 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection, Classification, and Mitigation of Gender Bias in Large Language Models
Jun 14, 2025With the rapid development of large language models (LLMs), they have significantly improved efficiency across a wide range of domains. However, recent studies have revealed that LLMs often exhibit gender bias, leading to serious social implications. Detecting, classifying, and mitigating gender bias in LLMs has therefore become a critical research focus. In the NLPCC 2025 Shared Task 7: Chinese Corpus for Gender Bias Detection, Classification and Mitigation Challenge, we investigate how to enhance the capabilities of LLMs in gender bias detection, classification, and mitigation. We adopt reinforcement learning, chain-of-thoughts (CoT) reasoning, and supervised fine-tuning to handle different Subtasks. Specifically, for Subtasks 1 and 2, we leverage the internal reasoning capabilities of LLMs to guide multi-step thinking in a staged manner, which simplifies complex biased queries and improves response accuracy. For Subtask 3, we employ a reinforcement learning-based approach, annotating a preference dataset using GPT-4. We then apply Direct Preference Optimization (DPO) to mitigate gender bias by introducing a loss function that explicitly favors less biased completions over biased ones. Our approach ranked first across all three subtasks of the NLPCC 2025 Shared Task 7.
BiasFilter: An Inference-Time Debiasing Framework for Large Language Models
May 28, 2025Mitigating social bias in large language models (LLMs) has become an increasingly important research objective. However, existing debiasing methods often incur high human and computational costs, exhibit limited effectiveness, and struggle to scale to larger models and open-ended generation tasks. To address these limitations, this paper proposes BiasFilter, a model-agnostic, inference-time debiasing framework that integrates seamlessly with both open-source and API-based LLMs. Instead of relying on retraining with balanced data or modifying model parameters, BiasFilter enforces fairness by filtering generation outputs in real time. Specifically, it periodically evaluates intermediate outputs every few tokens, maintains an active set of candidate continuations, and incrementally completes generation by discarding low-reward segments based on a fairness reward signal. To support this process, we construct a fairness preference dataset and train an implicit reward model to assess token-level fairness in generated responses. Extensive experiments demonstrate that BiasFilter effectively mitigates social bias across a range of LLMs while preserving overall generation quality.
LogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Multi-Domain Reasoning Challenges
May 24, 2025Text-to-SQL is a fundamental task in natural language processing that seeks to translate natural language questions into meaningful and executable SQL queries. While existing datasets are extensive and primarily focus on business scenarios and operational logic, they frequently lack coverage of domain-specific knowledge and complex mathematical reasoning. To address this gap, we present a novel dataset tailored for complex reasoning and chain-of-thought analysis in SQL inference, encompassing physical, arithmetic, commonsense, and hypothetical reasoning. The dataset consists of 4,038 English questions, each paired with a unique SQL query and accompanied by 12,114 step-by-step reasoning annotations, spanning 45 databases across diverse domains. Experimental results demonstrate that LogicCat substantially increases the difficulty for state-of-the-art models, with the highest execution accuracy reaching only 14.96%. Incorporating our chain-of-thought annotations boosts performance to 33.96%. Benchmarking leading public methods on Spider and BIRD further underscores the unique challenges presented by LogicCat, highlighting the significant opportunities for advancing research in robust, reasoning-driven text-to-SQL systems. We have released our dataset code at https://github.com/Ffunkytao/LogicCat.
JOLT-SQL: Joint Loss Tuning of Text-to-SQL with Confusion-aware Noisy Schema Sampling
May 20, 2025

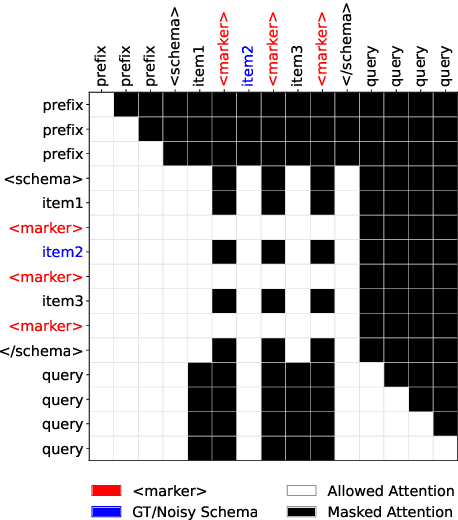

Text-to-SQL, which maps natural language to SQL queries, has benefited greatly from recent advances in Large Language Models (LLMs). While LLMs offer various paradigms for this task, including prompting and supervised fine-tuning (SFT), SFT approaches still face challenges such as complex multi-stage pipelines and poor robustness to noisy schema information. To address these limitations, we present JOLT-SQL, a streamlined single-stage SFT framework that jointly optimizes schema linking and SQL generation via a unified loss. JOLT-SQL employs discriminative schema linking, enhanced by local bidirectional attention, alongside a confusion-aware noisy schema sampling strategy with selective attention to improve robustness under noisy schema conditions. Experiments on the Spider and BIRD benchmarks demonstrate that JOLT-SQL achieves state-of-the-art execution accuracy among comparable-size open-source models, while significantly improving both training and inference efficiency.
SILC-EFSA: Self-aware In-context Learning Correction for Entity-level Financial Sentiment Analysis
Dec 26, 2024



