 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do We Research Human-Robot Interaction in the Age of Large Language Models? A Systematic Review
Feb 13, 2026Advances in large language models (LLMs) are profoundly reshaping the field of human-robot interaction (HRI). While prior work has highlighted the technical potential of LLMs, few studies have systematically examined their human-centered impact (e.g., human-oriented understanding, user modeling, and levels of autonomy), making it difficult to consolidate emerging challenges in LLM-driven HRI systems. Therefore, we conducted a systematic literature search following the PRISMA guideline, identifying 86 articles that met our inclusion criteria. Our findings reveal that: (1) LLMs are transforming the fundamentals of HRI by reshaping how robots sense context, generate socially grounded interactions, and maintain continuous alignment with human needs in embodied settings; and (2) current research is largely exploratory, with different studies focusing on different facets of LLM-driven HRI, resulting in wide-ranging choices of experimental setups, study methods, and evaluation metrics. Finally, we identify key design considerations and challenges, offering a coherent overview and guidelines for future research at the intersection of LLMs and HRI.
Efficient End-to-End Video Question Answering with Pyramidal Multimodal Transformer
Feb 04, 2023This paper presents a new method for end-to-end Video Question Answering (VideoQA), aside from the current popularity of using large-scale pre-training with huge feature extractors. We achieve this with a pyramidal multimodal transformer (PMT) model, which simply incorporates a learnable word embedding layer, a few convolutional and transformer layers. We use the anisotropic pyramid to fulfill video-language interactions across different spatio-temporal scales. In addition to the canonical pyramid, which includes both bottom-up and top-down pathways with lateral connections, novel strategies are proposed to decompose the visual feature stream into spatial and temporal sub-streams at different scales and implement their interactions with the linguistic semantics while preserving the integrity of local and global semantics. We demonstrate better or on-par performances with high computational efficiency against state-of-the-art methods on five VideoQA benchmarks. Our ablation study shows the scalability of our model that achieves competitive results for text-to-video retrieval by leveraging feature extractors with reusable pre-trained weights, and also the effectiveness of the pyramid.
Multilevel Hierarchical Network with Multiscale Sampling for Video Question Answering
May 09, 2022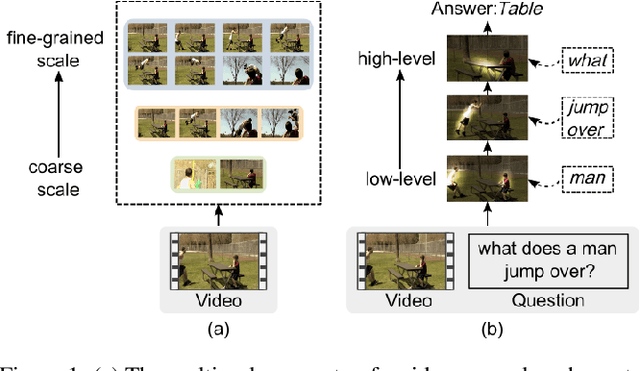
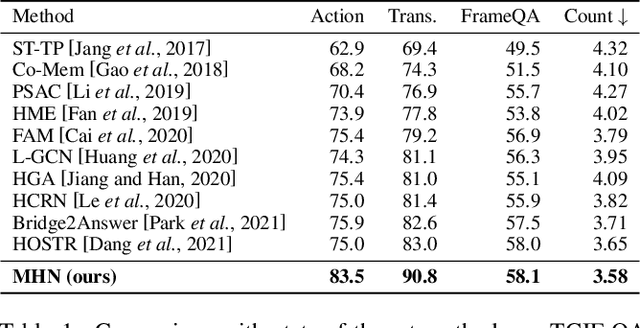
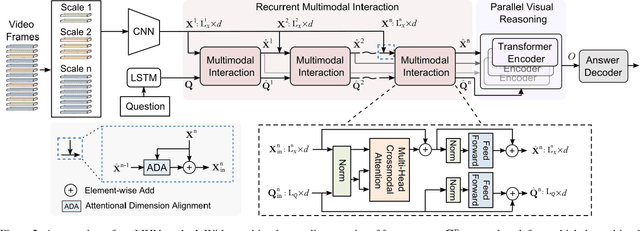
