 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealICU: Do LLM Agents Understand Long-Context ICU Data? A Benchmark Beyond Behavior Imitation
May 13, 2026Intensive care units (ICU) generate long, dense and evolving streams of clinical information, where physicians must repeatedly reassess patient states under time pressure, underscoring a clear need for reliable AI decision support. Existing ICU benchmarks typically treat historical clinician actions as ground truth. However, these actions are made under incomplete information and limited temporal context of the underlying patient state, and may therefore be suboptimal, making it difficult to assess the true reasoning capabilities of AI systems. We introduce RealICU, a hindsight-annotated benchmark for evaluating large language models (LLMs) under realistic ICU conditions, where labels are created after senior physicians review the full patient trajectory. We formulate four physician-motivated tasks: assess Patient Status, Acute Problems, Recommended Actions, and Red Flag actions that risk unsafe outcomes. We partition each trajectory with 30-min windows and release two datasets: RealICU-Gold with 930-window annotations from 94 MIMIC-IV patients, and RealICU-Scale with 11,862 windows extended by Oracle, a physician-validated LLM hindsight labeler. Existing LLMs including memory-augmented ones performed poorly on RealICU, exposing two failure modes: a recall-safety tradeoff for clinical recommendations, and an anchoring bias to early interpretations of the patient. We further introduce ICU-Evo to study structured-memory agents that improves long-horizon reasoning but does not fully eliminate safety failures. Together, RealICU provides a clinically grounded testbed for measuring and improving AI sequential decision-support in high-stakes care. Project page: https://chengzhi-leo.github.io/RealICU-Bench/
IPI-proxy: An Intercepting Proxy for Red-Teaming Web-Browsing AI Agents Against Indirect Prompt Injection
May 12, 2026Web-browsing AI agents are increasingly deployed in enterprise settings under strict whitelists of approved domains, yet adversaries can still influence them by embedding hidden instructions in the HTML pages those domains serve. Existing red-teaming resources fall short of this scenario: prompt-injection benchmarks ship pre-built adversarial pages that whitelisted agents cannot reach, and generic LLM scanners probe the model API rather than its retrieved content. We present IPI-proxy, an open-source toolkit for red-teaming web-browsing agents against indirect prompt injection (IPI). At its core is an intercepting proxy that rewrites real HTTP responses from whitelisted domains in flight, embedding payloads drawn from a unified library of 820 deduplicated attack strings extracted from six published benchmarks (BIPIA, InjecAgent, AgentDojo, Tensor Trust, WASP, and LLMail-Inject). A YAML-driven test harness independently parameterizes the payload set, the embedding technique (HTML comment, invisible CSS, or LLM-generated semantic prose), and the HTML insertion point (6 locations from \icode{head\_meta} to \icode{script\_comment}), enabling parameter-sweep evaluation without mock pages or sandboxed environments. A companion exfiltration tracker logs successful callbacks. This paper describes the threat model, situates IPI-proxy among contemporary IPI benchmarks and red-teaming tools, and details its architecture, design decisions, and configuration interface. By bridging static benchmarks and live deployment, IPI-proxy gives AI security teams a reproducible substrate for measuring and hardening web-browsing agents against indirect prompt injection on the same retrieval surface attackers exploit in production.
Dialogue Act Patterns in GenAI-Mediated L2 Oral Practice: A Sequential Analysis of Learner-Chatbot Interactions
Apr 07, 2026While generative AI (GenAI) voice chatbots offer scalable opportunities for second language (L2) oral practice, the interactional processes related to learners' gains remain underexplored. This study investigates dialogue act (DA) patterns in interactions between Grade 9 Chinese English as a foreign language (EFL) learners and a GenAI voice chatbot over a 10-week intervention. Seventy sessions from 12 students were annotated by human coders using a pedagogy-informed coding scheme, yielding 6,957 coded DAs. DA distributions and sequential patterns were compared between high- and low-progress sessions. At the DA level, high-progress sessions showed more learner-initiated questions, whereas low-progress sessions exhibited higher rates of clarification-seeking, indicating greater comprehension difficulty. At the sequential level, high-progress sessions were characterised by more frequent prompting-based corrective feedback sequences, consistently positioned after learner responses, highlighting the role of feedback type and timing in effective interaction. Overall, these findings underscore the value of a dialogic lens in GenAI chatbot design, contribute a pedagogy-informed DA coding framework, and inform the design of adaptive GenAI chatbots for L2 education.
