 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRuDA: Framework for Distributed Adversarial Domain Adaptation
Dec 26, 2021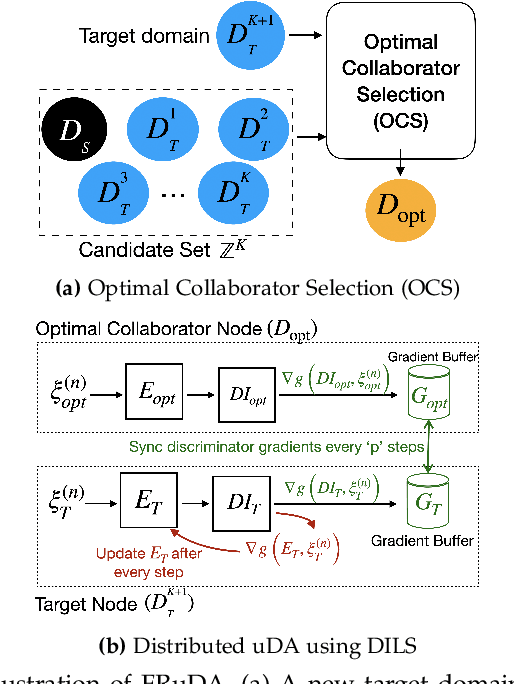
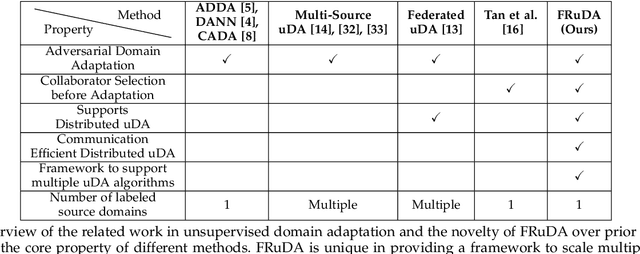
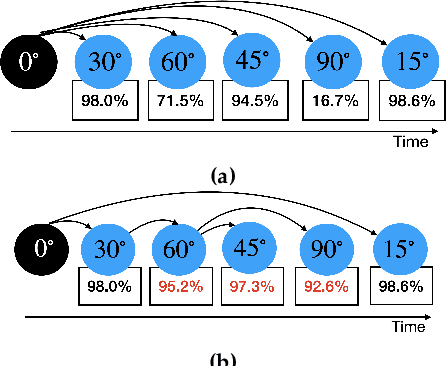

Breakthroughs in unsupervised domain adaptation (uDA) can help in adapting models from a label-rich source domain to unlabeled target domains. Despite these advancements, there is a lack of research on how uDA algorithms, particularly those based on adversarial learning, can work in distributed settings. In real-world applications, target domains are often distributed across thousands of devices, and existing adversarial uDA algorithms -- which are centralized in nature -- cannot be applied in these settings. To solve this important problem, we introduce FRuDA: an end-to-end framework for distributed adversarial uDA. Through a careful analysis of the uDA literature, we identify the design goals for a distributed uDA system and propose two novel algorithms to increase adaptation accuracy and training efficiency of adversarial uDA in distributed settings. Our evaluation of FRuDA with five image and speech datasets show that it can boost target domain accuracy by up to 50% and improve the training efficiency of adversarial uDA by at least 11 times.