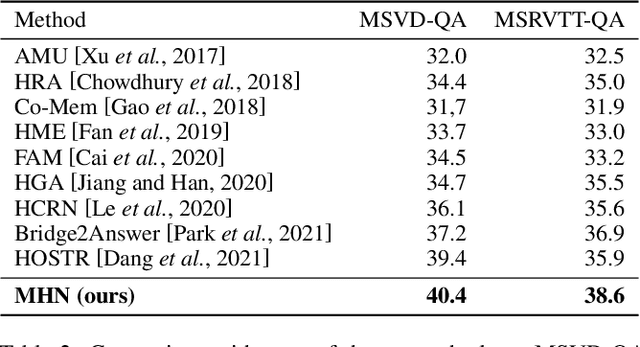
Video question answering (VideoQA) is challenging given its multimodal combination of visual understanding and natural language processing. While most existing approaches ignore the visual appearance-motion information at different temporal scales, it is unknown how to incorporate the multilevel processing capacity of a deep learning model with such multiscale information. Targeting these issues, this paper proposes a novel Multilevel Hierarchical Network (MHN) with multiscale sampling for VideoQA. MHN comprises two modules, namely Recurrent Multimodal Interaction (RMI) and Parallel Visual Reasoning (PVR). With a multiscale sampling, RMI iterates the interaction of appearance-motion information at each scale and the question embeddings to build the multilevel question-guided visual representations. Thereon, with a shared transformer encoder, PVR infers the visual cues at each level in parallel to fit with answering different question types that may rely on the visual information at relevant levels. Through extensive experiments on three VideoQA datasets, we demonstrate improved performances than previous state-of-the-arts and justify the effectiveness of each part of our method.
Temporal Pyramid Transformer with Multimodal Interaction for Video Question Answering
Sep 10, 2021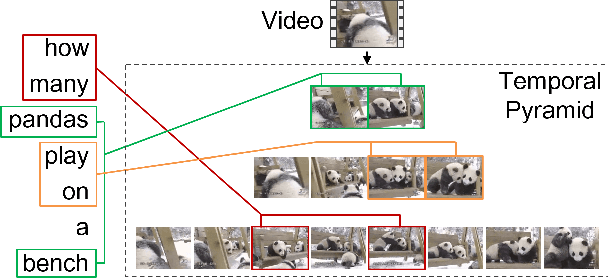
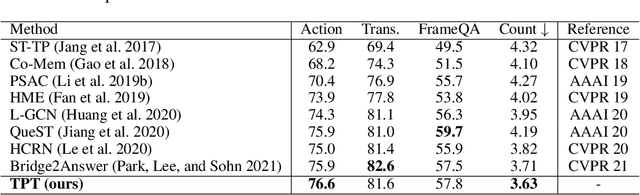
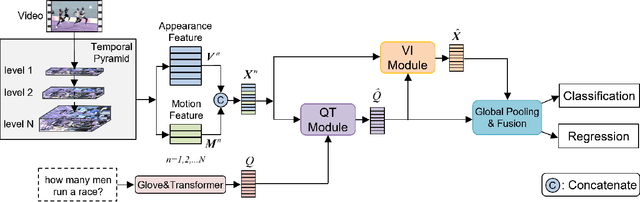
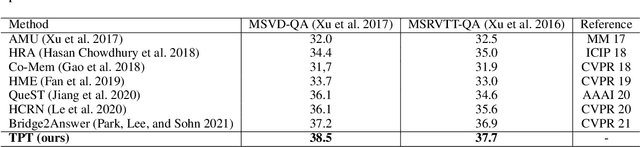
Video question answering (VideoQA) is challenging given its multimodal combination of visual understanding and natural language understanding. While existing approaches seldom leverage the appearance-motion information in the video at multiple temporal scales, the interaction between the question and the visual information for textual semantics extraction is frequently ignored. Targeting these issues, this paper proposes a novel Temporal Pyramid Transformer (TPT) model with multimodal interaction for VideoQA. The TPT model comprises two modules, namely Question-specific Transformer (QT) and Visual Inference (VI). Given the temporal pyramid constructed from a video, QT builds the question semantics from the coarse-to-fine multimodal co-occurrence between each word and the visual content. Under the guidance of such question-specific semantics, VI infers the visual clues from the local-to-global multi-level interactions between the question and the video. Within each module, we introduce a multimodal attention mechanism to aid the extraction of question-video interactions, with residual connections adopted for the information passing across different levels. Through extensive experiments on three VideoQA datasets, we demonstrate better performances of the proposed method in comparison with the state-of-the-arts.
