not occur; this differs from the typical discrete-time pretext tasks such as word-masking in BERT but expands the effectiveness of masking to better capture continuous-time dynamics. To improve downstream tasks, we introduce a contrasting module that compares real events to simulated void instances. The pre-trained model can subsequently be fine-tuned on a potentially much smaller event dataset, similar conceptually to the typical transfer of popular pre-trained language models. We demonstrate the effectiveness of our proposed paradigm on the next-event prediction task using synthetic datasets and 3 real applications, observing a relative performance boost of as high as up to 20% compared to state-of-the-art models.
Adaptive Primal-Dual Method for Safe Reinforcement Learning
Feb 01, 2024

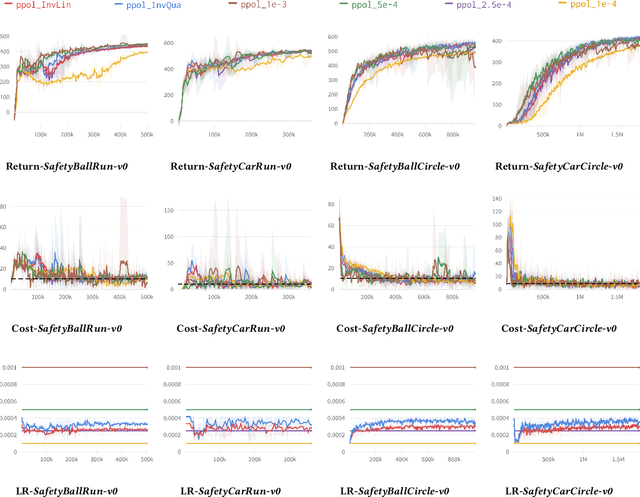

Primal-dual methods have a natural application in Safe Reinforcement Learning (SRL), posed as a constrained policy optimization problem. In practice however, applying primal-dual methods to SRL is challenging, due to the inter-dependency of the learning rate (LR) and Lagrangian multipliers (dual variables) each time an embedded unconstrained RL problem is solved. In this paper, we propose, analyze and evaluate adaptive primal-dual (APD) methods for SRL, where two adaptive LRs are adjusted to the Lagrangian multipliers so as to optimize the policy in each iteration. We theoretically establish the convergence, optimality and feasibility of the APD algorithm. Finally, we conduct numerical evaluation of the practical APD algorithm with four well-known environments in Bullet-Safey-Gym employing two state-of-the-art SRL algorithms: PPO-Lagrangian and DDPG-Lagrangian. All experiments show that the practical APD algorithm outperforms (or achieves comparable performance) and attains more stable training than the constant LR cases. Additionally, we substantiate the robustness of selecting the two adaptive LRs by empirical evidence.
Matching Table Metadata with Business Glossaries Using Large Language Models
Sep 08, 2023



Enterprises often own large collections of structured data in the form of large databases or an enterprise data lake. Such data collections come with limited metadata and strict access policies that could limit access to the data contents and, therefore, limit the application of classic retrieval and analysis solutions. As a result, there is a need for solutions that can effectively utilize the available metadata. In this paper, we study the problem of matching table metadata to a business glossary containing data labels and descriptions. The resulting matching enables the use of an available or curated business glossary for retrieval and analysis without or before requesting access to the data contents. One solution to this problem is to use manually-defined rules or similarity measures on column names and glossary descriptions (or their vector embeddings) to find the closest match. However, such approaches need to be tuned through manual labeling and cannot handle many business glossaries that contain a combination of simple as well as complex and long descriptions. In this work, we leverage the power of large language models (LLMs) to design generic matching methods that do not require manual tuning and can identify complex relations between column names and glossaries. We propose methods that utilize LLMs in two ways: a) by generating additional context for column names that can aid with matching b) by using LLMs to directly infer if there is a relation between column names and glossary descriptions. Our preliminary experimental results show the effectiveness of our proposed methods.
Probabilistic Constraint for Safety-Critical Reinforcement Learning
Jun 29, 2023



In this paper, we consider the problem of learning safe policies for probabilistic-constrained reinforcement learning (RL). Specifically, a safe policy or controller is one that, with high probability, maintains the trajectory of the agent in a given safe set. We establish a connection between this probabilistic-constrained setting and the cumulative-constrained formulation that is frequently explored in the existing literature. We provide theoretical bounds elucidating that the probabilistic-constrained setting offers a better trade-off in terms of optimality and safety (constraint satisfaction). The challenge encountered when dealing with the probabilistic constraints, as explored in this work, arises from the absence of explicit expressions for their gradients. Our prior work provides such an explicit gradient expression for probabilistic constraints which we term Safe Policy Gradient-REINFORCE (SPG-REINFORCE). In this work, we provide an improved gradient SPG-Actor-Critic that leads to a lower variance than SPG-REINFORCE, which is substantiated by our theoretical results. A noteworthy aspect of both SPGs is their inherent algorithm independence, rendering them versatile for application across a range of policy-based algorithms. Furthermore, we propose a Safe Primal-Dual algorithm that can leverage both SPGs to learn safe policies. It is subsequently followed by theoretical analyses that encompass the convergence of the algorithm, as well as the near-optimality and feasibility on average. In addition, we test the proposed approaches by a series of empirical experiments. These experiments aim to examine and analyze the inherent trade-offs between the optimality and safety, and serve to substantiate the efficacy of two SPGs, as well as our theoretical contributions.
The Information Pathways Hypothesis: Transformers are Dynamic Self-Ensembles
Jun 02, 2023



Transformers use the dense self-attention mechanism which gives a lot of flexibility for long-range connectivity. Over multiple layers of a deep transformer, the number of possible connectivity patterns increases exponentially. However, very few of these contribute to the performance of the network, and even fewer are essential. We hypothesize that there are sparsely connected sub-networks within a transformer, called information pathways which can be trained independently. However, the dynamic (i.e., input-dependent) nature of these pathways makes it difficult to prune dense self-attention during training. But the overall distribution of these pathways is often predictable. We take advantage of this fact to propose Stochastically Subsampled self-Attention (SSA) - a general-purpose training strategy for transformers that can reduce both the memory and computational cost of self-attention by 4 to 8 times during training while also serving as a regularization method - improving generalization over dense training. We show that an ensemble of sub-models can be formed from the subsampled pathways within a network, which can achieve better performance than its densely attended counterpart. We perform experiments on a variety of NLP, computer vision and graph learning tasks in both generative and discriminative settings to provide empirical evidence for our claims and show the effectiveness of the proposed method.