 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrainedSQL: Training LLMs for Text2SQL via Constrained Reinforcement Learning
Nov 12, 2025Reinforcement learning (RL) has demonstrated significant promise in enhancing the reasoning capabilities of Text2SQL LLMs, especially with advanced algorithms such as GRPO and DAPO. However, the performance of these methods is highly sensitive to the design of reward functions. Inappropriate rewards can lead to reward hacking, where models exploit loopholes in the reward structure to achieve high scores without genuinely solving the task. This work considers a constrained RL framework for Text2SQL that incorporates natural and interpretable reward and constraint signals, while dynamically balancing trade-offs among them during the training. We establish the theoretical guarantees of our constrained RL framework and our numerical experiments on the well-known Text2SQL datasets substantiate the improvement of our approach over the state-of-the-art RL-trained LLMs.
Filtering Learning Histories Enhances In-Context Reinforcement Learning
May 21, 2025Transformer models (TMs) have exhibited remarkable in-context reinforcement learning (ICRL) capabilities, allowing them to generalize to and improve in previously unseen environments without re-training or fine-tuning. This is typically accomplished by imitating the complete learning histories of a source RL algorithm over a substantial amount of pretraining environments, which, however, may transfer suboptimal behaviors inherited from the source algorithm/dataset. Therefore, in this work, we address the issue of inheriting suboptimality from the perspective of dataset preprocessing. Motivated by the success of the weighted empirical risk minimization, we propose a simple yet effective approach, learning history filtering (LHF), to enhance ICRL by reweighting and filtering the learning histories based on their improvement and stability characteristics. To the best of our knowledge, LHF is the first approach to avoid source suboptimality by dataset preprocessing, and can be combined with the current state-of-the-art (SOTA) ICRL algorithms. We substantiate the effectiveness of LHF through a series of experiments conducted on the well-known ICRL benchmarks, encompassing both discrete environments and continuous robotic manipulation tasks, with three SOTA ICRL algorithms (AD, DPT, DICP) as the backbones. LHF exhibits robust performance across a variety of suboptimal scenarios, as well as under varying hyperparameters and sampling strategies. Notably, the superior performance of LHF becomes more pronounced in the presence of noisy data, indicating the significance of filtering learning histories.
PIANIST: Learning Partially Observable World Models with LLMs for Multi-Agent Decision Making
Nov 24, 2024



Effective extraction of the world knowledge in LLMs for complex decision-making tasks remains a challenge. We propose a framework PIANIST for decomposing the world model into seven intuitive components conducive to zero-shot LLM generation. Given only the natural language description of the game and how input observations are formatted, our method can generate a working world model for fast and efficient MCTS simulation. We show that our method works well on two different games that challenge the planning and decision making skills of the agent for both language and non-language based action taking, without any training on domain-specific training data or explicitly defined world model.
SAD: State-Action Distillation for In-Context Reinforcement Learning under Random Policies
Oct 25, 2024



Pretrained foundation models have exhibited extraordinary in-context learning performance, allowing zero-shot generalization to new tasks not encountered during the pretraining. In the case of RL, in-context RL (ICRL) emerges when pretraining FMs on decision-making problems in an autoregressive-supervised manner. Nevertheless, current state-of-the-art ICRL algorithms, such as AD, DPT and DIT, impose stringent requirements on generating the pretraining dataset concerning the behavior (source) policies, context information, and action labels, etc. Notably, these algorithms either demand optimal policies or require varying degrees of well-trained behavior policies for all environments during the generation of the pretraining dataset. This significantly hinders the application of ICRL to real-world scenarios, where acquiring optimal or well-trained policies for a substantial volume of real-world training environments can be both prohibitively intractable and expensive. To overcome this challenge, we introduce a novel approach, termed State-Action Distillation (SAD), that allows to generate a remarkable pretraining dataset guided solely by random policies. In particular, SAD selects query states and corresponding action labels by distilling the outstanding state-action pairs from the entire state and action spaces by using random policies within a trust horizon, and then inherits the classical autoregressive-supervised mechanism during the pretraining. To the best of our knowledge, this is the first work that enables promising ICRL under (e.g., uniform) random policies and random contexts. We establish theoretical analyses regarding the performance guarantees of SAD. Moreover, our empirical results across multiple ICRL benchmark environments demonstrate that, on average, SAD outperforms the best baseline by 180.86% in the offline evaluation and by 172.8% in the online evaluation.
Domain Adaptation for Offline Reinforcement Learning with Limited Samples
Aug 22, 2024Offline reinforcement learning (RL) learns effective policies from a static target dataset. Despite state-of-the-art (SOTA) offline RL algorithms being promising, they highly rely on the quality of the target dataset. The performance of SOTA algorithms can degrade in scenarios with limited samples in the target dataset, which is often the case in real-world applications. To address this issue, domain adaptation that leverages auxiliary samples from related source datasets (such as simulators) can be beneficial. In this context, determining the optimal way to trade off the source and target datasets remains a critical challenge in offline RL. To the best of our knowledge, this paper proposes the first framework that theoretically and experimentally explores how the weight assigned to each dataset affects the performance of offline RL. We establish the performance bounds and convergence neighborhood of our framework, both of which depend on the selection of the weight. Furthermore, we identify the existence of an optimal weight for balancing the two datasets. All theoretical guarantees and optimal weight depend on the quality of the source dataset and the size of the target dataset. Our empirical results on the well-known Procgen Benchmark substantiate our theoretical contributions.
Strategist: Learning Strategic Skills by LLMs via Bi-Level Tree Search
Aug 20, 2024



