 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Speech, Emotion, and Motion: a VLM-based Multimodal Edge-deployable Framework for Humanoid Robots
Feb 07, 2026Effective human-robot interaction requires emotionally rich multimodal expressions, yet most humanoid robots lack coordinated speech, facial expressions, and gestures. Meanwhile, real-world deployment demands on-device solutions that can operate autonomously without continuous cloud connectivity. To bridging \underline{\textit{S}}peech, \underline{\textit{E}}motion, and \underline{\textit{M}}otion, we present \textit{SeM$^2$}, a Vision Language Model-based framework that orchestrates emotionally coherent multimodal interactions through three key components: a multimodal perception module capturing user contextual cues, a Chain-of-Thought reasoning for response planning, and a novel Semantic-Sequence Aligning Mechanism (SSAM) that ensures precise temporal coordination between verbal content and physical expressions. We implement both cloud-based and \underline{\textit{e}}dge-deployed versions (\textit{SeM$^2_e$}), with the latter knowledge distilled to operate efficiently on edge hardware while maintaining 95\% of the relative performance. Comprehensive evaluations demonstrate that our approach significantly outperforms unimodal baselines in naturalness, emotional clarity, and modal coherence, advancing socially expressive humanoid robotics for diverse real-world environments.
When Attention Betrays: Erasing Backdoor Attacks in Robotic Policies by Reconstructing Visual Tokens
Feb 03, 2026Downstream fine-tuning of vision-language-action (VLA) models enhances robotics, yet exposes the pipeline to backdoor risks. Attackers can pretrain VLAs on poisoned data to implant backdoors that remain stealthy but can trigger harmful behavior during inference. However, existing defenses either lack mechanistic insight into multimodal backdoors or impose prohibitive computational costs via full-model retraining. To this end, we uncover a deep-layer attention grabbing mechanism: backdoors redirect late-stage attention and form compact embedding clusters near the clean manifold. Leveraging this insight, we introduce Bera, a test-time backdoor erasure framework that detects tokens with anomalous attention via latent-space localization, masks suspicious regions using deep-layer cues, and reconstructs a trigger-free image to break the trigger-unsafe-action mapping while restoring correct behavior. Unlike prior defenses, Bera requires neither retraining of VLAs nor any changes to the training pipeline. Extensive experiments across multiple embodied platforms and tasks show that Bera effectively maintains nominal performance, significantly reduces attack success rates, and consistently restores benign behavior from backdoored outputs, thereby offering a robust and practical defense mechanism for securing robotic systems.
RGMP: Recurrent Geometric-prior Multimodal Policy for Generalizable Humanoid Robot Manipulation
Nov 12, 2025Humanoid robots exhibit significant potential in executing diverse human-level skills. However, current research predominantly relies on data-driven approaches that necessitate extensive training datasets to achieve robust multimodal decision-making capabilities and generalizable visuomotor control. These methods raise concerns due to the neglect of geometric reasoning in unseen scenarios and the inefficient modeling of robot-target relationships within the training data, resulting in significant waste of training resources. To address these limitations, we present the Recurrent Geometric-prior Multimodal Policy (RGMP), an end-to-end framework that unifies geometric-semantic skill reasoning with data-efficient visuomotor control. For perception capabilities, we propose the Geometric-prior Skill Selector, which infuses geometric inductive biases into a vision language model, producing adaptive skill sequences for unseen scenes with minimal spatial common sense tuning. To achieve data-efficient robotic motion synthesis, we introduce the Adaptive Recursive Gaussian Network, which parameterizes robot-object interactions as a compact hierarchy of Gaussian processes that recursively encode multi-scale spatial relationships, yielding dexterous, data-efficient motion synthesis even from sparse demonstrations. Evaluated on both our humanoid robot and desktop dual-arm robot, the RGMP framework achieves 87% task success in generalization tests and exhibits 5x greater data efficiency than the state-of-the-art model. This performance underscores its superior cross-domain generalization, enabled by geometric-semantic reasoning and recursive-Gaussion adaptation.