Towards Structured, State-Aware, and Execution-Grounded Reasoning for Software Engineering Agents
Feb 04, 2026Software Engineering (SE) agents have shown promising abilities in supporting various SE tasks. Current SE agents remain fundamentally reactive, making decisions mainly based on conversation history and the most recent response. However, this reactive design provides no explicit structure or persistent state within the agent's memory, making long-horizon reasoning challenging. As a result, SE agents struggle to maintain a coherent understanding across reasoning steps, adapt their hypotheses as new evidence emerges, or incorporate execution feedback into the mental reasoning model of the system state. In this position paper, we argue that, to further advance SE agents, we need to move beyond reactive behavior toward a structured, state-aware, and execution-grounded reasoning. We outline how explicit structure, persistent and evolving state, and the integration of execution-grounded feedback can help SE agents perform more coherent and reliable reasoning in long-horizon tasks. We also provide an initial roadmap for developing next-generation SE agents that can more effectively perform real-world tasks.
Does Privacy Always Harm Fairness? Data-Dependent Trade-offs via Chernoff Information Neural Estimation
Jan 20, 2026Fairness and privacy are two vital pillars of trustworthy machine learning. Despite extensive research on these individual topics, the relationship between fairness and privacy has received significantly less attention. In this paper, we utilize the information-theoretic measure Chernoff Information to highlight the data-dependent nature of the relationship among the triad of fairness, privacy, and accuracy. We first define Noisy Chernoff Difference, a tool that allows us to analyze the relationship among the triad simultaneously. We then show that for synthetic data, this value behaves in 3 distinct ways (depending on the distribution of the data). We highlight the data distributions involved in these cases and explore their fairness and privacy implications. Additionally, we show that Noisy Chernoff Difference acts as a proxy for the steepness of the fairness-accuracy curves. Finally, we propose a method for estimating Chernoff Information on data from unknown distributions and utilize this framework to examine the triad dynamic on real datasets. This work builds towards a unified understanding of the fairness-privacy-accuracy relationship and highlights its data-dependent nature.
Diffusion Large Language Models for Black-Box Optimization
Jan 20, 2026Offline black-box optimization (BBO) aims to find optimal designs based solely on an offline dataset of designs and their labels. Such scenarios frequently arise in domains like DNA sequence design and robotics, where only a few labeled data points are available. Traditional methods typically rely on task-specific proxy or generative models, overlooking the in-context learning capabilities of pre-trained large language models (LLMs). Recent efforts have adapted autoregressive LLMs to BBO by framing task descriptions and offline datasets as natural language prompts, enabling direct design generation. However, these designs often contain bidirectional dependencies, which left-to-right models struggle to capture. In this paper, we explore diffusion LLMs for BBO, leveraging their bidirectional modeling and iterative refinement capabilities. This motivates our in-context denoising module: we condition the diffusion LLM on the task description and the offline dataset, both formatted in natural language, and prompt it to denoise masked designs into improved candidates. To guide the generation toward high-performing designs, we introduce masked diffusion tree search, which casts the denoising process as a step-wise Monte Carlo Tree Search that dynamically balances exploration and exploitation. Each node represents a partially masked design, each denoising step is an action, and candidates are evaluated via expected improvement under a Gaussian Process trained on the offline dataset. Our method, dLLM, achieves state-of-the-art results in few-shot settings on design-bench.