In recent years, fine-grained sentiment analysis in finance has gained significant attention, but the scarcity of entity-level datasets remains a key challenge. To address this, we have constructed the largest English and Chinese financial entity-level sentiment analysis datasets to date. Building on this foundation, we propose a novel two-stage sentiment analysis approach called Self-aware In-context Learning Correction (SILC). The first stage involves fine-tuning a base large language model to generate pseudo-labeled data specific to our task. In the second stage, we train a correction model using a GNN-based example retriever, which is informed by the pseudo-labeled data. This two-stage strategy has allowed us to achieve state-of-the-art performance on the newly constructed datasets, advancing the field of financial sentiment analysis. In a case study, we demonstrate the enhanced practical utility of our data and methods in monitoring the cryptocurrency market. Our datasets and code are available at https://github.com/NLP-Bin/SILC-EFSA.
ZZU-NLP at SIGHAN-2024 dimABSA Task: Aspect-Based Sentiment Analysis with Coarse-to-Fine In-context Learning
Jul 22, 2024



The DimABSA task requires fine-grained sentiment intensity prediction for restaurant reviews, including scores for Valence and Arousal dimensions for each Aspect Term. In this study, we propose a Coarse-to-Fine In-context Learning(CFICL) method based on the Baichuan2-7B model for the DimABSA task in the SIGHAN 2024 workshop. Our method improves prediction accuracy through a two-stage optimization process. In the first stage, we use fixed in-context examples and prompt templates to enhance the model's sentiment recognition capability and provide initial predictions for the test data. In the second stage, we encode the Opinion field using BERT and select the most similar training data as new in-context examples based on similarity. These examples include the Opinion field and its scores, as well as related opinion words and their average scores. By filtering for sentiment polarity, we ensure that the examples are consistent with the test data. Our method significantly improves prediction accuracy and consistency by effectively utilizing training data and optimizing in-context examples, as validated by experimental results.
MRC-based Nested Medical NER with Co-prediction and Adaptive Pre-training
Mar 23, 2024
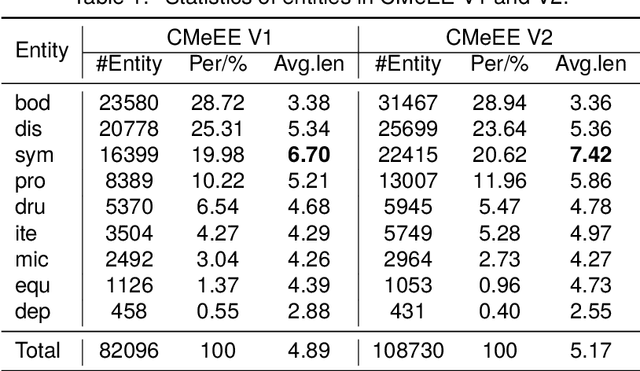
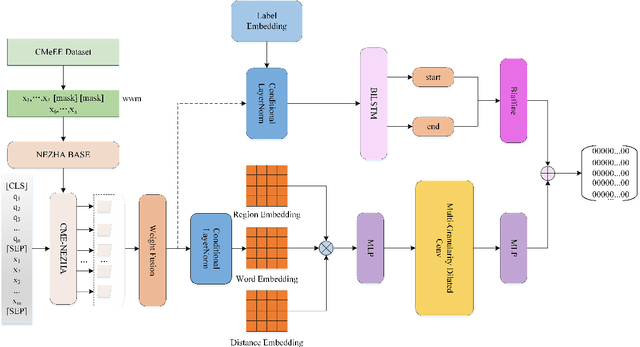
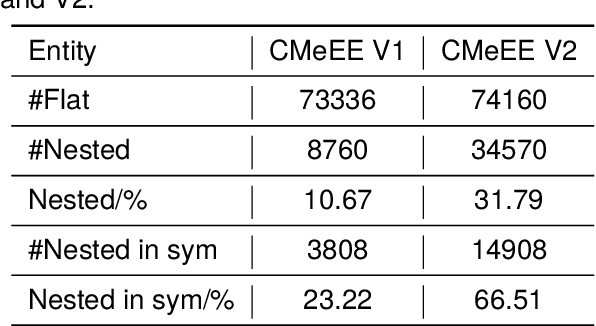
In medical information extraction, medical Named Entity Recognition (NER) is indispensable, playing a crucial role in developing medical knowledge graphs, enhancing medical question-answering systems, and analyzing electronic medical records. The challenge in medical NER arises from the complex nested structures and sophisticated medical terminologies, distinguishing it from its counterparts in traditional domains. In response to these complexities, we propose a medical NER model based on Machine Reading Comprehension (MRC), which uses a task-adaptive pre-training strategy to improve the model's capability in the medical field. Meanwhile, our model introduces multiple word-pair embeddings and multi-granularity dilated convolution to enhance the model's representation ability and uses a combined predictor of Biaffine and MLP to improve the model's recognition performance. Experimental evaluations conducted on the CMeEE, a benchmark for Chinese nested medical NER, demonstrate that our proposed model outperforms the compared state-of-the-art (SOTA) models.
OpenEval: Benchmarking Chinese LLMs across Capability, Alignment and Safety
Mar 18, 2024