Learning Robust Grasping Strategy Through Tactile Sensing and Adaption Skill
Nov 13, 2024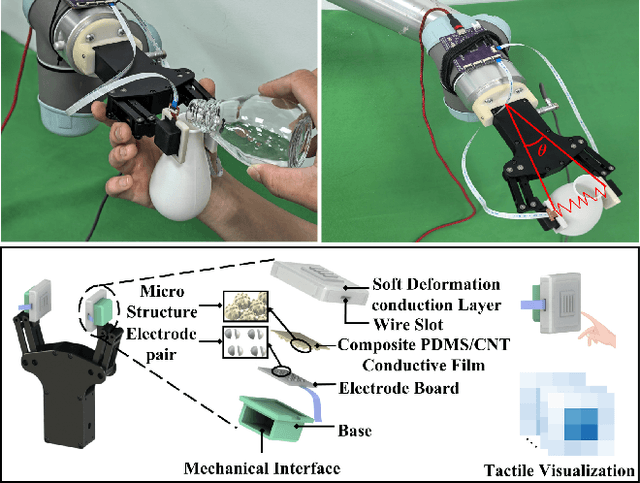
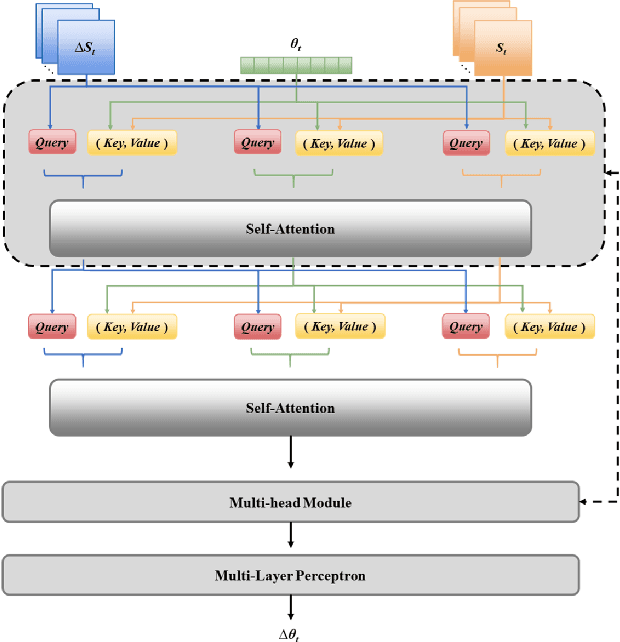
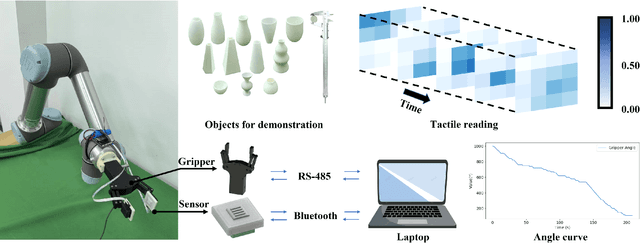
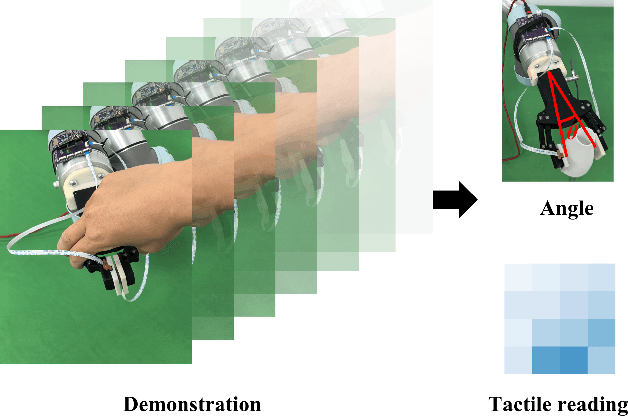
Robust grasping represents an essential task in robotics, necessitating tactile feedback and reactive grasping adjustments for robust grasping of objects. Previous research has extensively combined tactile sensing with grasping, primarily relying on rule-based approaches, frequently neglecting post-grasping difficulties such as external disruptions or inherent uncertainties of the object's physics and geometry. To address these limitations, this paper introduces an human-demonstration-based adaptive grasping policy base on tactile, which aims to achieve robust gripping while resisting disturbances to maintain grasp stability. Our trained model generalizes to daily objects with seven different sizes, shapes, and textures. Experimental results demonstrate that our method performs well in dynamic and force interaction tasks and exhibits excellent generalization ability.