Seeing Beyond the Image: ECG and Anatomical Knowledge-Guided Myocardial Scar Segmentation from Late Gadolinium-Enhanced Images
Nov 18, 2025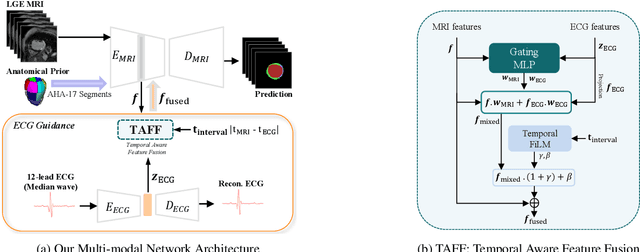
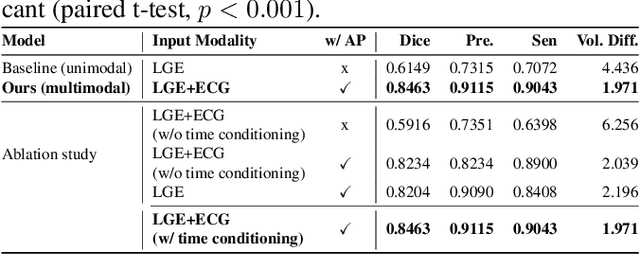
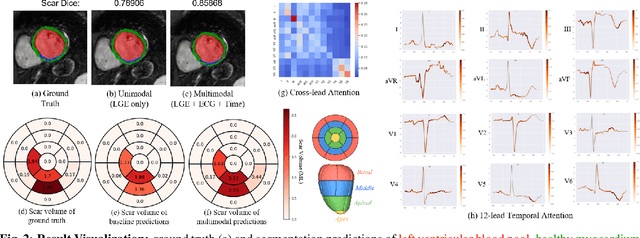
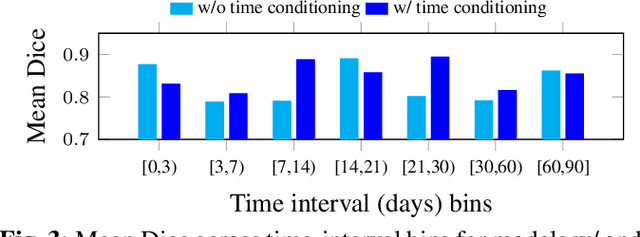
Accurate segmentation of myocardial scar from late gadolinium enhanced (LGE) cardiac MRI is essential for evaluating tissue viability, yet remains challenging due to variable contrast and imaging artifacts. Electrocardiogram (ECG) signals provide complementary physiological information, as conduction abnormalities can help localize or suggest scarred myocardial regions. In this work, we propose a novel multimodal framework that integrates ECG-derived electrophysiological information with anatomical priors from the AHA-17 atlas for physiologically consistent LGE-based scar segmentation. As ECGs and LGE-MRIs are not acquired simultaneously, we introduce a Temporal Aware Feature Fusion (TAFF) mechanism that dynamically weights and fuses features based on their acquisition time difference. Our method was evaluated on a clinical dataset and achieved substantial gains over the state-of-the-art image-only baseline (nnU-Net), increasing the average Dice score for scars from 0.6149 to 0.8463 and achieving high performance in both precision (0.9115) and sensitivity (0.9043). These results show that integrating physiological and anatomical knowledge allows the model to "see beyond the image", setting a new direction for robust and physiologically grounded cardiac scar segmentation.
