 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Federated Learning to Space
Nov 18, 2025As Low Earth Orbit (LEO) satellite constellations rapidly expand to hundreds and thousands of spacecraft, the need for distributed on-board machine learning becomes critical to address downlink bandwidth limitations. Federated learning (FL) offers a promising framework to conduct collaborative model training across satellite networks. Realizing its benefits in space naturally requires addressing space-specific constraints, from intermittent connectivity to dynamics imposed by orbital motion. This work presents the first systematic feasibility analysis of adapting off-the-shelf FL algorithms for satellite constellation deployment. We introduce a comprehensive "space-ification" framework that adapts terrestrial algorithms (FedAvg, FedProx, FedBuff) to operate under orbital constraints, producing an orbital-ready suite of FL algorithms. We then evaluate these space-ified methods through extensive parameter sweeps across 768 constellation configurations that vary cluster sizes (1-10), satellites per cluster (1-10), and ground station networks (1-13). Our analysis demonstrates that space-adapted FL algorithms efficiently scale to constellations of up to 100 satellites, achieving performance close to the centralized ideal. Multi-month training cycles can be reduced to days, corresponding to a 9x speedup through orbital scheduling and local coordination within satellite clusters. These results provide actionable insights for future mission designers, enabling distributed on-board learning for more autonomous, resilient, and data-driven satellite operations.
Accelerating 3D Gaussian Splatting with Neural Sorting and Axis-Oriented Rasterization
Jun 08, 2025



3D Gaussian Splatting (3DGS) has recently gained significant attention for high-quality and efficient view synthesis, making it widely adopted in fields such as AR/VR, robotics, and autonomous driving. Despite its impressive algorithmic performance, real-time rendering on resource-constrained devices remains a major challenge due to tight power and area budgets. This paper presents an architecture-algorithm co-design to address these inefficiencies. First, we reveal substantial redundancy caused by repeated computation of common terms/expressions during the conventional rasterization. To resolve this, we propose axis-oriented rasterization, which pre-computes and reuses shared terms along both the X and Y axes through a dedicated hardware design, effectively reducing multiply-and-add (MAC) operations by up to 63%. Second, by identifying the resource and performance inefficiency of the sorting process, we introduce a novel neural sorting approach that predicts order-independent blending weights using an efficient neural network, eliminating the need for costly hardware sorters. A dedicated training framework is also proposed to improve its algorithmic stability. Third, to uniformly support rasterization and neural network inference, we design an efficient reconfigurable processing array that maximizes hardware utilization and throughput. Furthermore, we introduce a $\pi$-trajectory tile schedule, inspired by Morton encoding and Hilbert curve, to optimize Gaussian reuse and reduce memory access overhead. Comprehensive experiments demonstrate that the proposed design preserves rendering quality while achieving a speedup of $23.4\sim27.8\times$ and energy savings of $28.8\sim51.4\times$ compared to edge GPUs for real-world scenes. We plan to open-source our design to foster further development in this field.
Exploring Code Language Models for Automated HLS-based Hardware Generation: Benchmark, Infrastructure and Analysis
Feb 19, 2025Recent advances in code generation have illuminated the potential of employing large language models (LLMs) for general-purpose programming languages such as Python and C++, opening new opportunities for automating software development and enhancing programmer productivity. The potential of LLMs in software programming has sparked significant interest in exploring automated hardware generation and automation. Although preliminary endeavors have been made to adopt LLMs in generating hardware description languages (HDLs), several challenges persist in this direction. First, the volume of available HDL training data is substantially smaller compared to that for software programming languages. Second, the pre-trained LLMs, mainly tailored for software code, tend to produce HDL designs that are more error-prone. Third, the generation of HDL requires a significantly higher number of tokens compared to software programming, leading to inefficiencies in cost and energy consumption. To tackle these challenges, this paper explores leveraging LLMs to generate High-Level Synthesis (HLS)-based hardware design. Although code generation for domain-specific programming languages is not new in the literature, we aim to provide experimental results, insights, benchmarks, and evaluation infrastructure to investigate the suitability of HLS over low-level HDLs for LLM-assisted hardware design generation. To achieve this, we first finetune pre-trained models for HLS-based hardware generation, using a collected dataset with text prompts and corresponding reference HLS designs. An LLM-assisted framework is then proposed to automate end-to-end hardware code generation, which also investigates the impact of chain-of-thought and feedback loops promoting techniques on HLS-design generation. Limited by the timeframe of this research, we plan to evaluate more advanced reasoning models in the future.
