 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxPraBen: A Scalable Benchmark for Structured Evaluation of LLMs in Chinese Real-World Tax Practice
Apr 10, 2026While Large Language Models (LLMs) excel in various general domains, they exhibit notable gaps in the highly specialized, knowledge-intensive, and legally regulated Chinese tax domain. Consequently, while tax-related benchmarks are gaining attention, many focus on isolated NLP tasks, neglecting real-world practical capabilities. To address this issue, we introduce TaxPraBen, the first dedicated benchmark for Chinese taxation practice. It combines 10 traditional application tasks, along with 3 pioneering real-world scenarios: tax risk prevention, tax inspection analysis, and tax strategy planning, sourced from 14 datasets totaling 7.3K instances. TaxPraBen features a scalable structured evaluation paradigm designed through process of "structured parsing-field alignment extraction-numerical and textual matching", enabling end-to-end tax practice assessment while being extensible to other domains. We evaluate 19 LLMs based on Bloom's taxonomy. The results indicate significant performance disparities: all closed-source large-parameter LLMs excel, and Chinese LLMs like Qwen2.5 generally exceed multilingual LLMs, while the YaYi2 LLM, fine-tuned with some tax data, shows only limited improvement. TaxPraBen serves as a vital resource for advancing evaluations of LLMs in practical applications.
SiMing-Bench: Evaluating Procedural Correctness from Continuous Interactions in Clinical Skill Videos
Apr 10, 2026Current video benchmarks for multimodal large language models (MLLMs) focus on event recognition, temporal ordering, and long-context recall, but overlook a harder capability required for expert procedural judgment: tracking how ongoing interactions update the procedural state and thereby determine the correctness of later actions. We introduce SiMing-Bench, the first benchmark for evaluating this capability from full-length clinical skill videos. It targets rubric-grounded process-level judgment of whether interaction-driven state updates preserve procedural correctness across an entire workflow. SiMing-Bench is instantiated with SiMing-Score, a physician-annotated dataset of real clinical skill examination videos spanning cardiopulmonary resuscitation, automated external defibrillator operation, and bag-mask ventilation, each paired with a standardized step-wise rubric and dual-expert labels. Across diverse open- and closed-source MLLMs, we observe consistently weak agreement with physician judgments. Moreover, weak performance on rubric-defined intermediate steps persists even when overall procedure-level correlation appears acceptable, suggesting that coarse global assessment substantially overestimates current models' procedural judgment ability. Additional analyses with binary step judgment and step-aligned clips indicate that the bottleneck is not merely fine-grained scoring or temporal localization, but modeling how continuous interactions update procedural state over time.
Credibility Governance: A Social Mechanism for Collective Self-Correction under Weak Truth Signals
Mar 03, 2026Online platforms increasingly rely on opinion aggregation to allocate real-world attention and resources, yet common signals such as engagement votes or capital-weighted commitments are easy to amplify and often track visibility rather than reliability. This makes collective judgments brittle under weak truth signals, noisy or delayed feedback, early popularity surges, and strategic manipulation. We propose Credibility Governance (CG), a mechanism that reallocates influence by learning which agents and viewpoints consistently track evolving public evidence. CG maintains dynamic credibility scores for both agents and opinions, updates opinion influence via credibility-weighted endorsements, and updates agent credibility based on the long-run performance of the opinions they support, rewarding early and persistent alignment with emerging evidence while filtering short-lived noise. We evaluate CG in POLIS, a socio-physical simulation environment that models coupled belief dynamics and downstream feedback under uncertainty. Across settings with initial majority misalignment, observation noise and contamination, and misinformation shocks, CG outperforms vote-based, stake-weighted, and no-governance baselines, yielding faster recovery to the true state, reduced lock-in and path dependence, and improved robustness under adversarial pressure. Our implementation and experimental scripts are publicly available at https://github.com/Wanying-He/Credibility_Governance.
TKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning
Feb 05, 2026Temporal knowledge graph question answering (TKGQA) aims to answer time-sensitive questions by leveraging temporal knowledge bases. While Large Language Models (LLMs) demonstrate significant potential in TKGQA, current prompting strategies constrain their efficacy in two primary ways. First, they are prone to reasoning hallucinations under complex temporal constraints. Second, static prompting limits model autonomy and generalization, as it lack optimization through dynamic interaction with temporal knowledge graphs (TKGs) environments. To address these limitations, we propose \textbf{TKG-Thinker}, a novel agent equipped with autonomous planning and adaptive retrieval capabilities for reasoning over TKGs. Specifically, TKG-Thinker performs in-depth temporal reasoning through dynamic multi-turn interactions with TKGs via a dual-training strategy. We first apply Supervised Fine-Tuning (SFT) with chain-of thought data to instill core planning capabilities, followed by a Reinforcement Learning (RL) stage that leverages multi-dimensional rewards to refine reasoning policies under intricate temporal constraints. Experimental results on benchmark datasets with three open-source LLMs show that TKG-Thinker achieves state-of-the-art performance and exhibits strong generalization across complex TKGQA settings.
MisSpans: Fine-Grained False Span Identification in Cross-Domain Fake News
Jan 08, 2026Online misinformation is increasingly pervasive, yet most existing benchmarks and methods evaluate veracity at the level of whole claims or paragraphs using coarse binary labels, obscuring how true and false details often co-exist within single sentences. These simplifications also limit interpretability: global explanations cannot identify which specific segments are misleading or differentiate how a detail is false (e.g., distorted vs. fabricated). To address these gaps, we introduce MisSpans, the first multi-domain, human-annotated benchmark for span-level misinformation detection and analysis, consisting of paired real and fake news stories. MisSpans defines three complementary tasks: MisSpansIdentity for pinpointing false spans within sentences, MisSpansType for categorising false spans by misinformation type, and MisSpansExplanation for providing rationales grounded in identified spans. Together, these tasks enable fine-grained localisation, nuanced characterisation beyond true/false and actionable explanations. Expert annotators were guided by standardised guidelines and consistency checks, leading to high inter-annotator agreement. We evaluate 15 representative LLMs, including reasoning-enhanced and non-reasoning variants, under zero-shot and one-shot settings. Results reveal the challenging nature of fine-grained misinformation identification and analysis, and highlight the need for a deeper understanding of how performance may be influenced by multiple interacting factors, including model size and reasoning capabilities, along with domain-specific textual features. This project will be available at https://github.com/lzw108/MisSpans.
RAAR: Retrieval Augmented Agentic Reasoning for Cross-Domain Misinformation Detection
Jan 08, 2026Cross-domain misinformation detection is challenging, as misinformation arises across domains with substantial differences in knowledge and discourse. Existing methods often rely on single-perspective cues and struggle to generalize to challenging or underrepresented domains, while reasoning large language models (LLMs), though effective on complex tasks, are limited to same-distribution data. To address these gaps, we introduce RAAR, the first retrieval-augmented agentic reasoning framework for cross-domain misinformation detection. To enable cross-domain transfer beyond same-distribution assumptions, RAAR retrieves multi-perspective source-domain evidence aligned with each target sample's semantics, sentiment, and writing style. To overcome single-perspective modeling and missing systematic reasoning, RAAR constructs verifiable multi-step reasoning paths through specialized multi-agent collaboration, where perspective-specific agents produce complementary analyses and a summary agent integrates them under verifier guidance. RAAR further applies supervised fine-tuning and reinforcement learning to train a single multi-task verifier to enhance verification and reasoning capabilities. Based on RAAR, we trained the RAAR-8b and RAAR-14b models. Evaluation on three cross-domain misinformation detection tasks shows that RAAR substantially enhances the capabilities of the base models and outperforms other cross-domain methods, advanced LLMs, and LLM-based adaptation approaches. The project will be released at https://github.com/lzw108/RAAR.