The rapid development of Chinese large language models (LLMs) poses big challenges for efficient LLM evaluation. While current initiatives have introduced new benchmarks or evaluation platforms for assessing Chinese LLMs, many of these focus primarily on capabilities, usually overlooking potential alignment and safety issues. To address this gap, we introduce OpenEval, an evaluation testbed that benchmarks Chinese LLMs across capability, alignment and safety. For capability assessment, we include 12 benchmark datasets to evaluate Chinese LLMs from 4 sub-dimensions: NLP tasks, disciplinary knowledge, commonsense reasoning and mathematical reasoning. For alignment assessment, OpenEval contains 7 datasets that examines the bias, offensiveness and illegalness in the outputs yielded by Chinese LLMs. To evaluate safety, especially anticipated risks (e.g., power-seeking, self-awareness) of advanced LLMs, we include 6 datasets. In addition to these benchmarks, we have implemented a phased public evaluation and benchmark update strategy to ensure that OpenEval is in line with the development of Chinese LLMs or even able to provide cutting-edge benchmark datasets to guide the development of Chinese LLMs. In our first public evaluation, we have tested a range of Chinese LLMs, spanning from 7B to 72B parameters, including both open-source and proprietary models. Evaluation results indicate that while Chinese LLMs have shown impressive performance in certain tasks, more attention should be directed towards broader aspects such as commonsense reasoning, alignment, and safety.
A Corpus for Named Entity Recognition in Chinese Novels with Multi-genres
Nov 27, 2023Entities like person, location, organization are important for literary text analysis. The lack of annotated data hinders the progress of named entity recognition (NER) in literary domain. To promote the research of literary NER, we build the largest multi-genre literary NER corpus containing 263,135 entities in 105,851 sentences from 260 online Chinese novels spanning 13 different genres. Based on the corpus, we investigate characteristics of entities from different genres. We propose several baseline NER models and conduct cross-genre and cross-domain experiments. Experimental results show that genre difference significantly impact NER performance though not as much as domain difference like literary domain and news domain. Compared with NER in news domain, literary NER still needs much improvement and the Out-of-Vocabulary (OOV) problem is more challenging due to the high variety of entities in literary works.
Zhongjing: Enhancing the Chinese Medical Capabilities of Large Language Model through Expert Feedback and Real-world Multi-turn Dialogue
Aug 14, 2023Recent advances in Large Language Models (LLMs) have achieved remarkable breakthroughs in understanding and responding to user intents. However, their performance lag behind general use cases in some expertise domains, such as Chinese medicine. Existing efforts to incorporate Chinese medicine into LLMs rely on Supervised Fine-Tuning (SFT) with single-turn and distilled dialogue data. These models lack the ability for doctor-like proactive inquiry and multi-turn comprehension and cannot always align responses with safety and professionalism experts. In this work, we introduce Zhongjing, the first Chinese medical LLaMA-based LLM that implements an entire training pipeline from pre-training to reinforcement learning with human feedback (RLHF). Additionally, we introduce a Chinese multi-turn medical dialogue dataset of 70,000 authentic doctor-patient dialogues, CMtMedQA, which significantly enhances the model's capability for complex dialogue and proactive inquiry initiation. We define a refined annotation rule and evaluation criteria given the biomedical domain's unique characteristics. Results show that our model outperforms baselines in various capacities and matches the performance of ChatGPT in a few abilities, despite having 50x training data with previous best model and 100x parameters with ChatGPT. RLHF further improves the model's instruction-following ability and safety.We also release our code, datasets and model for further research.