 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoForge: Goal-Directed Egocentric World Simulator
Mar 20, 2026Generative world models have shown promise for simulating dynamic environments, yet egocentric video remains challenging due to rapid viewpoint changes, frequent hand-object interactions, and goal-directed procedures whose evolution depends on latent human intent. Existing approaches either focus on hand-centric instructional synthesis with limited scene evolution, perform static view translation without modeling action dynamics, or rely on dense supervision, such as camera trajectories, long video prefixes, synchronized multicamera capture, etc. In this work, we introduce EgoForge, an egocentric goal-directed world simulator that generates coherent, first-person video rollouts from minimal static inputs: a single egocentric image, a high-level instruction, and an optional auxiliary exocentric view. To improve intent alignment and temporal consistency, we propose VideoDiffusionNFT, a trajectory-level reward-guided refinement that optimizes goal completion, temporal causality, scene consistency, and perceptual fidelity during diffusion sampling. Extensive experiments show EgoForge achieves consistent gains in semantic alignment, geometric stability, and motion fidelity over strong baselines, and robust performance in real-world smart-glasses experiments.
Toward Cognitive Supersensing in Multimodal Large Language Model
Feb 02, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
CoRe3D: Collaborative Reasoning as a Foundation for 3D Intelligence
Dec 14, 2025Recent advances in large multimodal models suggest that explicit reasoning mechanisms play a critical role in improving model reliability, interpretability, and cross-modal alignment. While such reasoning-centric approaches have been proven effective in language and vision tasks, their extension to 3D remains underdeveloped. CoRe3D introduces a unified 3D understanding and generation reasoning framework that jointly operates over semantic and spatial abstractions, enabling high-level intent inferred from language to directly guide low-level 3D content formation. Central to this design is a spatially grounded reasoning representation that decomposes 3D latent space into localized regions, allowing the model to reason over geometry in a compositional and procedural manner. By tightly coupling semantic chain-of-thought inference with structured spatial reasoning, CoRe3D produces 3D outputs that exhibit strong local consistency and faithful alignment with linguistic descriptions.
Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs
Sep 26, 2025Can humans identify AI-generated (fake) videos and provide grounded reasons? While video generation models have advanced rapidly, a critical dimension -- whether humans can detect deepfake traces within a generated video, i.e., spatiotemporal grounded visual artifacts that reveal a video as machine generated -- has been largely overlooked. We introduce DeeptraceReward, the first fine-grained, spatially- and temporally- aware benchmark that annotates human-perceived fake traces for video generation reward. The dataset comprises 4.3K detailed annotations across 3.3K high-quality generated videos. Each annotation provides a natural-language explanation, pinpoints a bounding-box region containing the perceived trace, and marks precise onset and offset timestamps. We consolidate these annotations into 9 major categories of deepfake traces that lead humans to identify a video as AI-generated, and train multimodal language models (LMs) as reward models to mimic human judgments and localizations. On DeeptraceReward, our 7B reward model outperforms GPT-5 by 34.7% on average across fake clue identification, grounding, and explanation. Interestingly, we observe a consistent difficulty gradient: binary fake v.s. real classification is substantially easier than fine-grained deepfake trace detection; within the latter, performance degrades from natural language explanations (easiest), to spatial grounding, to temporal labeling (hardest). By foregrounding human-perceived deepfake traces, DeeptraceReward provides a rigorous testbed and training signal for socially aware and trustworthy video generation.
Lessons Learned: A Multi-Agent Framework for Code LLMs to Learn and Improve
May 29, 2025Recent studies show that LLMs possess different skills and specialize in different tasks. In fact, we observe that their varied performance occur in several levels of granularity. For example, in the code optimization task, code LLMs excel at different optimization categories and no one dominates others. This observation prompts the question of how one leverages multiple LLM agents to solve a coding problem without knowing their complementary strengths a priori. We argue that a team of agents can learn from each other's successes and failures so as to improve their own performance. Thus, a lesson is the knowledge produced by an agent and passed on to other agents in the collective solution process. We propose a lesson-based collaboration framework, design the lesson solicitation--banking--selection mechanism, and demonstrate that a team of small LLMs with lessons learned can outperform a much larger LLM and other multi-LLM collaboration methods.
PIANIST: Learning Partially Observable World Models with LLMs for Multi-Agent Decision Making
Nov 24, 2024



