 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Structured Financial Data with LLMs: A Case Study on Fraud Detection
Dec 15, 2025Detecting fraud in financial transactions typically relies on tabular models that demand heavy feature engineering to handle high-dimensional data and offer limited interpretability, making it difficult for humans to understand predictions. Large Language Models (LLMs), in contrast, can produce human-readable explanations and facilitate feature analysis, potentially reducing the manual workload of fraud analysts and informing system refinements. However, they perform poorly when applied directly to tabular fraud detection due to the difficulty of reasoning over many features, the extreme class imbalance, and the absence of contextual information. To bridge this gap, we introduce FinFRE-RAG, a two-stage approach that applies importance-guided feature reduction to serialize a compact subset of numeric/categorical attributes into natural language and performs retrieval-augmented in-context learning over label-aware, instance-level exemplars. Across four public fraud datasets and three families of open-weight LLMs, FinFRE-RAG substantially improves F1/MCC over direct prompting and is competitive with strong tabular baselines in several settings. Although these LLMs still lag behind specialized classifiers, they narrow the performance gap and provide interpretable rationales, highlighting their value as assistive tools in fraud analysis.
CryptGNN: Enabling Secure Inference for Graph Neural Networks
Sep 11, 2025We present CryptGNN, a secure and effective inference solution for third-party graph neural network (GNN) models in the cloud, which are accessed by clients as ML as a service (MLaaS). The main novelty of CryptGNN is its secure message passing and feature transformation layers using distributed secure multi-party computation (SMPC) techniques. CryptGNN protects the client's input data and graph structure from the cloud provider and the third-party model owner, and it protects the model parameters from the cloud provider and the clients. CryptGNN works with any number of SMPC parties, does not require a trusted server, and is provably secure even if P-1 out of P parties in the cloud collude. Theoretical analysis and empirical experiments demonstrate the security and efficiency of CryptGNN.
Exploring a Hybrid Deep Learning Approach for Anomaly Detection in Mental Healthcare Provider Billing: Addressing Label Scarcity through Semi-Supervised Anomaly Detection
Jul 02, 2025
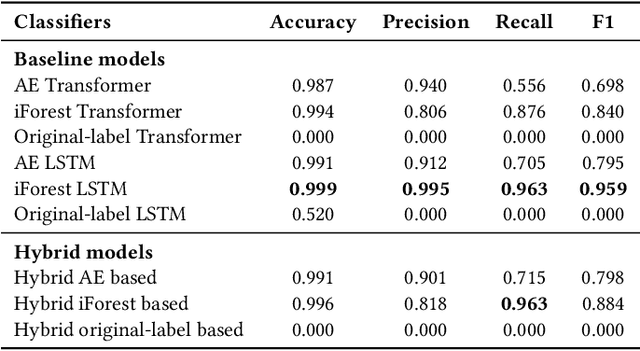


The complexity of mental healthcare billing enables anomalies, including fraud. While machine learning methods have been applied to anomaly detection, they often struggle with class imbalance, label scarcity, and complex sequential patterns. This study explores a hybrid deep learning approach combining Long Short-Term Memory (LSTM) networks and Transformers, with pseudo-labeling via Isolation Forests (iForest) and Autoencoders (AE). Prior work has not evaluated such hybrid models trained on pseudo-labeled data in the context of healthcare billing. The approach is evaluated on two real-world billing datasets related to mental healthcare. The iForest LSTM baseline achieves the highest recall (0.963) on declaration-level data. On the operation-level data, the hybrid iForest-based model achieves the highest recall (0.744), though at the cost of lower precision. These findings highlight the potential of combining pseudo-labeling with hybrid deep learning in complex, imbalanced anomaly detection settings.
Lessons Learned: A Multi-Agent Framework for Code LLMs to Learn and Improve
May 29, 2025Recent studies show that LLMs possess different skills and specialize in different tasks. In fact, we observe that their varied performance occur in several levels of granularity. For example, in the code optimization task, code LLMs excel at different optimization categories and no one dominates others. This observation prompts the question of how one leverages multiple LLM agents to solve a coding problem without knowing their complementary strengths a priori. We argue that a team of agents can learn from each other's successes and failures so as to improve their own performance. Thus, a lesson is the knowledge produced by an agent and passed on to other agents in the collective solution process. We propose a lesson-based collaboration framework, design the lesson solicitation--banking--selection mechanism, and demonstrate that a team of small LLMs with lessons learned can outperform a much larger LLM and other multi-LLM collaboration methods.
