 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLmFPCA-detect: LLM-powered Multivariate Functional PCA for Anomaly Detection in Sparse Longitudinal Texts
Dec 16, 2025Sparse longitudinal (SL) textual data arises when individuals generate text repeatedly over time (e.g., customer reviews, occasional social media posts, electronic medical records across visits), but the frequency and timing of observations vary across individuals. These complex textual data sets have immense potential to inform future policy and targeted recommendations. However, because SL text data lack dedicated methods and are noisy, heterogeneous, and prone to anomalies, detecting and inferring key patterns is challenging. We introduce LLmFPCA-detect, a flexible framework that pairs LLM-based text embeddings with functional data analysis to detect clusters and infer anomalies in large SL text datasets. First, LLmFPCA-detect embeds each piece of text into an application-specific numeric space using LLM prompts. Sparse multivariate functional principal component analysis (mFPCA) conducted in the numeric space forms the workhorse to recover primary population characteristics, and produces subject-level scores which, together with baseline static covariates, facilitate data segmentation, unsupervised anomaly detection and inference, and enable other downstream tasks. In particular, we leverage LLMs to perform dynamic keyword profiling guided by the data segments and anomalies discovered by LLmFPCA-detect, and we show that cluster-specific functional PC scores from LLmFPCA-detect, used as features in existing pipelines, help boost prediction performance. We support the stability of LLmFPCA-detect with experiments and evaluate it on two different applications using public datasets, Amazon customer-review trajectories, and Wikipedia talk-page comment streams, demonstrating utility across domains and outperforming state-of-the-art baselines.
Diagnosing and Addressing Pitfalls in KG-RAG Datasets: Toward More Reliable Benchmarking
May 29, 2025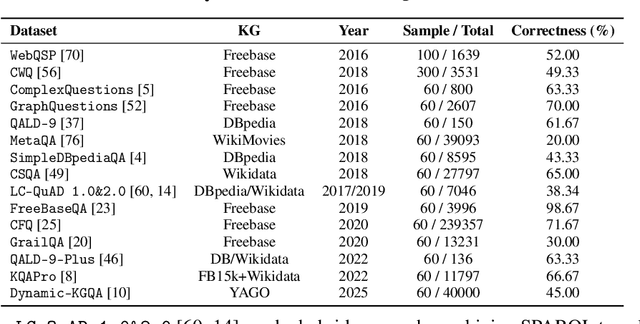
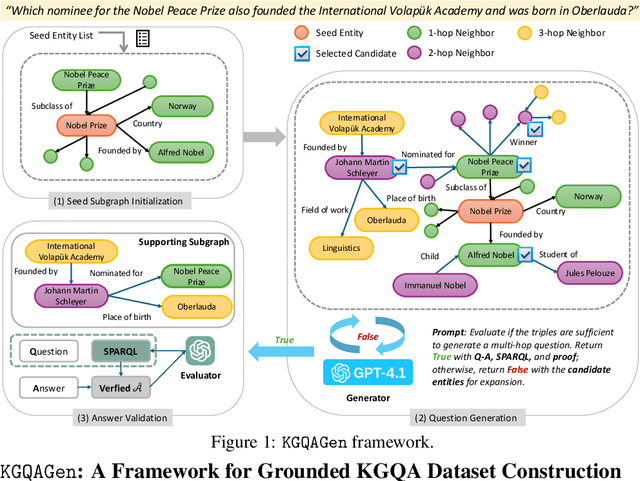

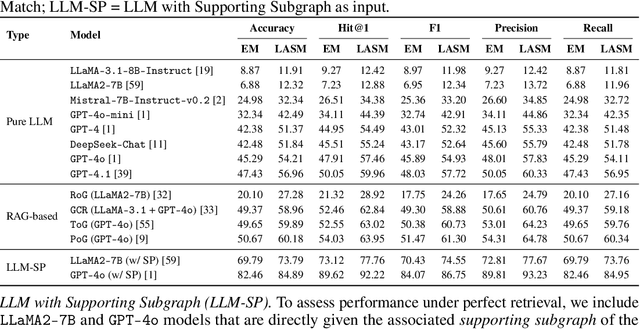
Knowledge Graph Question Answering (KGQA) systems rely on high-quality benchmarks to evaluate complex multi-hop reasoning. However, despite their widespread use, popular datasets such as WebQSP and CWQ suffer from critical quality issues, including inaccurate or incomplete ground-truth annotations, poorly constructed questions that are ambiguous, trivial, or unanswerable, and outdated or inconsistent knowledge. Through a manual audit of 16 popular KGQA datasets, including WebQSP and CWQ, we find that the average factual correctness rate is only 57 %. To address these issues, we introduce KGQAGen, an LLM-in-the-loop framework that systematically resolves these pitfalls. KGQAGen combines structured knowledge grounding, LLM-guided generation, and symbolic verification to produce challenging and verifiable QA instances. Using KGQAGen, we construct KGQAGen-10k, a ten-thousand scale benchmark grounded in Wikidata, and evaluate a diverse set of KG-RAG models. Experimental results demonstrate that even state-of-the-art systems struggle on this benchmark, highlighting its ability to expose limitations of existing models. Our findings advocate for more rigorous benchmark construction and position KGQAGen as a scalable framework for advancing KGQA evaluation.
