 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUBEN: Rule-Based Explanations for Retrieval-Augmented LLM Systems
May 11, 2026This paper demonstrates RUBEN, an interactive tool for discovering minimal rules to explain the outputs of retrieval-augmented large language models (LLMs) in data-driven applications. We leverage novel pruning strategies to efficiently identify a minimal set of rules that subsume all others. We further demonstrate novel applications of these rules for LLM safety, specifically to test the resiliency of safety training and effectiveness of adversarial prompt injections.
Rule-Based Explanations for Retrieval-Augmented LLM Systems
Oct 26, 2025If-then rules are widely used to explain machine learning models; e.g., "if employed = no, then loan application = rejected." We present the first proposal to apply rules to explain the emerging class of large language models (LLMs) with retrieval-augmented generation (RAG). Since RAG enables LLM systems to incorporate retrieved information sources at inference time, rules linking the presence or absence of sources can explain output provenance; e.g., "if a Times Higher Education ranking article is retrieved, then the LLM ranks Oxford first." To generate such rules, a brute force approach would probe the LLM with all source combinations and check if the presence or absence of any sources leads to the same output. We propose optimizations to speed up rule generation, inspired by Apriori-like pruning from frequent itemset mining but redefined within the scope of our novel problem. We conclude with qualitative and quantitative experiments demonstrating our solutions' value and efficiency.
FairEM360: A Suite for Responsible Entity Matching
Apr 10, 2024Entity matching is one the earliest tasks that occur in the big data pipeline and is alarmingly exposed to unintentional biases that affect the quality of data. Identifying and mitigating the biases that exist in the data or are introduced by the matcher at this stage can contribute to promoting fairness in downstream tasks. This demonstration showcases FairEM360, a framework for 1) auditing the output of entity matchers across a wide range of fairness measures and paradigms, 2) providing potential explanations for the underlying reasons for unfairness, and 3) providing resolutions for the unfairness issues through an exploratory process with human-in-the-loop feedback, utilizing an ensemble of matchers. We aspire for FairEM360 to contribute to the prioritization of fairness as a key consideration in the evaluation of EM pipelines.
Through the Fairness Lens: Experimental Analysis and Evaluation of Entity Matching
Jul 06, 2023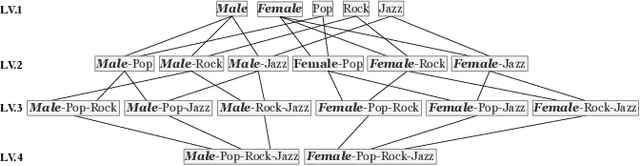

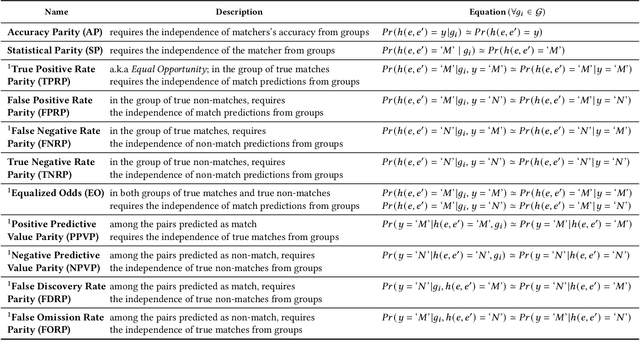
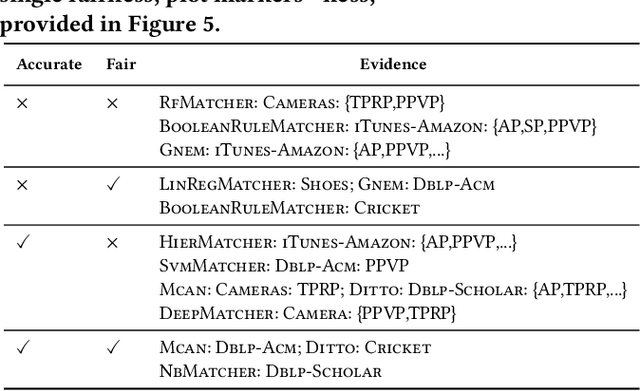
Entity matching (EM) is a challenging problem studied by different communities for over half a century. Algorithmic fairness has also become a timely topic to address machine bias and its societal impacts. Despite extensive research on these two topics, little attention has been paid to the fairness of entity matching. Towards addressing this gap, we perform an extensive experimental evaluation of a variety of EM techniques in this paper. We generated two social datasets from publicly available datasets for the purpose of auditing EM through the lens of fairness. Our findings underscore potential unfairness under two common conditions in real-world societies: (i) when some demographic groups are overrepresented, and (ii) when names are more similar in some groups compared to others. Among our many findings, it is noteworthy to mention that while various fairness definitions are valuable for different settings, due to EM's class imbalance nature, measures such as positive predictive value parity and true positive rate parity are, in general, more capable of revealing EM unfairness.
CREDENCE: Counterfactual Explanations for Document Ranking
Feb 10, 2023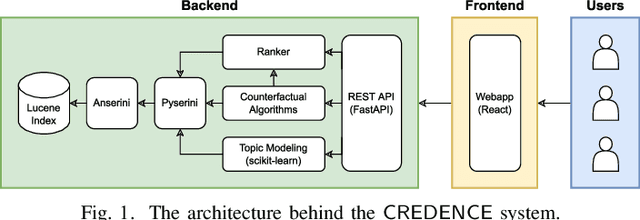
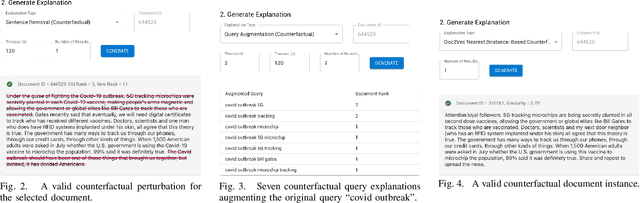
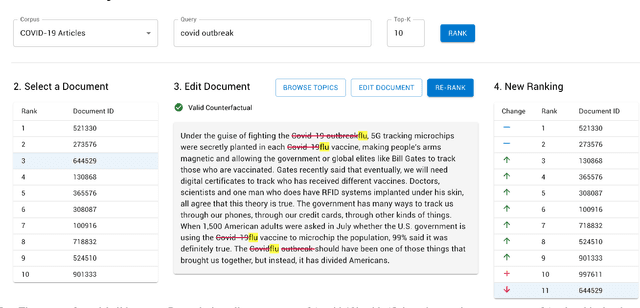
Towards better explainability in the field of information retrieval, we present CREDENCE, an interactive tool capable of generating counterfactual explanations for document rankers. Embracing the unique properties of the ranking problem, we present counterfactual explanations in terms of document perturbations, query perturbations, and even other documents. Additionally, users may build and test their own perturbations, and extract insights about their query, documents, and ranker.
Towards Algorithmic Fairness in Space-Time: Filling in Black Holes
Nov 08, 2022New technologies and the availability of geospatial data have drawn attention to spatio-temporal biases present in society. For example: the COVID-19 pandemic highlighted disparities in the availability of broadband service and its role in the digital divide; the environmental justice movement in the United States has raised awareness to health implications for minority populations stemming from historical redlining practices; and studies have found varying quality and coverage in the collection and sharing of open-source geospatial data. Despite the extensive literature on machine learning (ML) fairness, few algorithmic strategies have been proposed to mitigate such biases. In this paper we highlight the unique challenges for quantifying and addressing spatio-temporal biases, through the lens of use cases presented in the scientific literature and media. We envision a roadmap of ML strategies that need to be developed or adapted to quantify and overcome these challenges -- including transfer learning, active learning, and reinforcement learning techniques. Further, we discuss the potential role of ML in providing guidance to policy makers on issues related to spatial fairness.
Effective Explanations for Entity Resolution Models
Apr 01, 2022