Diagnosing and Addressing Pitfalls in KG-RAG Datasets: Toward More Reliable Benchmarking
May 29, 2025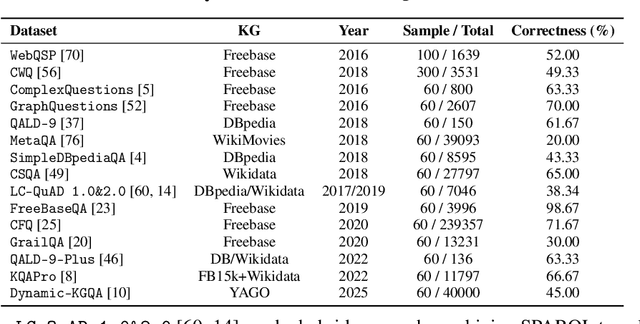
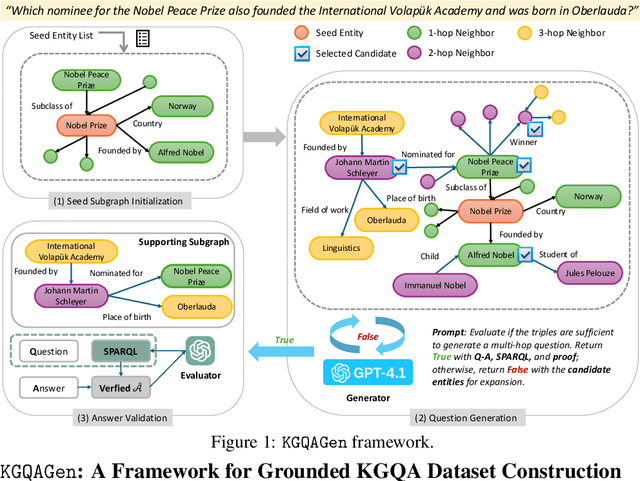

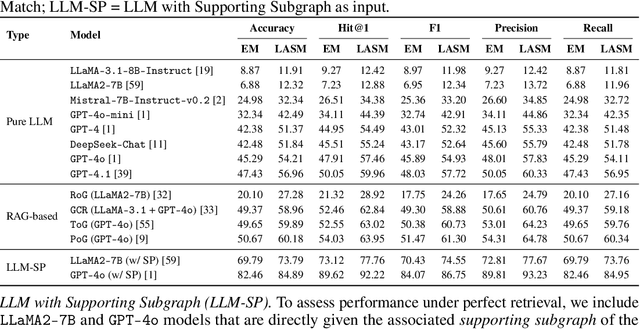
Knowledge Graph Question Answering (KGQA) systems rely on high-quality benchmarks to evaluate complex multi-hop reasoning. However, despite their widespread use, popular datasets such as WebQSP and CWQ suffer from critical quality issues, including inaccurate or incomplete ground-truth annotations, poorly constructed questions that are ambiguous, trivial, or unanswerable, and outdated or inconsistent knowledge. Through a manual audit of 16 popular KGQA datasets, including WebQSP and CWQ, we find that the average factual correctness rate is only 57 %. To address these issues, we introduce KGQAGen, an LLM-in-the-loop framework that systematically resolves these pitfalls. KGQAGen combines structured knowledge grounding, LLM-guided generation, and symbolic verification to produce challenging and verifiable QA instances. Using KGQAGen, we construct KGQAGen-10k, a ten-thousand scale benchmark grounded in Wikidata, and evaluate a diverse set of KG-RAG models. Experimental results demonstrate that even state-of-the-art systems struggle on this benchmark, highlighting its ability to expose limitations of existing models. Our findings advocate for more rigorous benchmark construction and position KGQAGen as a scalable framework for advancing KGQA evaluation.