Space for Improvement: Navigating the Design Space for Federated Learning in Satellite Constellations
Oct 31, 2024Space has emerged as an exciting new application area for machine learning, with several missions equipping deep learning capabilities on-board spacecraft. Pre-processing satellite data through on-board training is necessary to address the satellite downlink deficit, as not enough transmission opportunities are available to match the high rates of data generation. To scale this effort across entire constellations, collaborated training in orbit has been enabled through federated learning (FL). While current explorations of FL in this context have successfully adapted FL algorithms for scenario-specific constraints, these theoretical FL implementations face several limitations that prevent progress towards real-world deployment. To address this gap, we provide a holistic exploration of the FL in space domain on several fronts. 1) We develop a method for space-ification of existing FL algorithms, evaluated on 2) FLySTacK, our novel satellite constellation design and hardware aware testing platform where we perform rigorous algorithm evaluations. Finally we introduce 3) AutoFLSat, a generalized, hierarchical, autonomous FL algorithm for space that provides a 12.5% to 37.5% reduction in model training time than leading alternatives.
Federated Self-supervised Learning for Video Understanding
Jul 05, 2022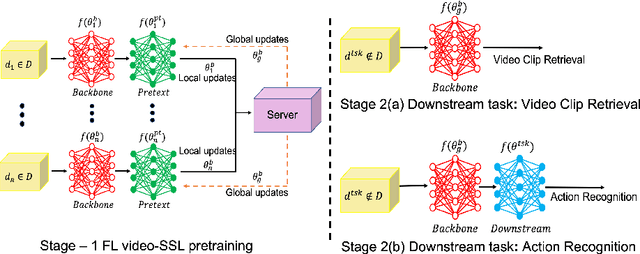
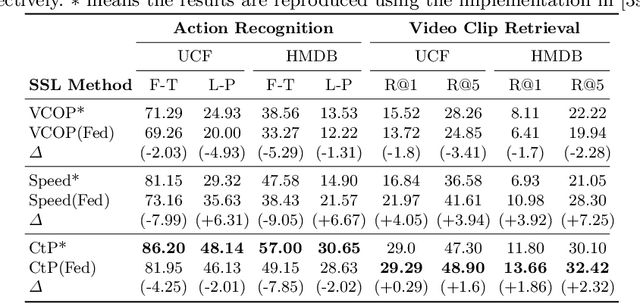
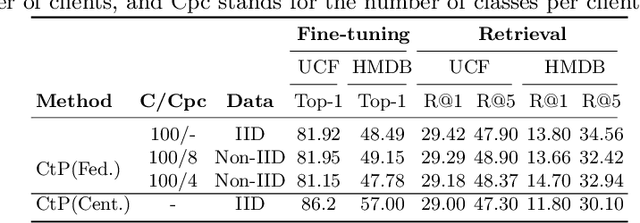
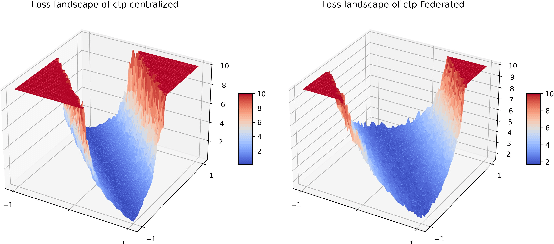
The ubiquity of camera-enabled mobile devices has lead to large amounts of unlabelled video data being produced at the edge. Although various self-supervised learning (SSL) methods have been proposed to harvest their latent spatio-temporal representations for task-specific training, practical challenges including privacy concerns and communication costs prevent SSL from being deployed at large scales. To mitigate these issues, we propose the use of Federated Learning (FL) to the task of video SSL. In this work, we evaluate the performance of current state-of-the-art (SOTA) video-SSL techniques and identify their shortcomings when integrated into the large-scale FL setting simulated with kinetics-400 dataset. We follow by proposing a novel federated SSL framework for video, dubbed FedVSSL, that integrates different aggregation strategies and partial weight updating. Extensive experiments demonstrate the effectiveness and significance of FedVSSL as it outperforms the centralized SOTA for the downstream retrieval task by 6.66% on UCF-101 and 5.13% on HMDB-51.
