 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathFound: An Agentic Multimodal Model Activating Evidence-seeking Pathological Diagnosis
Dec 29, 2025Recent pathological foundation models have substantially advanced visual representation learning and multimodal interaction. However, most models still rely on a static inference paradigm in which whole-slide images are processed once to produce predictions, without reassessment or targeted evidence acquisition under ambiguous diagnoses. This contrasts with clinical diagnostic workflows that refine hypotheses through repeated slide observations and further examination requests. We propose PathFound, an agentic multimodal model designed to support evidence-seeking inference in pathological diagnosis. PathFound integrates the power of pathological visual foundation models, vision-language models, and reasoning models trained with reinforcement learning to perform proactive information acquisition and diagnosis refinement by progressing through the initial diagnosis, evidence-seeking, and final decision stages. Across several large multimodal models, adopting this strategy consistently improves diagnostic accuracy, indicating the effectiveness of evidence-seeking workflows in computational pathology. Among these models, PathFound achieves state-of-the-art diagnostic performance across diverse clinical scenarios and demonstrates strong potential to discover subtle details, such as nuclear features and local invasions.
Surrogate Modeling via Factorization Machine and Ising Model with Enhanced Higher-Order Interaction Learning
Jul 02, 2025Recently, a surrogate model was proposed that employs a factorization machine to approximate the underlying input-output mapping of the original system, with quantum annealing used to optimize the resulting surrogate function. Inspired by this approach, we propose an enhanced surrogate model that incorporates additional slack variables into both the factorization machine and its associated Ising representation thereby unifying what was by design a two-step process into a single, integrated step. During the training phase, the slack variables are iteratively updated, enabling the model to account for higher-order feature interactions. We apply the proposed method to the task of predicting drug combination effects. Experimental results indicate that the introduction of slack variables leads to a notable improvement of performance. Our algorithm offers a promising approach for building efficient surrogate models that exploit potential quantum advantages.
Towards Extreme Pruning of LLMs with Plug-and-Play Mixed Sparsity
Mar 14, 2025N:M structured pruning is essential for large language models (LLMs) because it can remove less important network weights and reduce the memory and computation requirements. Existing pruning methods mainly focus on designing metrics to measure the importance of network components to guide pruning. Apart from the impact of these metrics, we observe that different layers have different sensitivities over the network performance. Thus, we propose an efficient method based on the trace of Fisher Information Matrix (FIM) to quantitatively measure and verify the different sensitivities across layers. Based on this, we propose Mixed Sparsity Pruning (MSP) which uses a pruning-oriented evolutionary algorithm (EA) to determine the optimal sparsity levels for different layers. To guarantee fast convergence and achieve promising performance, we utilize efficient FIM-inspired layer-wise sensitivity to initialize the population of EA. In addition, our MSP can work as a plug-and-play module, ready to be integrated into existing pruning methods. Extensive experiments on LLaMA and LLaMA-2 on language modeling and zero-shot tasks demonstrate our superior performance. In particular, in extreme pruning ratio (e.g. 75%), our method significantly outperforms existing methods in terms of perplexity (PPL) by orders of magnitude (Figure 1).