A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models
May 25, 2025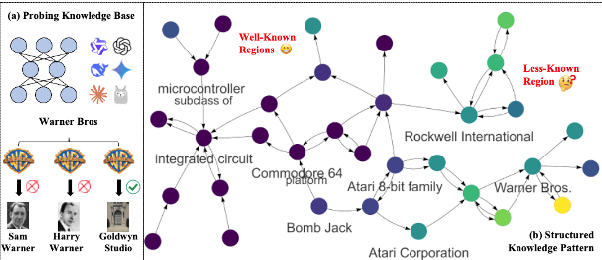
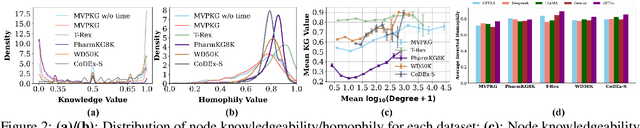
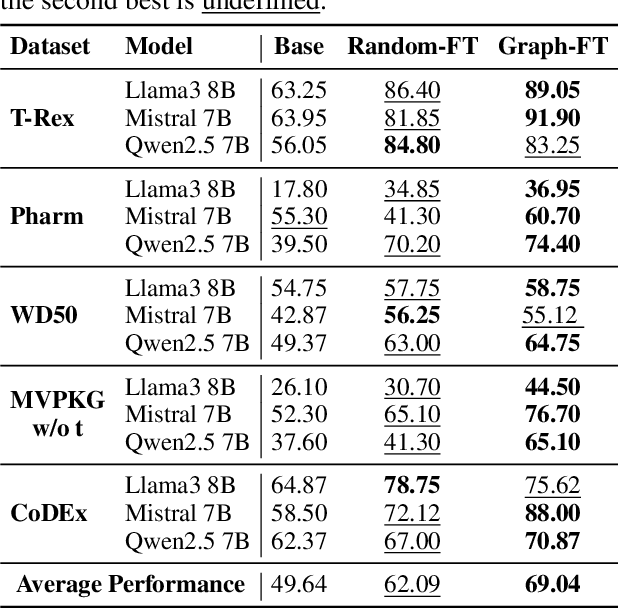
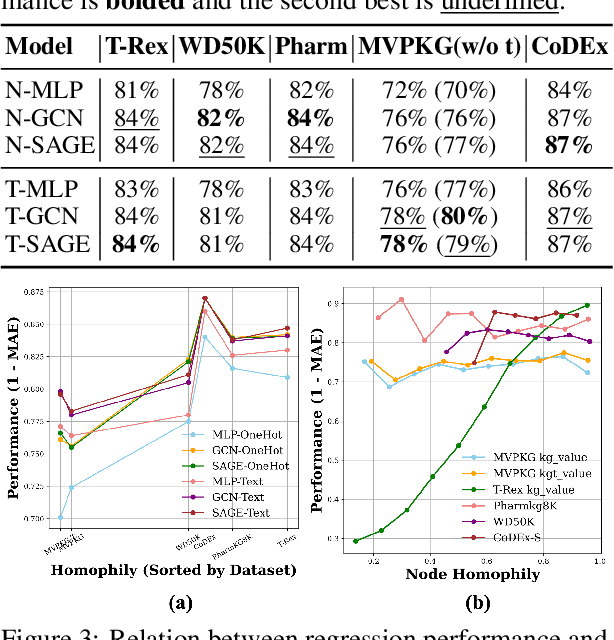
Large language models have been extensively studied as neural knowledge bases for their knowledge access, editability, reasoning, and explainability. However, few works focus on the structural patterns of their knowledge. Motivated by this gap, we investigate these structural patterns from a graph perspective. We quantify the knowledge of LLMs at both the triplet and entity levels, and analyze how it relates to graph structural properties such as node degree. Furthermore, we uncover the knowledge homophily, where topologically close entities exhibit similar levels of knowledgeability, which further motivates us to develop graph machine learning models to estimate entity knowledge based on its local neighbors. This model further enables valuable knowledge checking by selecting triplets less known to LLMs. Empirical results show that using selected triplets for fine-tuning leads to superior performance.