MentraSuite: Post-Training Large Language Models for Mental Health Reasoning and Assessment
Dec 16, 2025Mental health disorders affect hundreds of millions globally, and the Web now serves as a primary medium for accessing support, information, and assessment. Large language models (LLMs) offer scalable and accessible assistance, yet their deployment in mental-health settings remains risky when their reasoning is incomplete, inconsistent, or ungrounded. Existing psychological LLMs emphasize emotional understanding or knowledge recall but overlook the step-wise, clinically aligned reasoning required for appraisal, diagnosis, intervention planning, abstraction, and verification. To address these issues, we introduce MentraSuite, a unified framework for advancing reliable mental-health reasoning. We propose MentraBench, a comprehensive benchmark spanning five core reasoning aspects, six tasks, and 13 datasets, evaluating both task performance and reasoning quality across five dimensions: conciseness, coherence, hallucination avoidance, task understanding, and internal consistency. We further present Mindora, a post-trained model optimized through a hybrid SFT-RL framework with an inconsistency-detection reward to enforce faithful and coherent reasoning. To support training, we construct high-quality trajectories using a novel reasoning trajectory generation strategy, that strategically filters difficult samples and applies a structured, consistency-oriented rewriting process to produce concise, readable, and well-balanced trajectories. Across 20 evaluated LLMs, Mindora achieves the highest average performance on MentraBench and shows remarkable performances in reasoning reliability, demonstrating its effectiveness for complex mental-health scenarios.
Plan Then Retrieve: Reinforcement Learning-Guided Complex Reasoning over Knowledge Graphs
Oct 23, 2025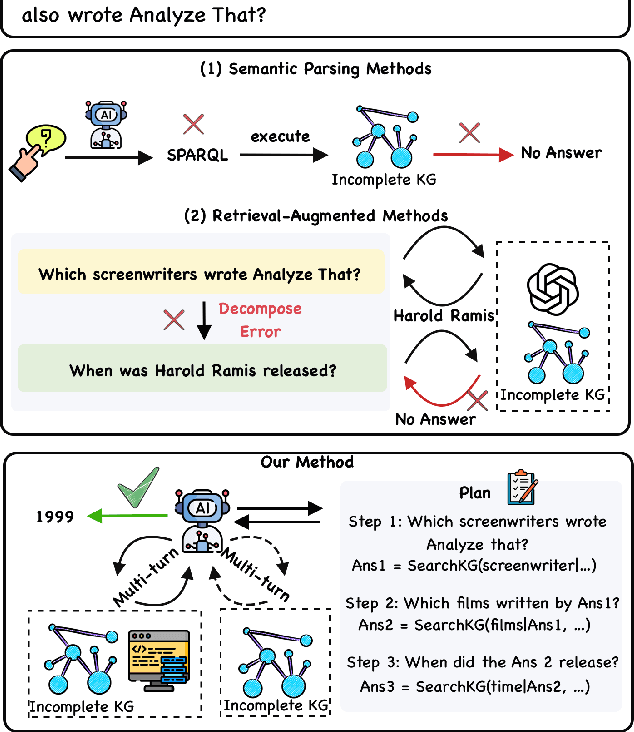

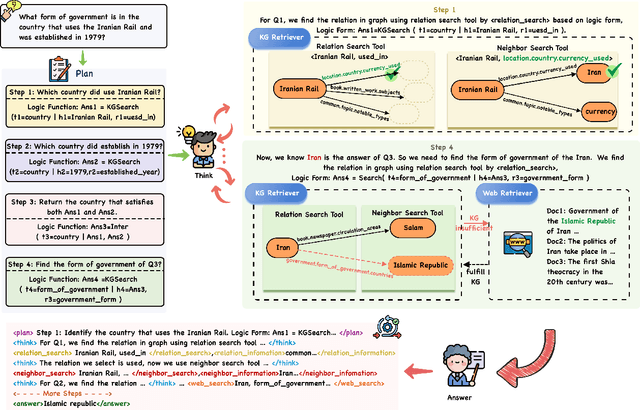
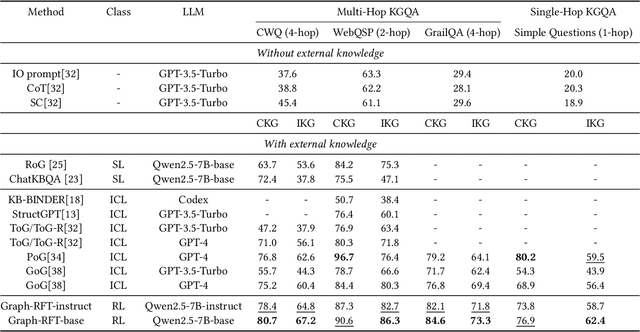
Knowledge Graph Question Answering aims to answer natural language questions by reasoning over structured knowledge graphs. While large language models have advanced KGQA through their strong reasoning capabilities, existing methods continue to struggle to fully exploit both the rich knowledge encoded in KGs and the reasoning capabilities of LLMs, particularly in complex scenarios. They often assume complete KG coverage and lack mechanisms to judge when external information is needed, and their reasoning remains locally myopic, failing to maintain coherent multi-step planning, leading to reasoning failures even when relevant knowledge exists. We propose Graph-RFT, a novel two-stage reinforcement fine-tuning KGQA framework with a 'plan-KGsearch-and-Websearch-during-think' paradigm, that enables LLMs to perform autonomous planning and adaptive retrieval scheduling across KG and web sources under incomplete knowledge conditions. Graph-RFT introduces a chain-of-thought fine-tuning method with a customized plan-retrieval dataset activates structured reasoning and resolves the GRPO cold-start problem. It then introduces a novel plan-retrieval guided reinforcement learning process integrates explicit planning and retrieval actions with a multi-reward design, enabling coverage-aware retrieval scheduling. It employs a Cartesian-inspired planning module to decompose complex questions into ordered subquestions, and logical expression to guide tool invocation for globally consistent multi-step reasoning. This reasoning retrieval process is optimized with a multi-reward combining outcome and retrieval specific signals, enabling the model to learn when and how to combine KG and web retrieval effectively.