UM_FHS at TREC 2024 PLABA: Exploration of Fine-tuning and AI agent approach for plain language adaptations of biomedical text
Feb 19, 2025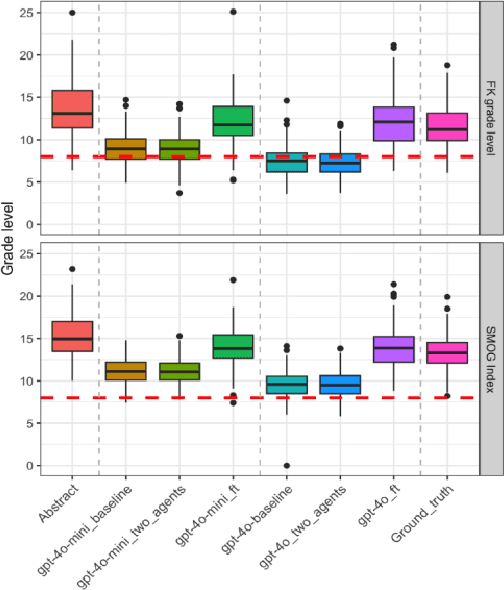
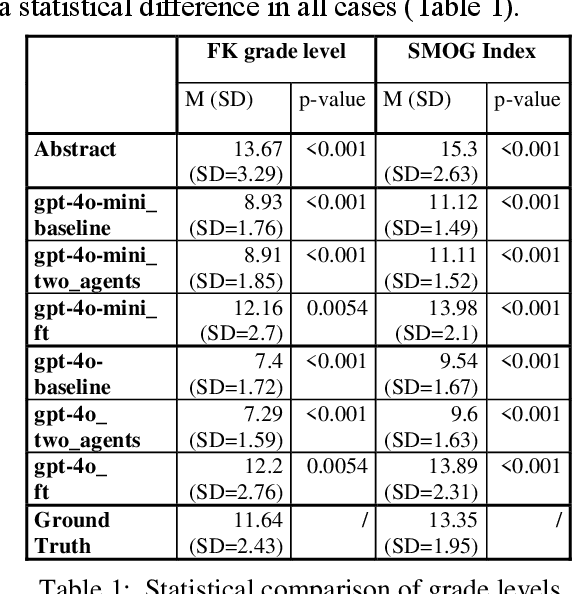
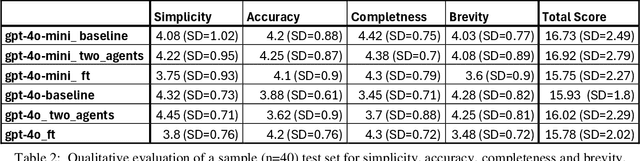
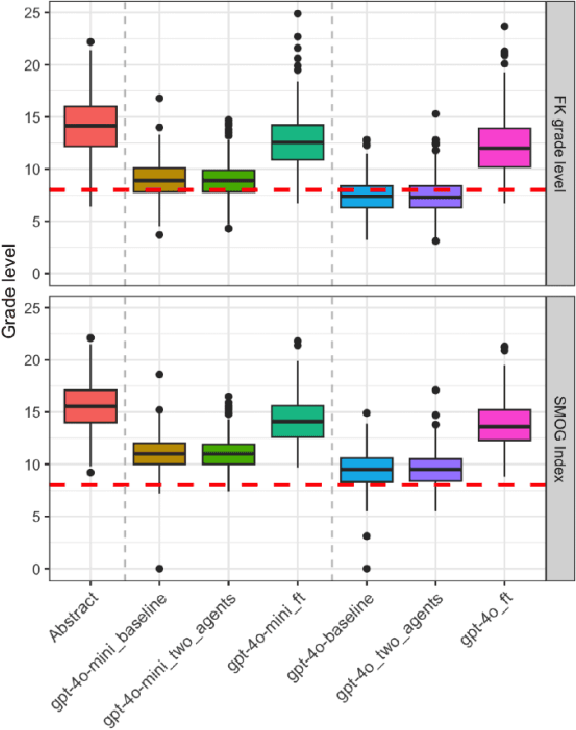
This paper describes our submissions to the TREC 2024 PLABA track with the aim to simplify biomedical abstracts for a K8-level audience (13-14 years old students). We tested three approaches using OpenAI's gpt-4o and gpt-4o-mini models: baseline prompt engineering, a two-AI agent approach, and fine-tuning. Adaptations were evaluated using qualitative metrics (5-point Likert scales for simplicity, accuracy, completeness, and brevity) and quantitative readability scores (Flesch-Kincaid grade level, SMOG Index). Results indicated that the two-agent approach and baseline prompt engineering with gpt-4o-mini models show superior qualitative performance, while fine-tuned models excelled in accuracy and completeness but were less simple. The evaluation results demonstrated that prompt engineering with gpt-4o-mini outperforms iterative improvement strategies via two-agent approach as well as fine-tuning with gpt-4o. We intend to expand our investigation of the results and explore advanced evaluations.
Identifying Speakers and Addressees of Quotations in Novels with Prompt Learning
Aug 18, 2024


Quotations in literary works, especially novels, are important to create characters, reflect character relationships, and drive plot development. Current research on quotation extraction in novels primarily focuses on quotation attribution, i.e., identifying the speaker of the quotation. However, the addressee of the quotation is also important to construct the relationship between the speaker and the addressee. To tackle the problem of dataset scarcity, we annotate the first Chinese quotation corpus with elements including speaker, addressee, speaking mode and linguistic cue. We propose prompt learning-based methods for speaker and addressee identification based on fine-tuned pre-trained models. Experiments on both Chinese and English datasets show the effectiveness of the proposed methods, which outperform methods based on zero-shot and few-shot large language models.