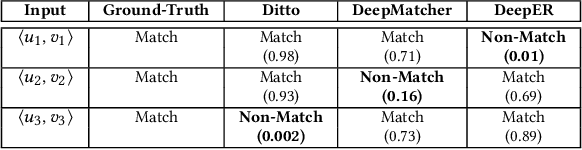
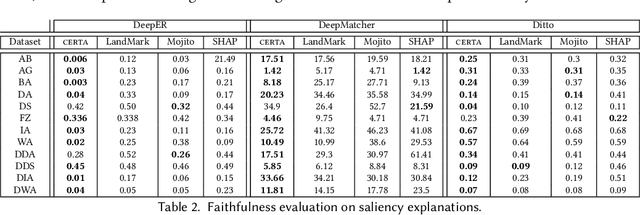
Entity resolution (ER) aims at matching records that refer to the same real-world entity. Although widely studied for the last 50 years, ER still represents a challenging data management problem, and several recent works have started to investigate the opportunity of applying deep learning (DL) techniques to solve this problem. In this paper, we study the fundamental problem of explainability of the DL solution for ER. Understanding the matching predictions of an ER solution is indeed crucial to assess the trustworthiness of the DL model and to discover its biases. We treat the DL model as a black box classifier and - while previous approaches to provide explanations for DL predictions are agnostic to the classification task. we propose the CERTA approach that is aware of the semantics of the ER problem. Our approach produces both saliency explanations, which associate each attribute with a saliency score, and counterfactual explanations, which provide examples of values that can flip the prediction. CERTA builds on a probabilistic framework that aims at computing the explanations evaluating the outcomes produced by using perturbed copies of the input records. We experimentally evaluate CERTA's explanations of state-of-the-art ER solutions based on DL models using publicly available datasets, and demonstrate the effectiveness of CERTA over recently proposed methods for this problem.
Sailing the Information Ocean with Awareness of Currents: Discovery and Application of Source Dependence
Sep 09, 2009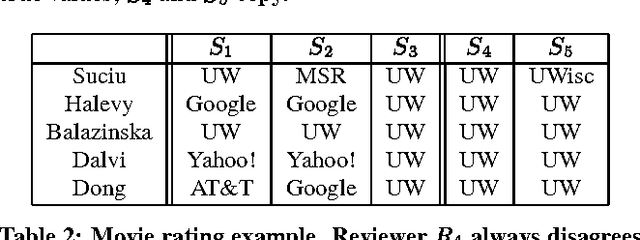


The Web has enabled the availability of a huge amount of useful information, but has also eased the ability to spread false information and rumors across multiple sources, making it hard to distinguish between what is true and what is not. Recent examples include the premature Steve Jobs obituary, the second bankruptcy of United airlines, the creation of Black Holes by the operation of the Large Hadron Collider, etc. Since it is important to permit the expression of dissenting and conflicting opinions, it would be a fallacy to try to ensure that the Web provides only consistent information. However, to help in separating the wheat from the chaff, it is essential to be able to determine dependence between sources. Given the huge number of data sources and the vast volume of conflicting data available on the Web, doing so in a scalable manner is extremely challenging and has not been addressed by existing work yet. In this paper, we present a set of research problems and propose some preliminary solutions on the issues involved in discovering dependence between sources. We also discuss how this knowledge can benefit a variety of technologies, such as data integration and Web 2.0, that help users manage and access the totality of the available information from various sources.