FRuDA: Framework for Distributed Adversarial Domain Adaptation
Dec 26, 2021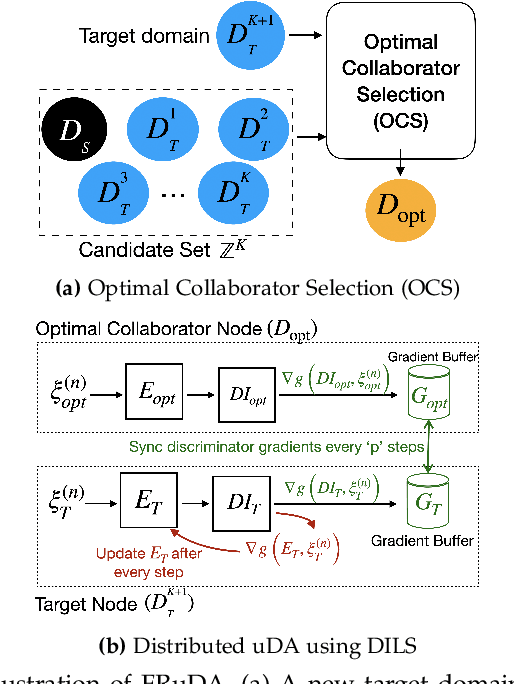
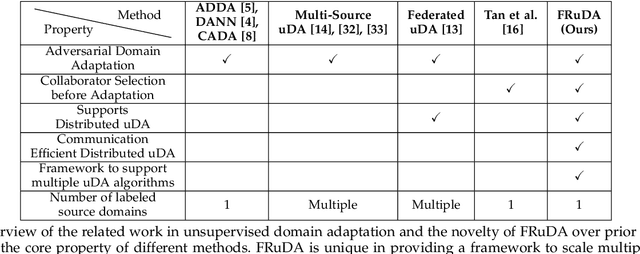
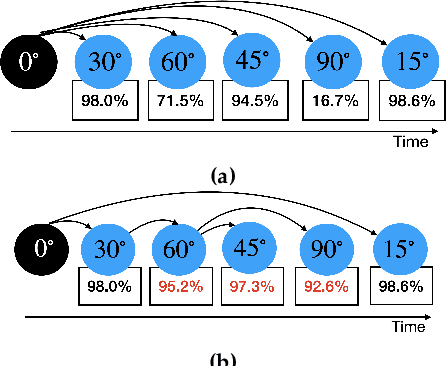

Breakthroughs in unsupervised domain adaptation (uDA) can help in adapting models from a label-rich source domain to unlabeled target domains. Despite these advancements, there is a lack of research on how uDA algorithms, particularly those based on adversarial learning, can work in distributed settings. In real-world applications, target domains are often distributed across thousands of devices, and existing adversarial uDA algorithms -- which are centralized in nature -- cannot be applied in these settings. To solve this important problem, we introduce FRuDA: an end-to-end framework for distributed adversarial uDA. Through a careful analysis of the uDA literature, we identify the design goals for a distributed uDA system and propose two novel algorithms to increase adaptation accuracy and training efficiency of adversarial uDA in distributed settings. Our evaluation of FRuDA with five image and speech datasets show that it can boost target domain accuracy by up to 50% and improve the training efficiency of adversarial uDA by at least 11 times.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021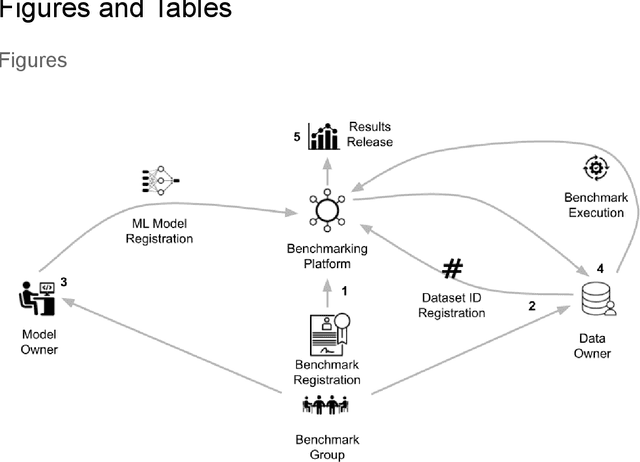
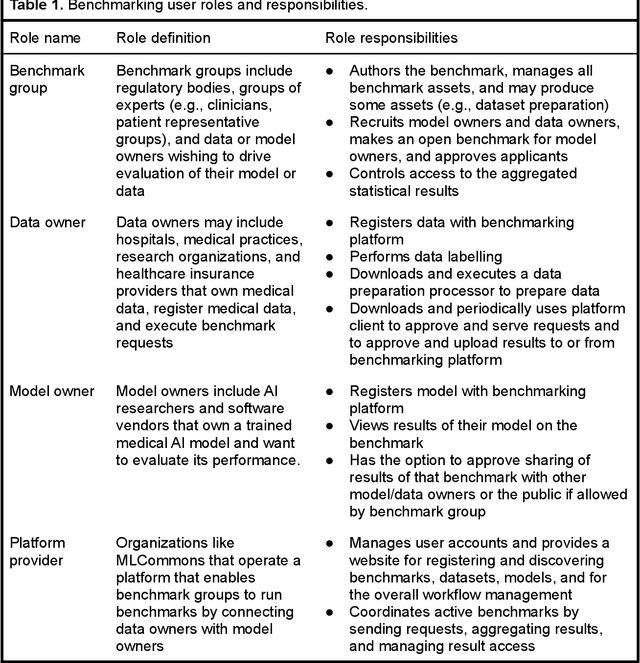
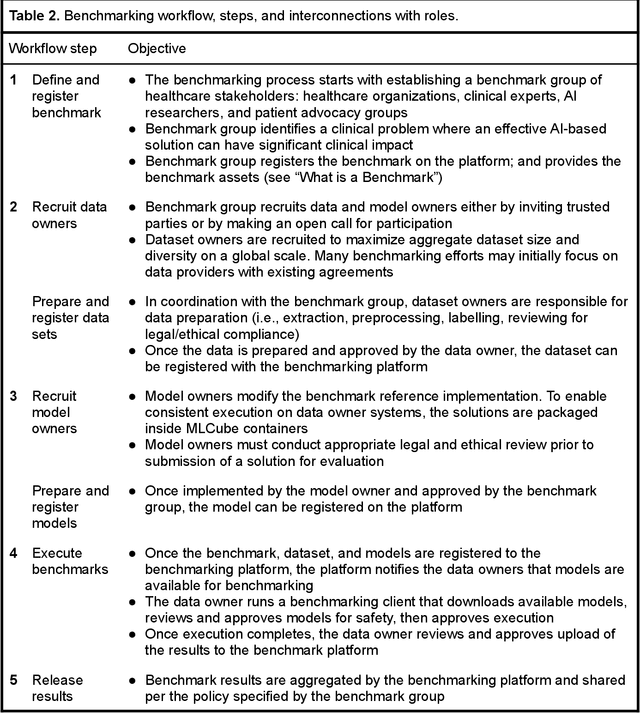