Unifying and Optimizing Data Values for Selection via Sequential-Decision-Making
Feb 06, 2025



Data selection has emerged as a crucial downstream application of data valuation. While existing data valuation methods have shown promise in selection tasks, the theoretical foundations and full potential of using data values for selection remain largely unexplored. In this work, we first demonstrate that data values applied for selection can be naturally reformulated as a sequential-decision-making problem, where the optimal data value can be derived through dynamic programming. We show this framework unifies and reinterprets existing methods like Data Shapley through the lens of approximate dynamic programming, specifically as myopic reward function approximations to this sequential problem. Furthermore, we analyze how sequential data selection optimality is affected when the ground-truth utility function exhibits monotonic submodularity with curvature. To address the computational challenges in obtaining optimal data values, we propose an efficient approximation scheme using learned bipartite graphs as surrogate utility models, ensuring greedy selection is still optimal when the surrogate utility is correctly specified and learned. Extensive experiments demonstrate the effectiveness of our approach across diverse datasets.
SkinMamba: A Precision Skin Lesion Segmentation Architecture with Cross-Scale Global State Modeling and Frequency Boundary Guidance
Sep 17, 2024



Skin lesion segmentation is a crucial method for identifying early skin cancer. In recent years, both convolutional neural network (CNN) and Transformer-based methods have been widely applied. Moreover, combining CNN and Transformer effectively integrates global and local relationships, but remains limited by the quadratic complexity of Transformer. To address this, we propose a hybrid architecture based on Mamba and CNN, called SkinMamba. It maintains linear complexity while offering powerful long-range dependency modeling and local feature extraction capabilities. Specifically, we introduce the Scale Residual State Space Block (SRSSB), which captures global contextual relationships and cross-scale information exchange at a macro level, enabling expert communication in a global state. This effectively addresses challenges in skin lesion segmentation related to varying lesion sizes and inconspicuous target areas. Additionally, to mitigate boundary blurring and information loss during model downsampling, we introduce the Frequency Boundary Guided Module (FBGM), providing sufficient boundary priors to guide precise boundary segmentation, while also using the retained information to assist the decoder in the decoding process. Finally, we conducted comparative and ablation experiments on two public lesion segmentation datasets (ISIC2017 and ISIC2018), and the results demonstrate the strong competitiveness of SkinMamba in skin lesion segmentation tasks. The code is available at https://github.com/zs1314/SkinMamba.
CAT: Interpretable Concept-based Taylor Additive Models
Jun 27, 2024As an emerging interpretable technique, Generalized Additive Models (GAMs) adopt neural networks to individually learn non-linear functions for each feature, which are then combined through a linear model for final predictions. Although GAMs can explain deep neural networks (DNNs) at the feature level, they require large numbers of model parameters and are prone to overfitting, making them hard to train and scale. Additionally, in real-world datasets with many features, the interpretability of feature-based explanations diminishes for humans. To tackle these issues, recent research has shifted towards concept-based interpretable methods. These approaches try to integrate concept learning as an intermediate step before making predictions, explaining the predictions in terms of human-understandable concepts. However, these methods require domain experts to extensively label concepts with relevant names and their ground-truth values. In response, we propose CAT, a novel interpretable Concept-bAsed Taylor additive model to simply this process. CAT does not have to require domain experts to annotate concepts and their ground-truth values. Instead, it only requires users to simply categorize input features into broad groups, which can be easily accomplished through a quick metadata review. Specifically, CAT first embeds each group of input features into one-dimensional high-level concept representation, and then feeds the concept representations into a new white-box Taylor Neural Network (TaylorNet). The TaylorNet aims to learn the non-linear relationship between the inputs and outputs using polynomials. Evaluation results across multiple benchmarks demonstrate that CAT can outperform or compete with the baselines while reducing the need of extensive model parameters. Importantly, it can explain model predictions through high-level concepts that human can understand.