Detection, Classification, and Mitigation of Gender Bias in Large Language Models
Jun 14, 2025With the rapid development of large language models (LLMs), they have significantly improved efficiency across a wide range of domains. However, recent studies have revealed that LLMs often exhibit gender bias, leading to serious social implications. Detecting, classifying, and mitigating gender bias in LLMs has therefore become a critical research focus. In the NLPCC 2025 Shared Task 7: Chinese Corpus for Gender Bias Detection, Classification and Mitigation Challenge, we investigate how to enhance the capabilities of LLMs in gender bias detection, classification, and mitigation. We adopt reinforcement learning, chain-of-thoughts (CoT) reasoning, and supervised fine-tuning to handle different Subtasks. Specifically, for Subtasks 1 and 2, we leverage the internal reasoning capabilities of LLMs to guide multi-step thinking in a staged manner, which simplifies complex biased queries and improves response accuracy. For Subtask 3, we employ a reinforcement learning-based approach, annotating a preference dataset using GPT-4. We then apply Direct Preference Optimization (DPO) to mitigate gender bias by introducing a loss function that explicitly favors less biased completions over biased ones. Our approach ranked first across all three subtasks of the NLPCC 2025 Shared Task 7.
A Retrieval-Augmented Multi-Agent Framework for Psychiatry Diagnosis
Jun 04, 2025The application of AI in psychiatric diagnosis faces significant challenges, including the subjective nature of mental health assessments, symptom overlap across disorders, and privacy constraints limiting data availability. To address these issues, we present MoodAngels, the first specialized multi-agent framework for mood disorder diagnosis. Our approach combines granular-scale analysis of clinical assessments with a structured verification process, enabling more accurate interpretation of complex psychiatric data. Complementing this framework, we introduce MoodSyn, an open-source dataset of 1,173 synthetic psychiatric cases that preserves clinical validity while ensuring patient privacy. Experimental results demonstrate that MoodAngels outperforms conventional methods, with our baseline agent achieving 12.3% higher accuracy than GPT-4o on real-world cases, and our full multi-agent system delivering further improvements. Evaluation in the MoodSyn dataset demonstrates exceptional fidelity, accurately reproducing both the core statistical patterns and complex relationships present in the original data while maintaining strong utility for machine learning applications. Together, these contributions provide both an advanced diagnostic tool and a critical research resource for computational psychiatry, bridging important gaps in AI-assisted mental health assessment.