AgreementLearning: An End-to-End Framework for Learning with Multiple Annotators without Groundtruth
Sep 08, 2021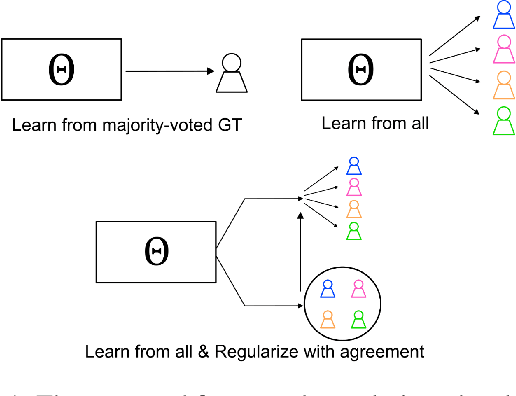
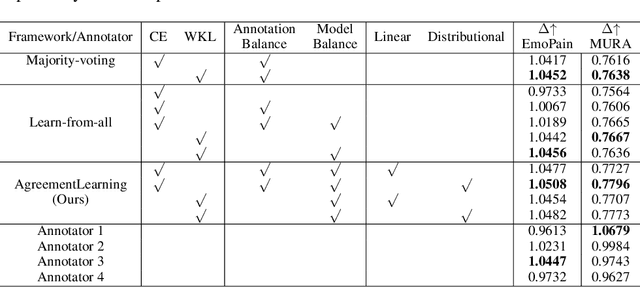
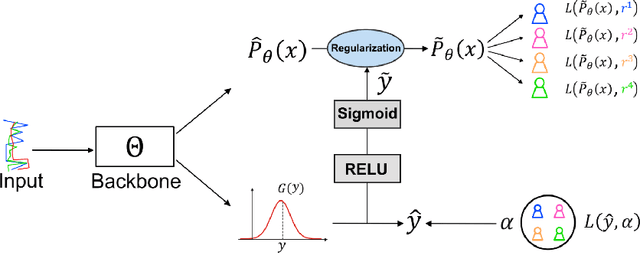
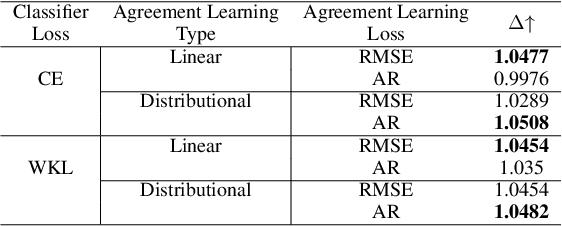
The annotation of domain experts is important for some medical applications where the objective groundtruth is ambiguous to define, e.g., the rehabilitation for some chronic diseases, and the prescreening of some musculoskeletal abnormalities without further medical examinations. However, improper uses of the annotations may hinder developing reliable models. On one hand, forcing the use of a single groundtruth generated from multiple annotations is less informative for the modeling. On the other hand, feeding the model with all the annotations without proper regularization is noisy given existing disagreements. For such issues, we propose a novel agreement learning framework to tackle the challenge of learning from multiple annotators without objective groundtruth. The framework has two streams, with one stream fitting with the multiple annotators and the other stream learning agreement information between the annotators. In particular, the agreement learning stream produces regularization information to the classifier stream, tuning its decision to be better in line with the agreement between the annotators. The proposed method can be easily plugged to existing backbones developed with majority-voted groundtruth or multiple annotations. Thereon, experiments on two medical datasets demonstrate improved agreement levels with annotators.