UniCompress: Enhancing Multi-Data Medical Image Compression with Knowledge Distillation
May 27, 2024In the field of medical image compression, Implicit Neural Representation (INR) networks have shown remarkable versatility due to their flexible compression ratios, yet they are constrained by a one-to-one fitting approach that results in lengthy encoding times. Our novel method, ``\textbf{UniCompress}'', innovatively extends the compression capabilities of INR by being the first to compress multiple medical data blocks using a single INR network. By employing wavelet transforms and quantization, we introduce a codebook containing frequency domain information as a prior input to the INR network. This enhances the representational power of INR and provides distinctive conditioning for different image blocks. Furthermore, our research introduces a new technique for the knowledge distillation of implicit representations, simplifying complex model knowledge into more manageable formats to improve compression ratios. Extensive testing on CT and electron microscopy (EM) datasets has demonstrated that UniCompress outperforms traditional INR methods and commercial compression solutions like HEVC, especially in complex and high compression scenarios. Notably, compared to existing INR techniques, UniCompress achieves a 4$\sim$5 times increase in compression speed, marking a significant advancement in the field of medical image compression. Codes will be publicly available.
YNetr: Dual-Encoder architecture on Plain Scan Liver Tumors
Mar 30, 2024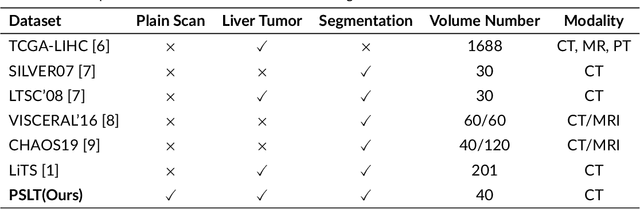

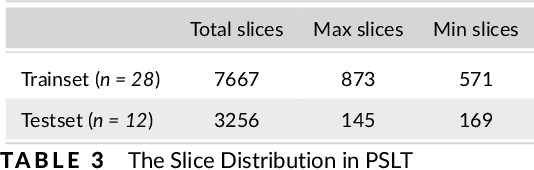
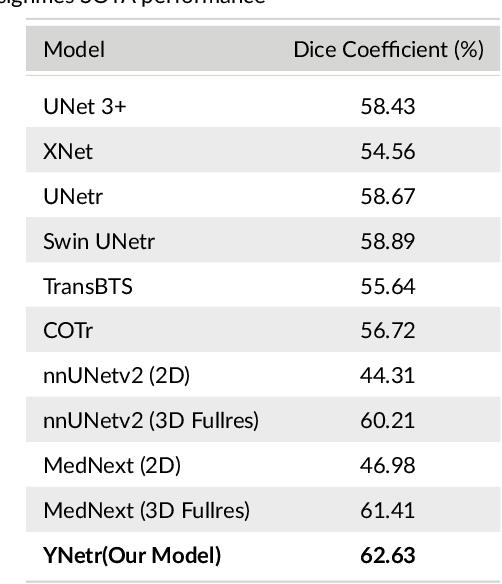
Background: Liver tumors are abnormal growths in the liver that can be either benign or malignant, with liver cancer being a significant health concern worldwide. However, there is no dataset for plain scan segmentation of liver tumors, nor any related algorithms. To fill this gap, we propose Plain Scan Liver Tumors(PSLT) and YNetr. Methods: A collection of 40 liver tumor plain scan segmentation datasets was assembled and annotated. Concurrently, we utilized Dice coefficient as the metric for assessing the segmentation outcomes produced by YNetr, having advantage of capturing different frequency information. Results: The YNetr model achieved a Dice coefficient of 62.63% on the PSLT dataset, surpassing the other publicly available model by an accuracy margin of 1.22%. Comparative evaluations were conducted against a range of models including UNet 3+, XNet, UNetr, Swin UNetr, Trans-BTS, COTr, nnUNetv2 (2D), nnUNetv2 (3D fullres), MedNext (2D) and MedNext(3D fullres). Conclusions: We not only proposed a dataset named PSLT(Plain Scan Liver Tumors), but also explored a structure called YNetr that utilizes wavelet transform to extract different frequency information, which having the SOTA in PSLT by experiments.