FaiMA: Feature-aware In-context Learning for Multi-domain Aspect-based Sentiment Analysis
Mar 02, 2024



Multi-domain aspect-based sentiment analysis (ABSA) seeks to capture fine-grained sentiment across diverse domains. While existing research narrowly focuses on single-domain applications constrained by methodological limitations and data scarcity, the reality is that sentiment naturally traverses multiple domains. Although large language models (LLMs) offer a promising solution for ABSA, it is difficult to integrate effectively with established techniques, including graph-based models and linguistics, because modifying their internal architecture is not easy. To alleviate this problem, we propose a novel framework, Feature-aware In-context Learning for Multi-domain ABSA (FaiMA). The core insight of FaiMA is to utilize in-context learning (ICL) as a feature-aware mechanism that facilitates adaptive learning in multi-domain ABSA tasks. Specifically, we employ a multi-head graph attention network as a text encoder optimized by heuristic rules for linguistic, domain, and sentiment features. Through contrastive learning, we optimize sentence representations by focusing on these diverse features. Additionally, we construct an efficient indexing mechanism, allowing FaiMA to stably retrieve highly relevant examples across multiple dimensions for any given input. To evaluate the efficacy of FaiMA, we build the first multi-domain ABSA benchmark dataset. Extensive experimental results demonstrate that FaiMA achieves significant performance improvements in multiple domains compared to baselines, increasing F1 by 2.07% on average. Source code and data sets are anonymously available at https://github.com/SupritYoung/FaiMA.
Kuaiji: the First Chinese Accounting Large Language Model
Feb 24, 2024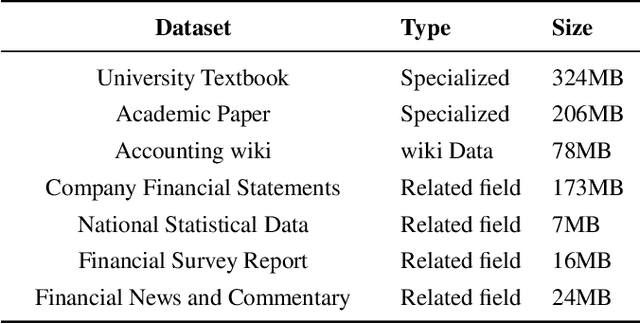
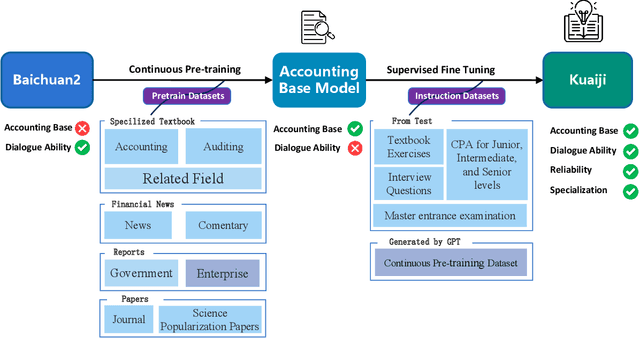
Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated impressive proficiency in comprehending and generating natural language. However, they encounter difficulties when tasked with adapting to specialized domains such as accounting. To address this challenge, we introduce Kuaiji, a tailored Accounting Large Language Model. Kuaiji is meticulously fine-tuned using the Baichuan framework, which encompasses continuous pre-training and supervised fine-tuning processes. Supported by CAtAcctQA, a dataset containing large genuine accountant-client dialogues, Kuaiji exhibits exceptional accuracy and response speed. Our contributions encompass the creation of the first Chinese accounting dataset, the establishment of Kuaiji as a leading open-source Chinese accounting LLM, and the validation of its efficacy through real-world accounting scenarios.