Leveraging Activity Recognition to Enable Protective Behavior Detection in Continuous Data
Nov 16, 2020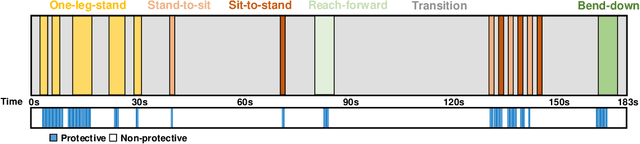
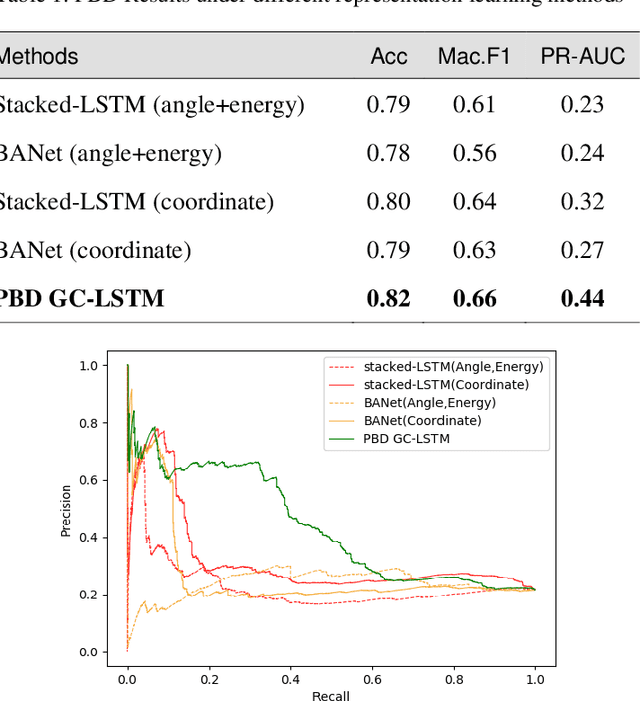
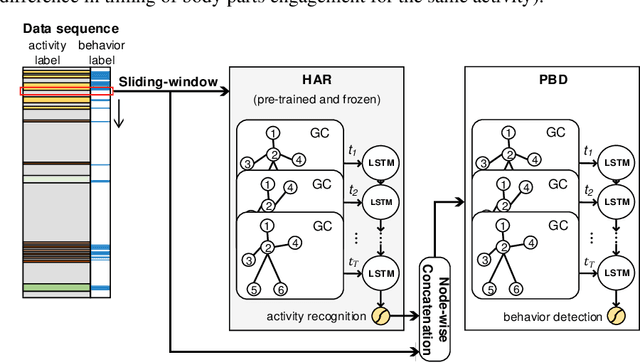
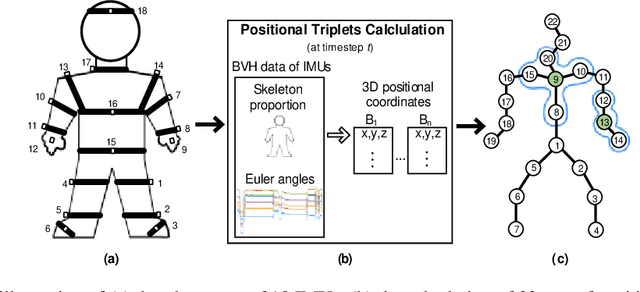
Protective behavior exhibited by people with chronic pain (CP) during physical activities is the key to understanding their physical and emotional states. Existing automatic protective behavior detection (PBD) methods depend on pre-segmentation of activity instances as they expect situations where activity types are predefined. However, during everyday management, people pass from one activity to another, and support should be delivered continuously and personalized to the activity type and presence of protective behavior. Hence, to facilitate ubiquitous CP management, it becomes critical to enable accurate PBD over continuous data. In this paper, we propose to integrate automatic human activity recognition (HAR) with PBD via a novel hierarchical HAR-PBD architecture comprising GC-LSTM networks, and alleviate the class imbalances therein using a CFCC loss function. Through in-depth evaluation of the approach using a CP patients' dataset, we show that the leveraging of HAR, GC-LSTM networks and the CFCC loss function leads to clear increase in PBD performance against the state-of-the-art (macro F1 score of 0.81 vs. 0.66 and PR-AUC of 0.60 vs. 0.44). We conclude by discussing possible use cases of the HAR-PBD architecture in the context of CP management and other situations. We also discuss the current limitations and ways forward.