In this paper, we propose a new method Strategist that utilizes LLMs to acquire new skills for playing multi-agent games through a self-improvement process. Our method gathers quality feedback through self-play simulations with Monte Carlo tree search and LLM-based reflection, which can then be used to learn high-level strategic skills such as how to evaluate states that guide the low-level execution.We showcase how our method can be used in both action planning and dialogue generation in the context of games, achieving good performance on both tasks. Specifically, we demonstrate that our method can help train agents with better performance than both traditional reinforcement learning-based approaches and other LLM-based skill learning approaches in games including the Game of Pure Strategy (GOPS) and The Resistance: Avalon.
A General Control-Theoretic Approach for Reinforcement Learning: Theory and Algorithms
Jun 20, 2024



We devise a control-theoretic reinforcement learning approach to support direct learning of the optimal policy. We establish theoretical properties of our approach and derive an algorithm based on a specific instance of this approach. Our empirical results demonstrate the significant benefits of our approach.
Adaptive Primal-Dual Method for Safe Reinforcement Learning
Feb 01, 2024

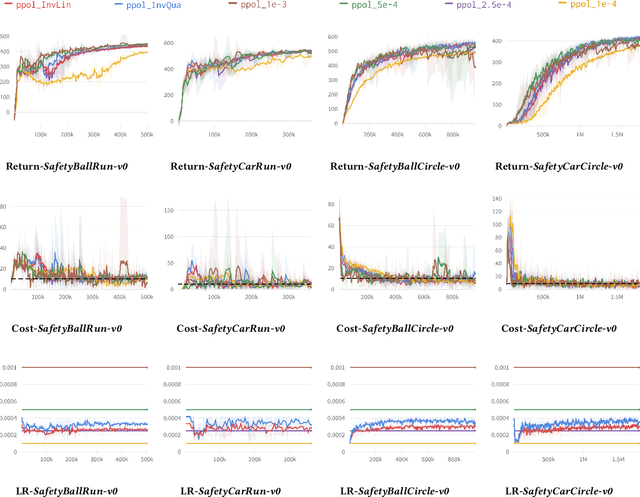

Primal-dual methods have a natural application in Safe Reinforcement Learning (SRL), posed as a constrained policy optimization problem. In practice however, applying primal-dual methods to SRL is challenging, due to the inter-dependency of the learning rate (LR) and Lagrangian multipliers (dual variables) each time an embedded unconstrained RL problem is solved. In this paper, we propose, analyze and evaluate adaptive primal-dual (APD) methods for SRL, where two adaptive LRs are adjusted to the Lagrangian multipliers so as to optimize the policy in each iteration. We theoretically establish the convergence, optimality and feasibility of the APD algorithm. Finally, we conduct numerical evaluation of the practical APD algorithm with four well-known environments in Bullet-Safey-Gym employing two state-of-the-art SRL algorithms: PPO-Lagrangian and DDPG-Lagrangian. All experiments show that the practical APD algorithm outperforms (or achieves comparable performance) and attains more stable training than the constant LR cases. Additionally, we substantiate the robustness of selecting the two adaptive LRs by empirical evidence.
Probabilistic Constraint for Safety-Critical Reinforcement Learning
Jun 29, 2023



In this paper, we consider the problem of learning safe policies for probabilistic-constrained reinforcement learning (RL). Specifically, a safe policy or controller is one that, with high probability, maintains the trajectory of the agent in a given safe set. We establish a connection between this probabilistic-constrained setting and the cumulative-constrained formulation that is frequently explored in the existing literature. We provide theoretical bounds elucidating that the probabilistic-constrained setting offers a better trade-off in terms of optimality and safety (constraint satisfaction). The challenge encountered when dealing with the probabilistic constraints, as explored in this work, arises from the absence of explicit expressions for their gradients. Our prior work provides such an explicit gradient expression for probabilistic constraints which we term Safe Policy Gradient-REINFORCE (SPG-REINFORCE). In this work, we provide an improved gradient SPG-Actor-Critic that leads to a lower variance than SPG-REINFORCE, which is substantiated by our theoretical results. A noteworthy aspect of both SPGs is their inherent algorithm independence, rendering them versatile for application across a range of policy-based algorithms. Furthermore, we propose a Safe Primal-Dual algorithm that can leverage both SPGs to learn safe policies. It is subsequently followed by theoretical analyses that encompass the convergence of the algorithm, as well as the near-optimality and feasibility on average. In addition, we test the proposed approaches by a series of empirical experiments. These experiments aim to examine and analyze the inherent trade-offs between the optimality and safety, and serve to substantiate the efficacy of two SPGs, as well as our theoretical contributions.
Open Problems and Modern Solutions for Deep Reinforcement Learning
Feb 05, 2023Deep Reinforcement Learning (DRL) has achieved great success in solving complicated decision-making problems. Despite the successes, DRL is frequently criticized for many reasons, e.g., data inefficient, inflexible and intractable reward design. In this paper, we review two publications that investigate the mentioned issues of DRL and propose effective solutions. One designs the reward for human-robot collaboration by combining the manually designed extrinsic reward with a parameterized intrinsic reward function via the deterministic policy gradient, which improves the task performance and guarantees a stronger obstacle avoidance. The other one applies selective attention and particle filters to rapidly and flexibly attend to and select crucial pre-learned features for DRL using approximate inference instead of backpropagation, thereby improving the efficiency and flexibility of DRL. Potential avenues for future work in both domains are discussed in this paper.