Libri-Adapt: A New Speech Dataset for Unsupervised Domain Adaptation
Sep 06, 2020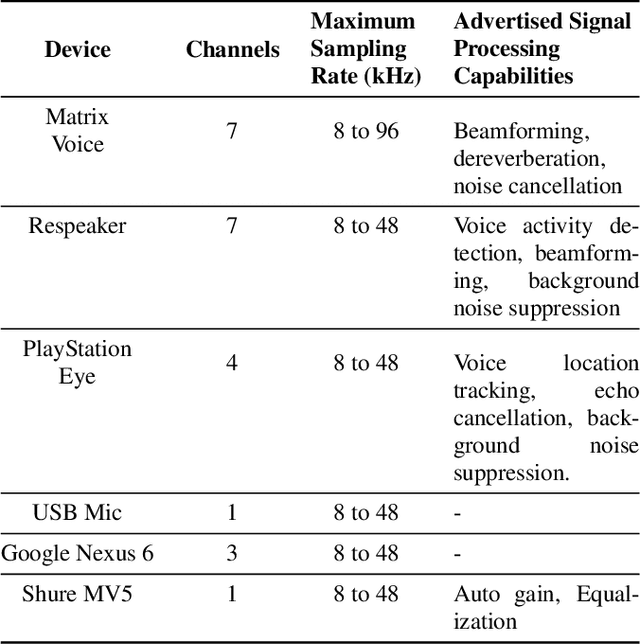
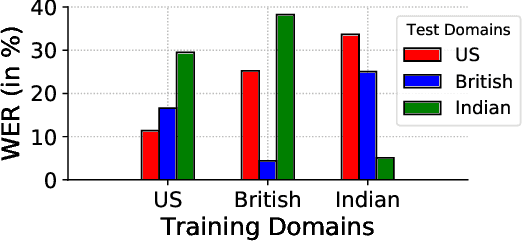
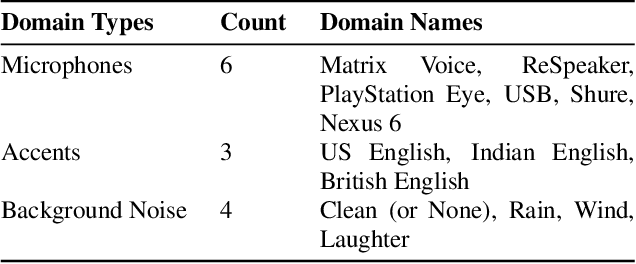
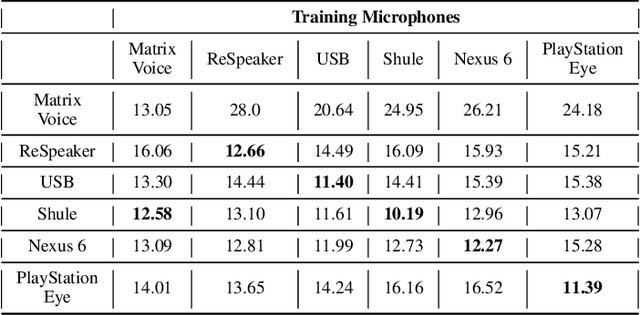
This paper introduces a new dataset, Libri-Adapt, to support unsupervised domain adaptation research on speech recognition models. Built on top of the LibriSpeech corpus, Libri-Adapt contains English speech recorded on mobile and embedded-scale microphones, and spans 72 different domains that are representative of the challenging practical scenarios encountered by ASR models. More specifically, Libri-Adapt facilitates the study of domain shifts in ASR models caused by a) different acoustic environments, b) variations in speaker accents, c) heterogeneity in the hardware and platform software of the microphones, and d) a combination of the aforementioned three shifts. We also provide a number of baseline results quantifying the impact of these domain shifts on the Mozilla DeepSpeech2 ASR model.
* 5 pages, Published at IEEE ICASSP 2020
Mic2Mic: Using Cycle-Consistent Generative Adversarial Networks to Overcome Microphone Variability in Speech Systems
Mar 27, 2020
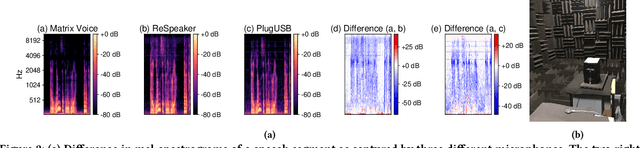
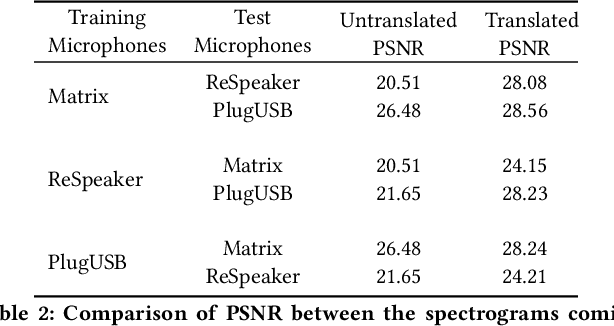
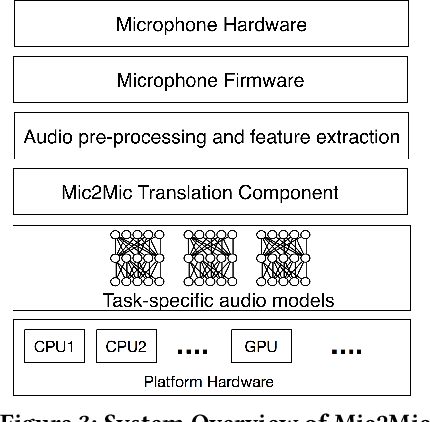
Mobile and embedded devices are increasingly using microphones and audio-based computational models to infer user context. A major challenge in building systems that combine audio models with commodity microphones is to guarantee their accuracy and robustness in the real-world. Besides many environmental dynamics, a primary factor that impacts the robustness of audio models is microphone variability. In this work, we propose Mic2Mic -- a machine-learned system component -- which resides in the inference pipeline of audio models and at real-time reduces the variability in audio data caused by microphone-specific factors. Two key considerations for the design of Mic2Mic were: a) to decouple the problem of microphone variability from the audio task, and b) put a minimal burden on end-users to provide training data. With these in mind, we apply the principles of cycle-consistent generative adversarial networks (CycleGANs) to learn Mic2Mic using unlabeled and unpaired data collected from different microphones. Our experiments show that Mic2Mic can recover between 66% to 89% of the accuracy lost due to microphone variability for two common audio tasks.