Recognizing Micro-expression in Video Clip with Adaptive Key-frame Mining
Sep 19, 2020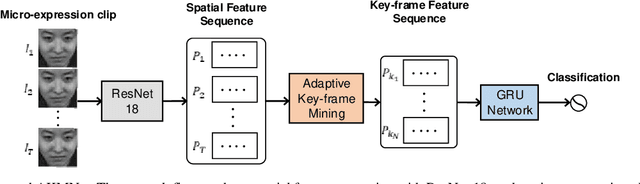
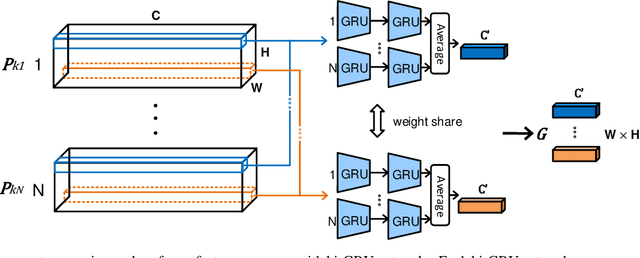
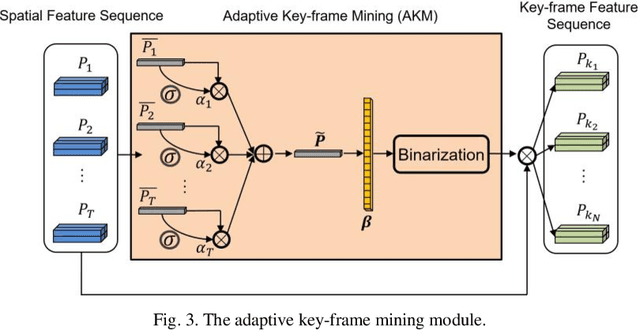
As a spontaneous expression of emotion on face, micro-expression is receiving increasing focus. Whist better recognition accuracy is achieved by various deep learning (DL) techniques, one characteristic of micro-expression has been not fully leveraged. That is, such facial movement is transient and sparsely localized through time. Therefore, the representation learned from a long video clip is usually redundant. On the other hand, methods utilizing the single apex frame require manual annotations and sacrifice the temporal dynamic information. To simultaneously spot and recognize such fleeting facial movement, we propose a novel end-to-end deep learning architecture, referred to as Adaptive Key-frame Mining Network (AKMNet). Operating on the raw video clip of micro-expression, AKMNet is able to learn discriminative spatio-temporal representation by combining the spatial feature of self-exploited local key frames and their global-temporal dynamics. Empirical and theoretical evaluations show advantages of the proposed approach with improved performance comparing with other state-of-the-art methods.