Towards Graph Foundation Models: A Transferability Perspective
Mar 12, 2025In recent years, Graph Foundation Models (GFMs) have gained significant attention for their potential to generalize across diverse graph domains and tasks. Some works focus on Domain-Specific GFMs, which are designed to address a variety of tasks within a specific domain, while others aim to create General-Purpose GFMs that extend the capabilities of domain-specific models to multiple domains. Regardless of the type, transferability is crucial for applying GFMs across different domains and tasks. However, achieving strong transferability is a major challenge due to the structural, feature, and distributional variations in graph data. To date, there has been no systematic research examining and analyzing GFMs from the perspective of transferability. To bridge the gap, we present the first comprehensive taxonomy that categorizes and analyzes existing GFMs through the lens of transferability, structuring GFMs around their application scope (domain-specific vs. general-purpose) and their approaches to knowledge acquisition and transfer. We provide a structured perspective on current progress and identify potential pathways for advancing GFM generalization across diverse graph datasets and tasks. We aims to shed light on the current landscape of GFMs and inspire future research directions in GFM development.
Exploring Graph Tasks with Pure LLMs: A Comprehensive Benchmark and Investigation
Feb 26, 2025Graph-structured data has become increasingly prevalent across various domains, raising the demand for effective models to handle graph tasks like node classification and link prediction. Traditional graph learning models like Graph Neural Networks (GNNs) have made significant strides, but their capabilities in handling graph data remain limited in certain contexts. In recent years, large language models (LLMs) have emerged as promising candidates for graph tasks, yet most studies focus primarily on performance benchmarks and fail to address their broader potential, including their ability to handle limited data, their transferability across tasks, and their robustness. In this work, we provide a comprehensive exploration of LLMs applied to graph tasks. We evaluate the performance of pure LLMs, including those without parameter optimization and those fine-tuned with instructions, across various scenarios. Our analysis goes beyond accuracy, assessing LLM ability to perform in few-shot/zero-shot settings, transfer across domains, understand graph structures, and demonstrate robustness in challenging scenarios. We conduct extensive experiments with 16 graph learning models alongside 6 LLMs (e.g., Llama3B, GPT-4o, Qwen-plus), comparing their performance on datasets like Cora, PubMed, ArXiv, and Products. Our findings show that LLMs, particularly those with instruction tuning, outperform traditional models in few-shot settings, exhibit strong domain transferability, and demonstrate excellent generalization and robustness. This work offers valuable insights into the capabilities of LLMs for graph learning, highlighting their advantages and potential for real-world applications, and paving the way for future research in this area. Codes and datasets are released in https://github.com/myflashbarry/LLM-benchmarking.
Unifying and Optimizing Data Values for Selection via Sequential-Decision-Making
Feb 06, 2025



Data selection has emerged as a crucial downstream application of data valuation. While existing data valuation methods have shown promise in selection tasks, the theoretical foundations and full potential of using data values for selection remain largely unexplored. In this work, we first demonstrate that data values applied for selection can be naturally reformulated as a sequential-decision-making problem, where the optimal data value can be derived through dynamic programming. We show this framework unifies and reinterprets existing methods like Data Shapley through the lens of approximate dynamic programming, specifically as myopic reward function approximations to this sequential problem. Furthermore, we analyze how sequential data selection optimality is affected when the ground-truth utility function exhibits monotonic submodularity with curvature. To address the computational challenges in obtaining optimal data values, we propose an efficient approximation scheme using learned bipartite graphs as surrogate utility models, ensuring greedy selection is still optimal when the surrogate utility is correctly specified and learned. Extensive experiments demonstrate the effectiveness of our approach across diverse datasets.
Reinforcement Learning for Quantum Circuit Design: Using Matrix Representations
Jan 27, 2025Quantum computing promises advantages over classical computing. The manufacturing of quantum hardware is in the infancy stage, called the Noisy Intermediate-Scale Quantum (NISQ) era. A major challenge is automated quantum circuit design that map a quantum circuit to gates in a universal gate set. In this paper, we present a generic MDP modeling and employ Q-learning and DQN algorithms for quantum circuit design. By leveraging the power of deep reinforcement learning, we aim to provide an automatic and scalable approach over traditional hand-crafted heuristic methods.