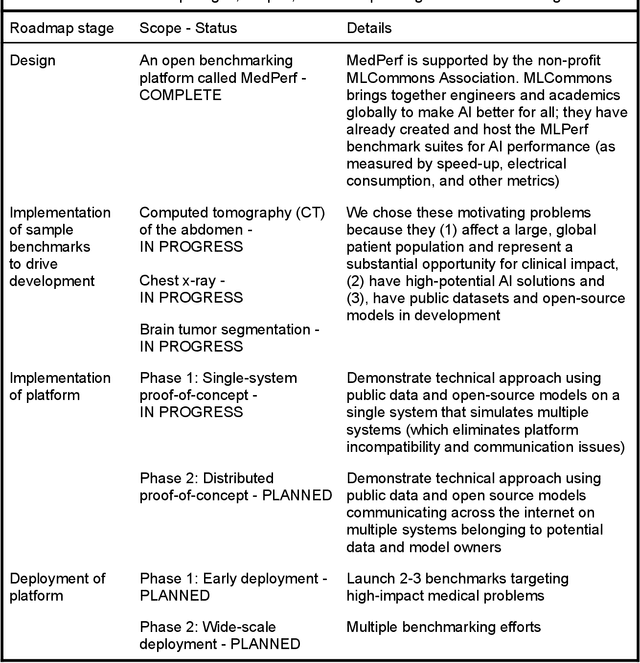
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
A Channel Coding Benchmark for Meta-Learning
Jul 15, 2021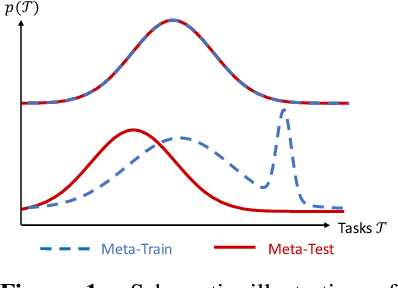


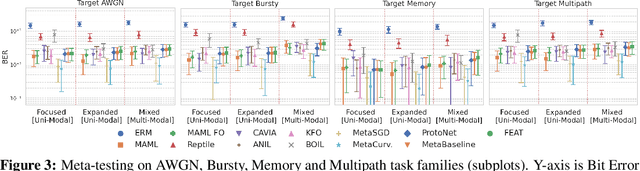
Meta-learning provides a popular and effective family of methods for data-efficient learning of new tasks. However, several important issues in meta-learning have proven hard to study thus far. For example, performance degrades in real-world settings where meta-learners must learn from a wide and potentially multi-modal distribution of training tasks; and when distribution shift exists between meta-train and meta-test task distributions. These issues are typically hard to study since the shape of task distributions, and shift between them are not straightforward to measure or control in standard benchmarks. We propose the channel coding problem as a benchmark for meta-learning. Channel coding is an important practical application where task distributions naturally arise, and fast adaptation to new tasks is practically valuable. We use this benchmark to study several aspects of meta-learning, including the impact of task distribution breadth and shift, which can be controlled in the coding problem. Going forward, this benchmark provides a tool for the community to study the capabilities and limitations of meta-learning, and to drive research on practically robust and effective meta-learners.
