 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Current Boundaries: Integrating Deep Learning and AlphaFold for Enhanced Protein Structure Prediction from Low-Resolution Cryo-EM Maps
Oct 30, 2024


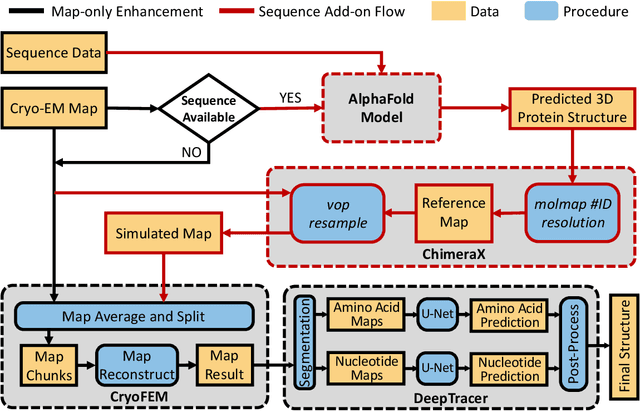
Constructing atomic models from cryo-electron microscopy (cryo-EM) maps is a crucial yet intricate task in structural biology. While advancements in deep learning, such as convolutional neural networks (CNNs) and graph neural networks (GNNs), have spurred the development of sophisticated map-to-model tools like DeepTracer and ModelAngelo, their efficacy notably diminishes with low-resolution maps beyond 4 {\AA}. To address this shortfall, our research introduces DeepTracer-LowResEnhance, an innovative framework that synergizes a deep learning-enhanced map refinement technique with the power of AlphaFold. This methodology is designed to markedly improve the construction of models from low-resolution cryo-EM maps. DeepTracer-LowResEnhance was rigorously tested on a set of 37 protein cryo-EM maps, with resolutions ranging between 2.5 to 8.4 {\AA}, including 22 maps with resolutions lower than 4 {\AA}. The outcomes were compelling, demonstrating that 95.5\% of the low-resolution maps exhibited a significant uptick in the count of total predicted residues. This denotes a pronounced improvement in atomic model building for low-resolution maps. Additionally, a comparative analysis alongside Phenix's auto-sharpening functionality delineates DeepTracer-LowResEnhance's superior capability in rendering more detailed and precise atomic models, thereby pushing the boundaries of current computational structural biology methodologies.
Neuron's Eye View: Inferring Features of Complex Stimuli from Neural Responses
Nov 21, 2016



Experiments that study neural encoding of stimuli at the level of individual neurons typically choose a small set of features present in the world --- contrast and luminance for vision, pitch and intensity for sound --- and assemble a stimulus set that systematically varies along these dimensions. Subsequent analysis of neural responses to these stimuli typically focuses on regression models, with experimenter-controlled features as predictors and spike counts or firing rates as responses. Unfortunately, this approach requires knowledge in advance about the relevant features coded by a given population of neurons. For domains as complex as social interaction or natural movement, however, the relevant feature space is poorly understood, and an arbitrary \emph{a priori} choice of features may give rise to confirmation bias. Here, we present a Bayesian model for exploratory data analysis that is capable of automatically identifying the features present in unstructured stimuli based solely on neuronal responses. Our approach is unique within the class of latent state space models of neural activity in that it assumes that firing rates of neurons are sensitive to multiple discrete time-varying features tied to the \emph{stimulus}, each of which has Markov (or semi-Markov) dynamics. That is, we are modeling neural activity as driven by multiple simultaneous stimulus features rather than intrinsic neural dynamics. We derive a fast variational Bayesian inference algorithm and show that it correctly recovers hidden features in synthetic data, as well as ground-truth stimulus features in a prototypical neural dataset. To demonstrate the utility of the algorithm, we also apply it to cluster neural responses and demonstrate successful recovery of features corresponding to monkeys and faces in the image set.
Sailing the Information Ocean with Awareness of Currents: Discovery and Application of Source Dependence
Sep 09, 2009


The Web has enabled the availability of a huge amount of useful information, but has also eased the ability to spread false information and rumors across multiple sources, making it hard to distinguish between what is true and what is not. Recent examples include the premature Steve Jobs obituary, the second bankruptcy of United airlines, the creation of Black Holes by the operation of the Large Hadron Collider, etc. Since it is important to permit the expression of dissenting and conflicting opinions, it would be a fallacy to try to ensure that the Web provides only consistent information. However, to help in separating the wheat from the chaff, it is essential to be able to determine dependence between sources. Given the huge number of data sources and the vast volume of conflicting data available on the Web, doing so in a scalable manner is extremely challenging and has not been addressed by existing work yet. In this paper, we present a set of research problems and propose some preliminary solutions on the issues involved in discovering dependence between sources. We also discuss how this knowledge can benefit a variety of technologies, such as data integration and Web 2.0, that help users manage and access the totality of the available information from various sources.