General-Purpose Multi-Modal OOD Detection Framework
Jul 24, 2023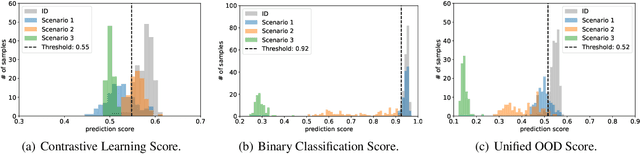

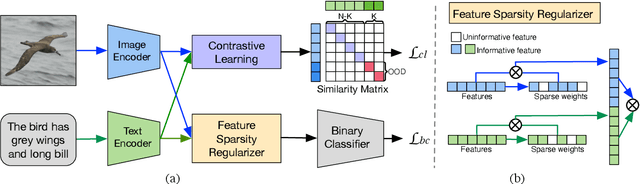

Out-of-distribution (OOD) detection identifies test samples that differ from the training data, which is critical to ensuring the safety and reliability of machine learning (ML) systems. While a plethora of methods have been developed to detect uni-modal OOD samples, only a few have focused on multi-modal OOD detection. Current contrastive learning-based methods primarily study multi-modal OOD detection in a scenario where both a given image and its corresponding textual description come from a new domain. However, real-world deployments of ML systems may face more anomaly scenarios caused by multiple factors like sensor faults, bad weather, and environmental changes. Hence, the goal of this work is to simultaneously detect from multiple different OOD scenarios in a fine-grained manner. To reach this goal, we propose a general-purpose weakly-supervised OOD detection framework, called WOOD, that combines a binary classifier and a contrastive learning component to reap the benefits of both. In order to better distinguish the latent representations of in-distribution (ID) and OOD samples, we adopt the Hinge loss to constrain their similarity. Furthermore, we develop a new scoring metric to integrate the prediction results from both the binary classifier and contrastive learning for identifying OOD samples. We evaluate the proposed WOOD model on multiple real-world datasets, and the experimental results demonstrate that the WOOD model outperforms the state-of-the-art methods for multi-modal OOD detection. Importantly, our approach is able to achieve high accuracy in OOD detection in three different OOD scenarios simultaneously. The source code will be made publicly available upon publication.
Towards Algorithmic Fairness in Space-Time: Filling in Black Holes
Nov 08, 2022New technologies and the availability of geospatial data have drawn attention to spatio-temporal biases present in society. For example: the COVID-19 pandemic highlighted disparities in the availability of broadband service and its role in the digital divide; the environmental justice movement in the United States has raised awareness to health implications for minority populations stemming from historical redlining practices; and studies have found varying quality and coverage in the collection and sharing of open-source geospatial data. Despite the extensive literature on machine learning (ML) fairness, few algorithmic strategies have been proposed to mitigate such biases. In this paper we highlight the unique challenges for quantifying and addressing spatio-temporal biases, through the lens of use cases presented in the scientific literature and media. We envision a roadmap of ML strategies that need to be developed or adapted to quantify and overcome these challenges -- including transfer learning, active learning, and reinforcement learning techniques. Further, we discuss the potential role of ML in providing guidance to policy makers on issues related to spatial fairness.
