 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSILC-EFSA: Self-aware In-context Learning Correction for Entity-level Financial Sentiment Analysis
Dec 26, 2024



In recent years, fine-grained sentiment analysis in finance has gained significant attention, but the scarcity of entity-level datasets remains a key challenge. To address this, we have constructed the largest English and Chinese financial entity-level sentiment analysis datasets to date. Building on this foundation, we propose a novel two-stage sentiment analysis approach called Self-aware In-context Learning Correction (SILC). The first stage involves fine-tuning a base large language model to generate pseudo-labeled data specific to our task. In the second stage, we train a correction model using a GNN-based example retriever, which is informed by the pseudo-labeled data. This two-stage strategy has allowed us to achieve state-of-the-art performance on the newly constructed datasets, advancing the field of financial sentiment analysis. In a case study, we demonstrate the enhanced practical utility of our data and methods in monitoring the cryptocurrency market. Our datasets and code are available at https://github.com/NLP-Bin/SILC-EFSA.
Identifying Speakers and Addressees of Quotations in Novels with Prompt Learning
Aug 18, 2024


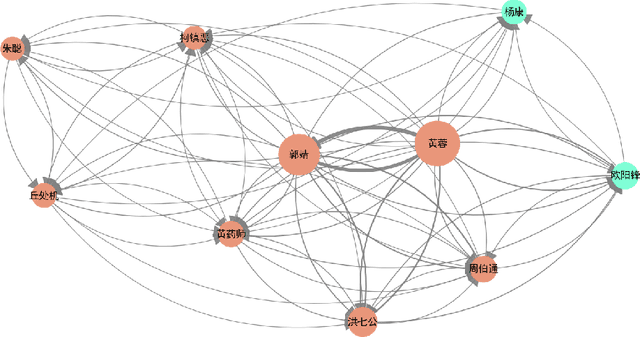
Quotations in literary works, especially novels, are important to create characters, reflect character relationships, and drive plot development. Current research on quotation extraction in novels primarily focuses on quotation attribution, i.e., identifying the speaker of the quotation. However, the addressee of the quotation is also important to construct the relationship between the speaker and the addressee. To tackle the problem of dataset scarcity, we annotate the first Chinese quotation corpus with elements including speaker, addressee, speaking mode and linguistic cue. We propose prompt learning-based methods for speaker and addressee identification based on fine-tuned pre-trained models. Experiments on both Chinese and English datasets show the effectiveness of the proposed methods, which outperform methods based on zero-shot and few-shot large language models.
ZZU-NLP at SIGHAN-2024 dimABSA Task: Aspect-Based Sentiment Analysis with Coarse-to-Fine In-context Learning
Jul 22, 2024



The DimABSA task requires fine-grained sentiment intensity prediction for restaurant reviews, including scores for Valence and Arousal dimensions for each Aspect Term. In this study, we propose a Coarse-to-Fine In-context Learning(CFICL) method based on the Baichuan2-7B model for the DimABSA task in the SIGHAN 2024 workshop. Our method improves prediction accuracy through a two-stage optimization process. In the first stage, we use fixed in-context examples and prompt templates to enhance the model's sentiment recognition capability and provide initial predictions for the test data. In the second stage, we encode the Opinion field using BERT and select the most similar training data as new in-context examples based on similarity. These examples include the Opinion field and its scores, as well as related opinion words and their average scores. By filtering for sentiment polarity, we ensure that the examples are consistent with the test data. Our method significantly improves prediction accuracy and consistency by effectively utilizing training data and optimizing in-context examples, as validated by experimental results.
Zhongjing: Enhancing the Chinese Medical Capabilities of Large Language Model through Expert Feedback and Real-world Multi-turn Dialogue
Aug 14, 2023Recent advances in Large Language Models (LLMs) have achieved remarkable breakthroughs in understanding and responding to user intents. However, their performance lag behind general use cases in some expertise domains, such as Chinese medicine. Existing efforts to incorporate Chinese medicine into LLMs rely on Supervised Fine-Tuning (SFT) with single-turn and distilled dialogue data. These models lack the ability for doctor-like proactive inquiry and multi-turn comprehension and cannot always align responses with safety and professionalism experts. In this work, we introduce Zhongjing, the first Chinese medical LLaMA-based LLM that implements an entire training pipeline from pre-training to reinforcement learning with human feedback (RLHF). Additionally, we introduce a Chinese multi-turn medical dialogue dataset of 70,000 authentic doctor-patient dialogues, CMtMedQA, which significantly enhances the model's capability for complex dialogue and proactive inquiry initiation. We define a refined annotation rule and evaluation criteria given the biomedical domain's unique characteristics. Results show that our model outperforms baselines in various capacities and matches the performance of ChatGPT in a few abilities, despite having 50x training data with previous best model and 100x parameters with ChatGPT. RLHF further improves the model's instruction-following ability and safety.We also release our code, datasets and model for further research.