LLM-Detector: Improving AI-Generated Chinese Text Detection with Open-Source LLM Instruction Tuning
Feb 02, 2024ChatGPT and other general large language models (LLMs) have achieved remarkable success, but they have also raised concerns about the misuse of AI-generated texts. Existing AI-generated text detection models, such as based on BERT and RoBERTa, are prone to in-domain over-fitting, leading to poor out-of-domain (OOD) detection performance. In this paper, we first collected Chinese text responses generated by human experts and 9 types of LLMs, for which to multiple domains questions, and further created a dataset that mixed human-written sentences and sentences polished by LLMs. We then proposed LLM-Detector, a novel method for both document-level and sentence-level text detection through Instruction Tuning of LLMs. Our method leverages the wealth of knowledge LLMs acquire during pre-training, enabling them to detect the text they generate. Instruction tuning aligns the model's responses with the user's expected text detection tasks. Experimental results show that previous methods struggle with sentence-level AI-generated text detection and OOD detection. In contrast, our proposed method not only significantly outperforms baseline methods in both sentence-level and document-level text detection but also demonstrates strong generalization capabilities. Furthermore, since LLM-Detector is trained based on open-source LLMs, it is easy to customize for deployment.
Knowledge-injected Prompt Learning for Chinese Biomedical Entity Normalization
Aug 23, 2023The Biomedical Entity Normalization (BEN) task aims to align raw, unstructured medical entities to standard entities, thus promoting data coherence and facilitating better downstream medical applications. Recently, prompt learning methods have shown promising results in this task. However, existing research falls short in tackling the more complex Chinese BEN task, especially in the few-shot scenario with limited medical data, and the vast potential of the external medical knowledge base has yet to be fully harnessed. To address these challenges, we propose a novel Knowledge-injected Prompt Learning (PL-Knowledge) method. Specifically, our approach consists of five stages: candidate entity matching, knowledge extraction, knowledge encoding, knowledge injection, and prediction output. By effectively encoding the knowledge items contained in medical entities and incorporating them into our tailor-made knowledge-injected templates, the additional knowledge enhances the model's ability to capture latent relationships between medical entities, thus achieving a better match with the standard entities. We extensively evaluate our model on a benchmark dataset in both few-shot and full-scale scenarios. Our method outperforms existing baselines, with an average accuracy boost of 12.96\% in few-shot and 0.94\% in full-data cases, showcasing its excellence in the BEN task.
Zhongjing: Enhancing the Chinese Medical Capabilities of Large Language Model through Expert Feedback and Real-world Multi-turn Dialogue
Aug 14, 2023Recent advances in Large Language Models (LLMs) have achieved remarkable breakthroughs in understanding and responding to user intents. However, their performance lag behind general use cases in some expertise domains, such as Chinese medicine. Existing efforts to incorporate Chinese medicine into LLMs rely on Supervised Fine-Tuning (SFT) with single-turn and distilled dialogue data. These models lack the ability for doctor-like proactive inquiry and multi-turn comprehension and cannot always align responses with safety and professionalism experts. In this work, we introduce Zhongjing, the first Chinese medical LLaMA-based LLM that implements an entire training pipeline from pre-training to reinforcement learning with human feedback (RLHF). Additionally, we introduce a Chinese multi-turn medical dialogue dataset of 70,000 authentic doctor-patient dialogues, CMtMedQA, which significantly enhances the model's capability for complex dialogue and proactive inquiry initiation. We define a refined annotation rule and evaluation criteria given the biomedical domain's unique characteristics. Results show that our model outperforms baselines in various capacities and matches the performance of ChatGPT in a few abilities, despite having 50x training data with previous best model and 100x parameters with ChatGPT. RLHF further improves the model's instruction-following ability and safety.We also release our code, datasets and model for further research.