EMOPAIN Challenge 2020: Multimodal Pain Evaluation from Facial and Bodily Expressions
Jan 25, 2020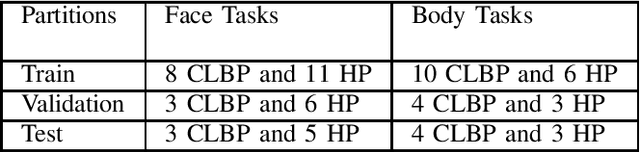
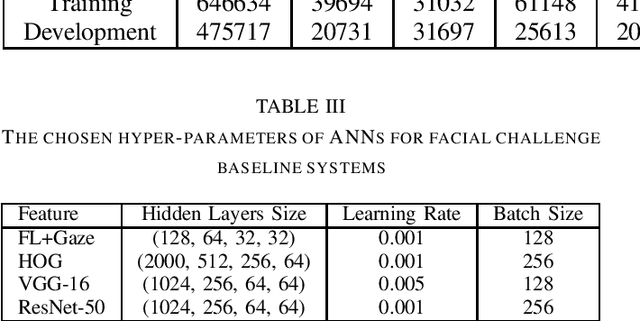
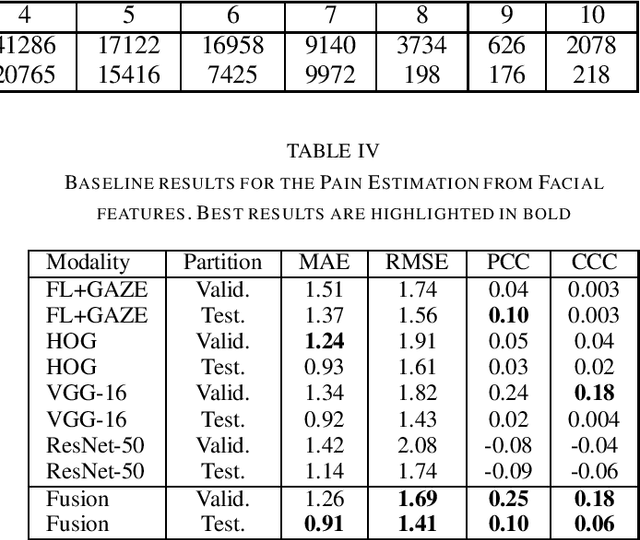
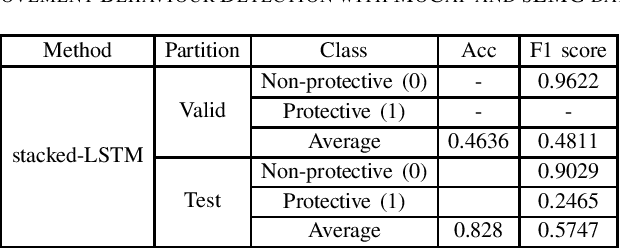
The EmoPain 2020 Challenge is the first international competition aimed at creating a uniform platform for the comparison of machine learning and multimedia processing methods of automatic chronic pain assessment from human expressive behaviour, and also the identification of pain-related behaviours. The objective of the challenge is to promote research in the development of assistive technologies that help improve the quality of life for people with chronic pain via real-time monitoring and feedback to help manage their condition and remain physically active. The challenge also aims to encourage the use of the relatively underutilised, albeit vital bodily expression signals for automatic pain and pain-related emotion recognition. This paper presents a description of the challenge, competition guidelines, bench-marking dataset, and the baseline systems' architecture and performance on the three sub-tasks: pain estimation from facial expressions, pain recognition from multimodal movement, and protective movement behaviour detection.