Empowering Federated Learning for Massive Models with NVIDIA FLARE
Feb 12, 2024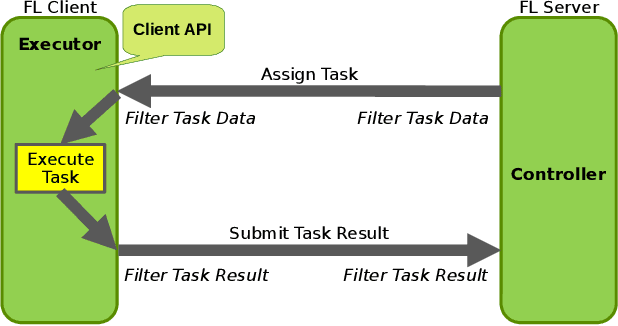

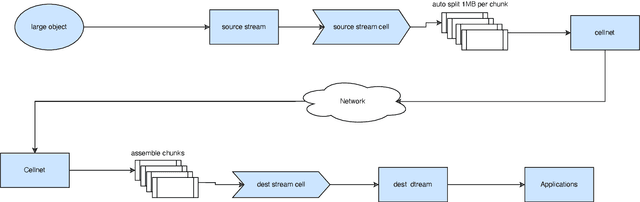
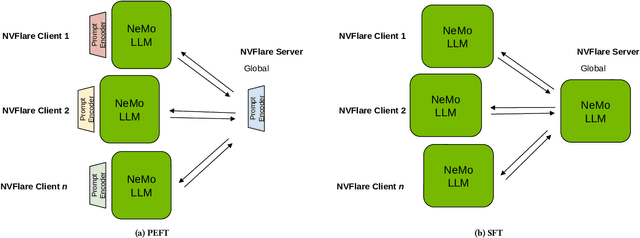
In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.
GPT4Battery: An LLM-driven Framework for Adaptive State of Health Estimation of Raw Li-ion Batteries
Jan 30, 2024



State of health (SOH) is a crucial indicator for assessing the degradation level of batteries that cannot be measured directly but requires estimation. Accurate SOH estimation enhances detection, control, and feedback for Li-ion batteries, allowing for safe and efficient energy management and guiding the development of new-generation batteries. Despite the significant progress in data-driven SOH estimation, the time and resource-consuming degradation experiments for generating lifelong training data pose a challenge in establishing one large model capable of handling diverse types of Li-ion batteries, e.g., cross-chemistry, cross-manufacturer, and cross-capacity. Hence, this paper utilizes the strong generalization capability of large language model (LLM) to proposes a novel framework for adaptable SOH estimation across diverse batteries. To match the real scenario where unlabeled data sequentially arrives in use with distribution shifts, the proposed model is modified by a test-time training technique to ensure estimation accuracy even at the battery's end of life. The validation results demonstrate that the proposed framework achieves state-of-the-art accuracy on four widely recognized datasets collected from 62 batteries. Furthermore, we analyze the theoretical challenges of cross-battery estimation and provide a quantitative explanation of the effectiveness of our method.
Lightweight High-Speed Photography Built on Coded Exposure and Implicit Neural Representation of Videos
Nov 22, 2023The compact cameras recording high-speed scenes with high resolution are highly demanded, but the required high bandwidth often leads to bulky, heavy systems, which limits their applications on low-capacity platforms. Adopting a coded exposure setup to encode a frame sequence into a blurry snapshot and retrieve the latent sharp video afterward can serve as a lightweight solution. However, restoring motion from blur is quite challenging due to the high ill-posedness of motion blur decomposition, intrinsic ambiguity in motion direction, and diverse motions in natural videos. In this work, by leveraging classical coded exposure imaging technique and emerging implicit neural representation for videos, we tactfully embed the motion direction cues into the blurry image during the imaging process and develop a novel self-recursive neural network to sequentially retrieve the latent video sequence from the blurry image utilizing the embedded motion direction cues. To validate the effectiveness and efficiency of the proposed framework, we conduct extensive experiments on benchmark datasets and real-captured blurry images. The results demonstrate that our proposed framework significantly outperforms existing methods in quality and flexibility. The code for our work is available at https://github.com/zhihongz/BDINR