Effective extraction of the world knowledge in LLMs for complex decision-making tasks remains a challenge. We propose a framework PIANIST for decomposing the world model into seven intuitive components conducive to zero-shot LLM generation. Given only the natural language description of the game and how input observations are formatted, our method can generate a working world model for fast and efficient MCTS simulation. We show that our method works well on two different games that challenge the planning and decision making skills of the agent for both language and non-language based action taking, without any training on domain-specific training data or explicitly defined world model.
Dataset Distillation for Offline Reinforcement Learning
Aug 01, 2024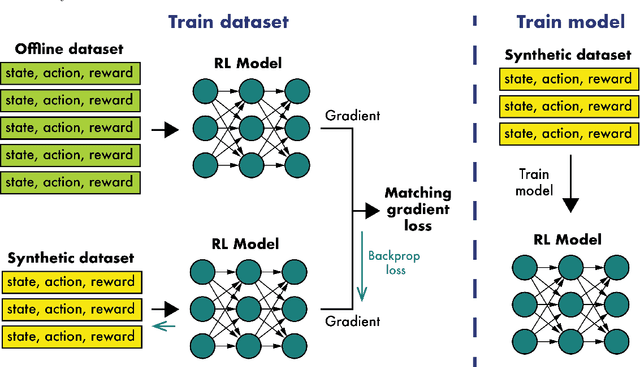
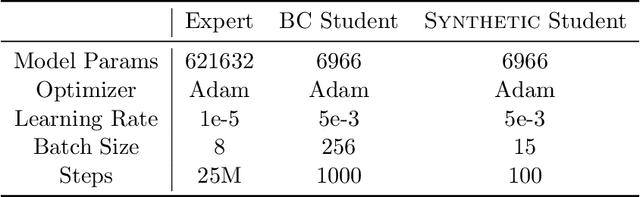

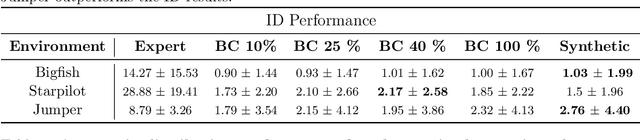
Offline reinforcement learning often requires a quality dataset that we can train a policy on. However, in many situations, it is not possible to get such a dataset, nor is it easy to train a policy to perform well in the actual environment given the offline data. We propose using data distillation to train and distill a better dataset which can then be used for training a better policy model. We show that our method is able to synthesize a dataset where a model trained on it achieves similar performance to a model trained on the full dataset or a model trained using percentile behavioral cloning. Our project site is available at $\href{https://datasetdistillation4rl.github.io}{\text{here}}$. We also provide our implementation at $\href{https://github.com/ggflow123/DDRL}{\text{this GitHub repository}}$.
PlantTracing: Tracing Arabidopsis Thaliana Apex with CenterTrack
May 18, 2024This work applies an encoder-decoder-based machine learning network to detect and track the motion and growth of the flowering stem apex of Arabidopsis Thaliana. Based on the CenterTrack, a machine learning back-end network, we trained a model based on ten time-lapsed labeled videos and tested against three videos.
Symbolic Music Generation with Non-Differentiable Rule Guided Diffusion
Feb 23, 2024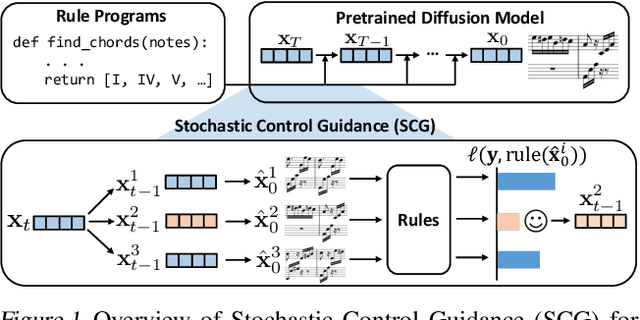



We study the problem of symbolic music generation (e.g., generating piano rolls), with a technical focus on non-differentiable rule guidance. Musical rules are often expressed in symbolic form on note characteristics, such as note density or chord progression, many of which are non-differentiable which pose a challenge when using them for guided diffusion. We propose Stochastic Control Guidance (SCG), a novel guidance method that only requires forward evaluation of rule functions that can work with pre-trained diffusion models in a plug-and-play way, thus achieving training-free guidance for non-differentiable rules for the first time. Additionally, we introduce a latent diffusion architecture for symbolic music generation with high time resolution, which can be composed with SCG in a plug-and-play fashion. Compared to standard strong baselines in symbolic music generation, this framework demonstrates marked advancements in music quality and rule-based controllability, outperforming current state-of-the-art generators in a variety of settings. For detailed demonstrations, code and model checkpoints, please visit our project website: https://scg-rule-guided-music.github.io/.