Learning Bodily and Temporal Attention in Protective Movement Behavior Detection
Apr 24, 2019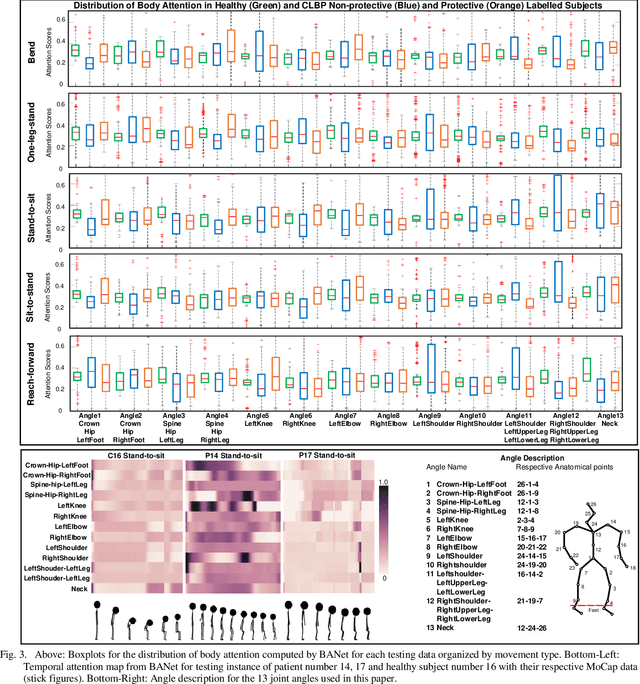
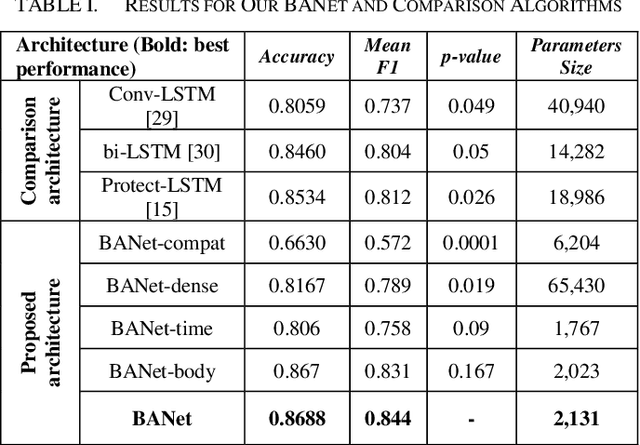
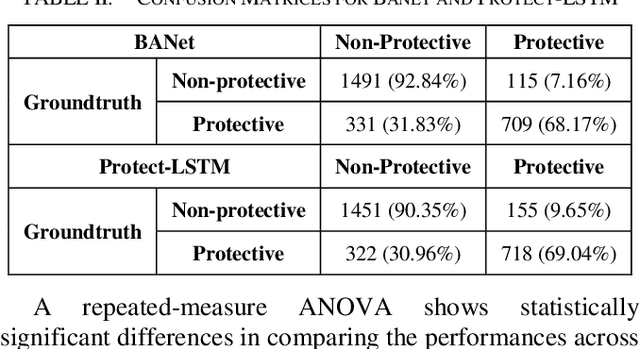
For people with chronic pain (CP), the assessment of protective behavior during physical functioning is essential to understand their subjective pain-related experiences (e.g., fear and anxiety toward pain and injury) and how they deal with such experiences (avoidance or reliance on specific body joints), with the ultimate goal of guiding intervention. Advances in deep learning (DL) can enable the development of such intervention. Using the EmoPain MoCap dataset, we investigate how attention-based DL architectures can be used to improve the detection of protective behavior by capturing the most informative biomechanical cues characterizing specific movements and the strategies used to execute them to cope with pain-related experience. We propose an end-to-end neural network architecture based on attention mechanism, named BodyAttentionNet (BANet). BANet is designed to learn temporal and body-joint regions that are informative to the detection of protective behavior. The approach can consider the variety of ways people execute one movement (including healthy people) and it is independent of the type of movement analyzed. We also explore variants of this architecture to understand the contribution of both temporal and bodily attention mechanisms. Through extensive experiments with other state-of-the-art machine learning techniques used with motion capture data, we show a statistically significant improvement achieved by combining the two attention mechanisms. In addition, the BANet architecture requires a much lower number of parameters than the state-of-the-art ones for comparable if not higher performances.