Predicting Patient Outcomes with Graph Representation Learning
Jan 11, 2021
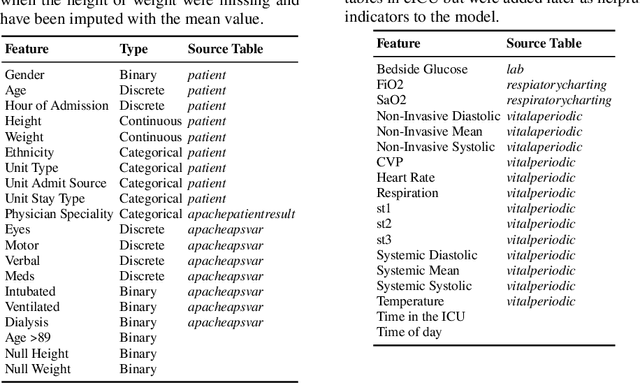


Recent work on predicting patient outcomes in the Intensive Care Unit (ICU) has focused heavily on the physiological time series data, largely ignoring sparse data such as diagnoses and medications. When they are included, they are usually concatenated in the late stages of a model, which may struggle to learn from rarer disease patterns. Instead, we propose a strategy to exploit diagnoses as relational information by connecting similar patients in a graph. To this end, we propose LSTM-GNN for patient outcome prediction tasks: a hybrid model combining Long Short-Term Memory networks (LSTMs) for extracting temporal features and Graph Neural Networks (GNNs) for extracting the patient neighbourhood information. We demonstrate that LSTM-GNNs outperform the LSTM-only baseline on length of stay prediction tasks on the eICU database. More generally, our results indicate that exploiting information from neighbouring patient cases using graph neural networks is a promising research direction, yielding tangible returns in supervised learning performance on Electronic Health Records.
Single Shot Structured Pruning Before Training
Jul 01, 2020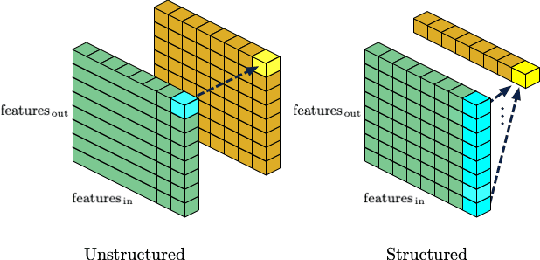
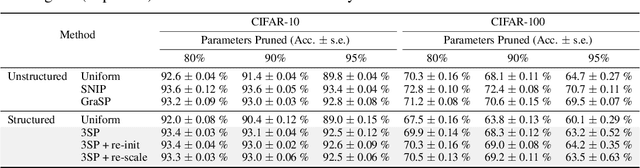
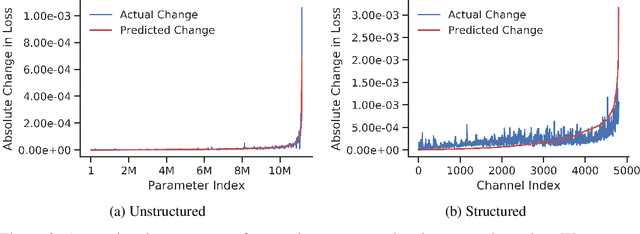

We introduce a method to speed up training by 2x and inference by 3x in deep neural networks using structured pruning applied before training. Unlike previous works on pruning before training which prune individual weights, our work develops a methodology to remove entire channels and hidden units with the explicit aim of speeding up training and inference. We introduce a compute-aware scoring mechanism which enables pruning in units of sensitivity per FLOP removed, allowing even greater speed ups. Our method is fast, easy to implement, and needs just one forward/backward pass on a single batch of data to complete pruning before training begins.