EMOPAIN Challenge 2020: Multimodal Pain Evaluation from Facial and Bodily Expressions
Jan 25, 2020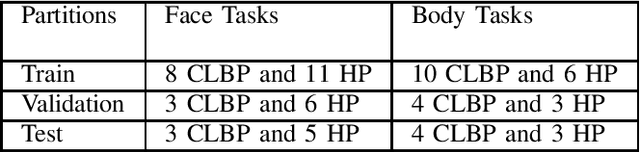
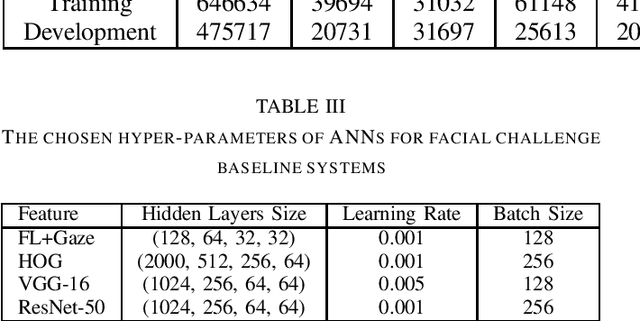
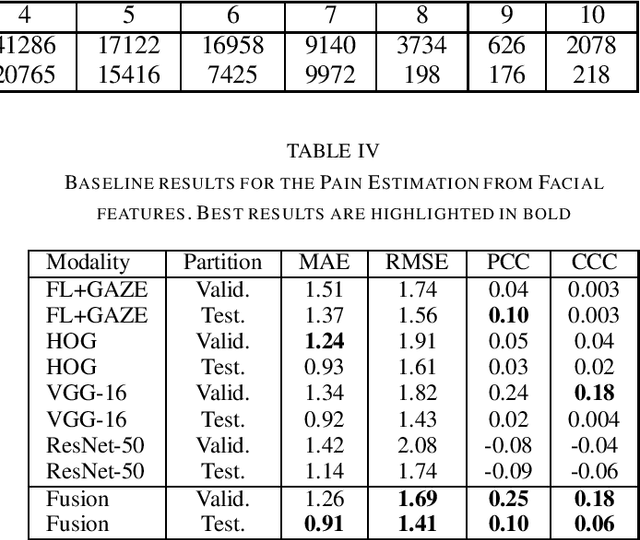
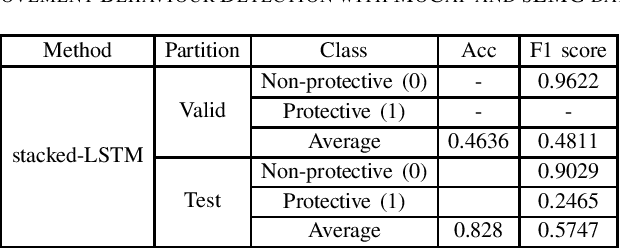
The EmoPain 2020 Challenge is the first international competition aimed at creating a uniform platform for the comparison of machine learning and multimedia processing methods of automatic chronic pain assessment from human expressive behaviour, and also the identification of pain-related behaviours. The objective of the challenge is to promote research in the development of assistive technologies that help improve the quality of life for people with chronic pain via real-time monitoring and feedback to help manage their condition and remain physically active. The challenge also aims to encourage the use of the relatively underutilised, albeit vital bodily expression signals for automatic pain and pain-related emotion recognition. This paper presents a description of the challenge, competition guidelines, bench-marking dataset, and the baseline systems' architecture and performance on the three sub-tasks: pain estimation from facial expressions, pain recognition from multimodal movement, and protective movement behaviour detection.