A Novel Apex-Time Network for Cross-Dataset Micro-Expression Recognition
Apr 23, 2019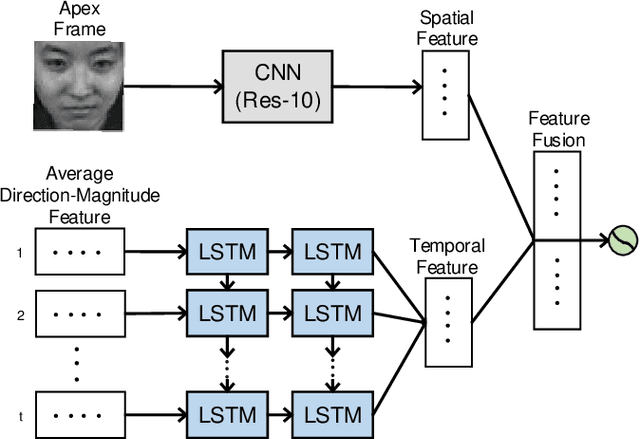
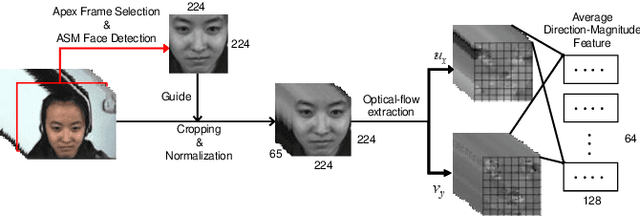
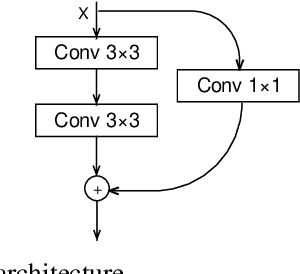
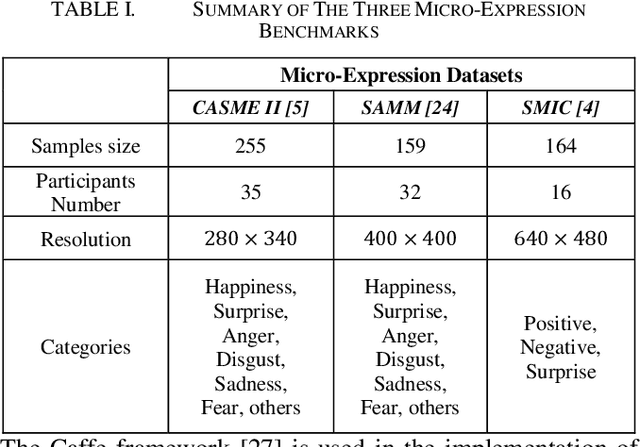
The automatic recognition of micro-expression has been boosted ever since the successful introduction of deep learning approaches. Whilst researchers working on such topics are more and more tending to learn from the nature of micro-expression, the practice of using deep learning techniques has evolved from processing the entire video clip of micro-expression to the recognition on apex frame. Using apex frame is able to get rid of redundant information but the temporal evidence of micro-expression would be thereby left out. In this paper, we propose to do the recognition based on the spatial information from apex frame as well as on the temporal information from respective-adjacent frames. As such, a novel Apex-Time Network (ATNet) is proposed. Through extensive experiments on three benchmarks, we demonstrate the improvement achieved by adding the temporal information learned from adjacent frames around the apex frame. Specially, the model with such temporal information is more robust in cross-dataset validations.