Information Extraction with Character-level Neural Networks and Free Noisy Supervision
Jan 24, 2017
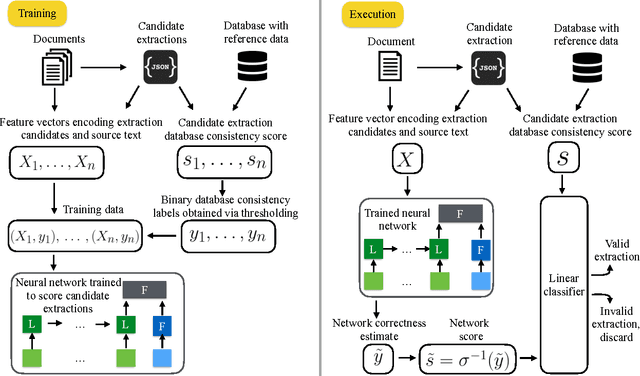
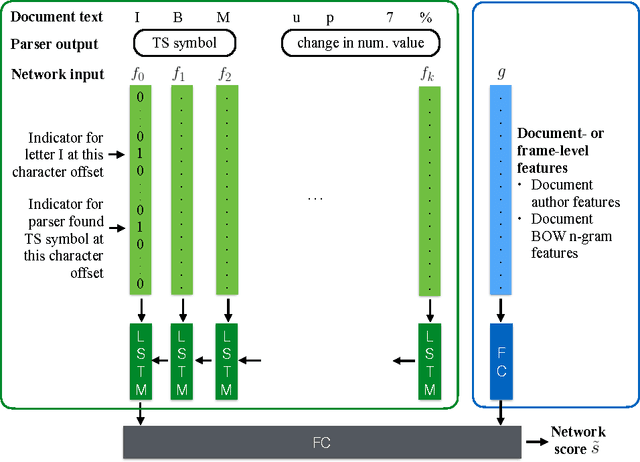
We present an architecture for information extraction from text that augments an existing parser with a character-level neural network. The network is trained using a measure of consistency of extracted data with existing databases as a form of noisy supervision. Our architecture combines the ability of constraint-based information extraction systems to easily incorporate domain knowledge and constraints with the ability of deep neural networks to leverage large amounts of data to learn complex features. Boosting the existing parser's precision, the system led to large improvements over a mature and highly tuned constraint-based production information extraction system used at Bloomberg for financial language text.
Quantifying Urban Traffic Anomalies
Sep 30, 2016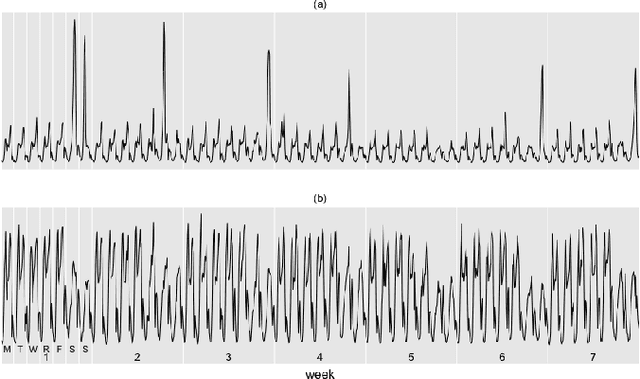
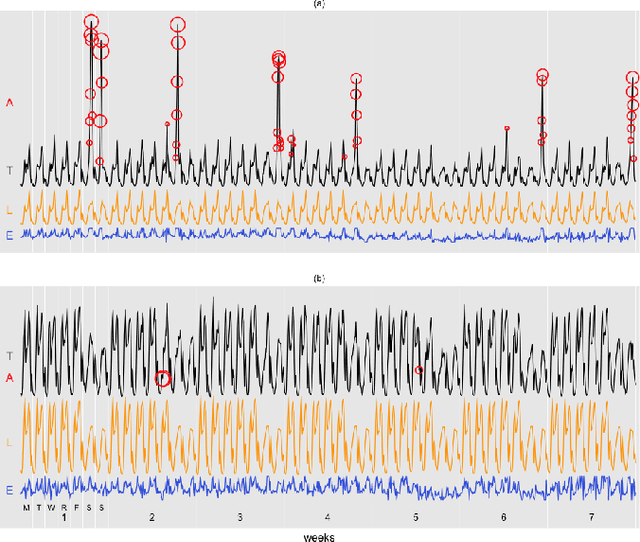
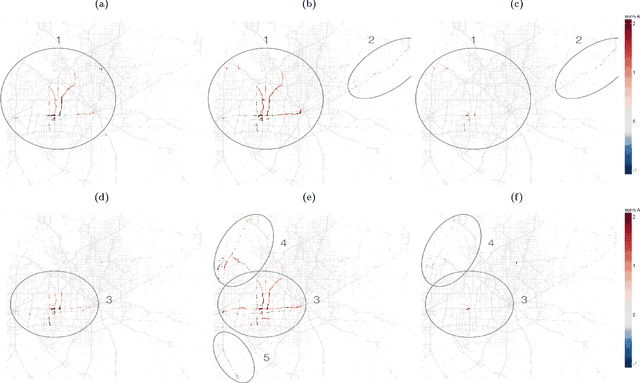
Detecting and quantifying anomalies in urban traffic is critical for real-time alerting or re-routing in the short run and urban planning in the long run. We describe a two-step framework that achieves these two goals in a robust, fast, online, and unsupervised manner. First, we adapt stable principal component pursuit to detect anomalies for each road segment. This allows us to pinpoint traffic anomalies early and precisely in space. Then we group the road-level anomalies across time and space into meaningful anomaly events using a simple graph expansion procedure. These events can be easily clustered, visualized, and analyzed by urban planners. We demonstrate the effectiveness of our system using 7 weeks of anonymized and aggregated cellular location data in Dallas-Fort Worth. We suggest potential opportunities for urban planners and policy makers to use our methodology to make informed changes. These applications include real-time re-routing of traffic in response to abnormally high traffic, or identifying candidates for high-impact infrastructure projects.