ORCA: Agentic Reasoning For Hallucination and Adversarial Robustness in Vision-Language Models
Sep 18, 2025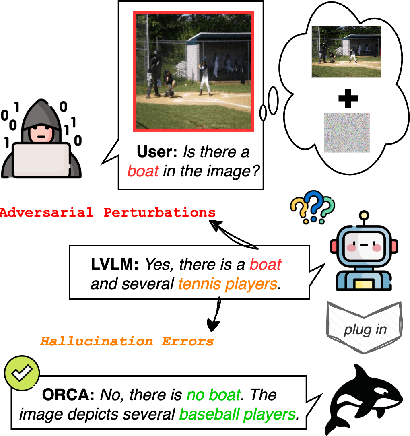



Large Vision-Language Models (LVLMs) exhibit strong multimodal capabilities but remain vulnerable to hallucinations from intrinsic errors and adversarial attacks from external exploitations, limiting their reliability in real-world applications. We present ORCA, an agentic reasoning framework that improves the factual accuracy and adversarial robustness of pretrained LVLMs through test-time structured inference reasoning with a suite of small vision models (less than 3B parameters). ORCA operates via an Observe--Reason--Critique--Act loop, querying multiple visual tools with evidential questions, validating cross-model inconsistencies, and refining predictions iteratively without access to model internals or retraining. ORCA also stores intermediate reasoning traces, which supports auditable decision-making. Though designed primarily to mitigate object-level hallucinations, ORCA also exhibits emergent adversarial robustness without requiring adversarial training or defense mechanisms. We evaluate ORCA across three settings: (1) clean images on hallucination benchmarks, (2) adversarially perturbed images without defense, and (3) adversarially perturbed images with defense applied. On the POPE hallucination benchmark, ORCA improves standalone LVLM performance by +3.64\% to +40.67\% across different subsets. Under adversarial perturbations on POPE, ORCA achieves an average accuracy gain of +20.11\% across LVLMs. When combined with defense techniques on adversarially perturbed AMBER images, ORCA further improves standalone LVLM performance, with gains ranging from +1.20\% to +48.00\% across evaluation metrics. These results demonstrate that ORCA offers a promising path toward building more reliable and robust multimodal systems.
CLAIM: Clinically-Guided LGE Augmentation for Realistic and Diverse Myocardial Scar Synthesis and Segmentation
Jun 18, 2025Deep learning-based myocardial scar segmentation from late gadolinium enhancement (LGE) cardiac MRI has shown great potential for accurate and timely diagnosis and treatment planning for structural cardiac diseases. However, the limited availability and variability of LGE images with high-quality scar labels restrict the development of robust segmentation models. To address this, we introduce CLAIM: \textbf{C}linically-Guided \textbf{L}GE \textbf{A}ugmentation for Real\textbf{i}stic and Diverse \textbf{M}yocardial Scar Synthesis and Segmentation framework, a framework for anatomically grounded scar generation and segmentation. At its core is the SMILE module (Scar Mask generation guided by cLinical knowledgE), which conditions a diffusion-based generator on the clinically adopted AHA 17-segment model to synthesize images with anatomically consistent and spatially diverse scar patterns. In addition, CLAIM employs a joint training strategy in which the scar segmentation network is optimized alongside the generator, aiming to enhance both the realism of synthesized scars and the accuracy of the scar segmentation performance. Experimental results show that CLAIM produces anatomically coherent scar patterns and achieves higher Dice similarity with real scar distributions compared to baseline models. Our approach enables controllable and realistic myocardial scar synthesis and has demonstrated utility for downstream medical imaging task.
PASS: Private Attributes Protection with Stochastic Data Substitution
Jun 08, 2025The growing Machine Learning (ML) services require extensive collections of user data, which may inadvertently include people's private information irrelevant to the services. Various studies have been proposed to protect private attributes by removing them from the data while maintaining the utilities of the data for downstream tasks. Nevertheless, as we theoretically and empirically show in the paper, these methods reveal severe vulnerability because of a common weakness rooted in their adversarial training based strategies. To overcome this limitation, we propose a novel approach, PASS, designed to stochastically substitute the original sample with another one according to certain probabilities, which is trained with a novel loss function soundly derived from information-theoretic objective defined for utility-preserving private attributes protection. The comprehensive evaluation of PASS on various datasets of different modalities, including facial images, human activity sensory signals, and voice recording datasets, substantiates PASS's effectiveness and generalizability.