Predicting Ambulance Demand: Challenges and Methods
Jun 16, 2016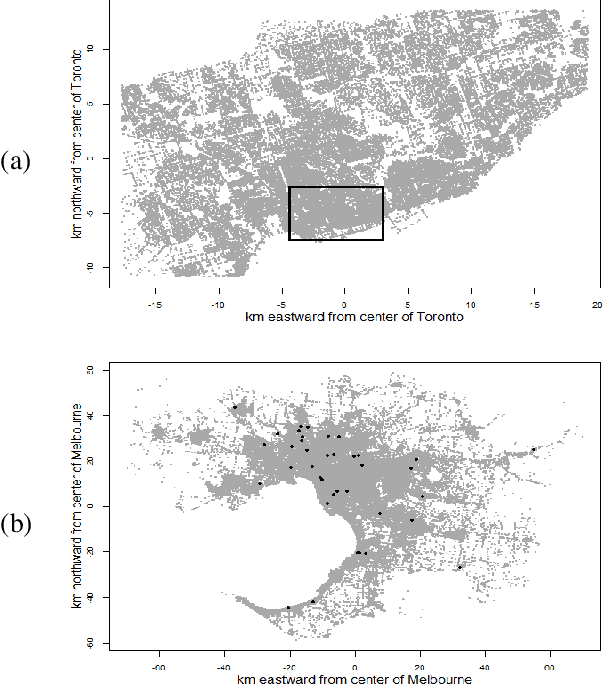
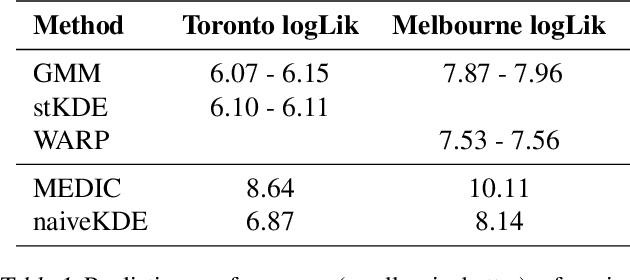
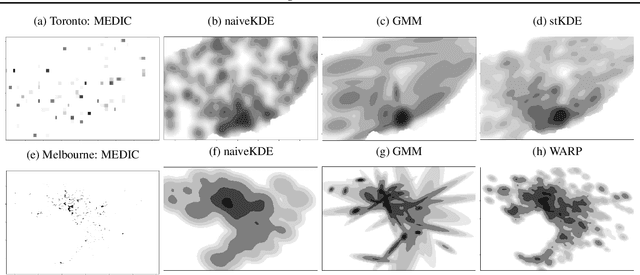
Predicting ambulance demand accurately at a fine resolution in time and space (e.g., every hour and 1 km$^2$) is critical for staff / fleet management and dynamic deployment. There are several challenges: though the dataset is typically large-scale, demand per time period and locality is almost always zero. The demand arises from complex urban geography and exhibits complex spatio-temporal patterns, both of which need to captured and exploited. To address these challenges, we propose three methods based on Gaussian mixture models, kernel density estimation, and kernel warping. These methods provide spatio-temporal predictions for Toronto and Melbourne that are significantly more accurate than the current industry practice.