 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Directions Matter: Toward Structured and Task-Aware Low-Rank Adaptation
Mar 15, 2026Low-Rank Adaptation (LoRA) has become a cornerstone of parameter-efficient fine-tuning (PEFT). Yet, its efficacy is hampered by two fundamental limitations: semantic drift, by treating all update directions with equal importance, and structural incoherence, from adapting layers independently, resulting in suboptimal, uncoordinated updates. To remedy these, we propose StructLoRA, a framework that addresses both limitations through a principled, dual-component design: (1) an Information Bottleneck-guided filter that prunes task-irrelevant directions to mitigate semantic drift, and (2) a lightweight, training-only graph-based coordinator that enforces inter-layer consistency to resolve structural incoherence. Extensive experiments across large language model , vision language model, and vision model (including LLaMA, LLaVA, and ViT) demonstrate that StructLoRA consistently establishes a new state-of-the-art, outperforming not only vanilla LoRA but also advanced dynamic rank allocation and sparsity-based methods. Notably, the benefits are particularly pronounced in challenging low-rank and low-data regimes. Crucially, since our proposed modules operate only during training, StructLoRA enhances performance with zero additional inference cost, advancing the focus of PEFT -- from mere parameter compression to a more holistic optimization of information quality and structural integrity.
ColorConceptBench: A Benchmark for Probabilistic Color-Concept Understanding in Text-to-Image Models
Jan 23, 2026While text-to-image (T2I) models have advanced considerably, their capability to associate colors with implicit concepts remains underexplored. To address the gap, we introduce ColorConceptBench, a new human-annotated benchmark to systematically evaluate color-concept associations through the lens of probabilistic color distributions. ColorConceptBench moves beyond explicit color names or codes by probing how models translate 1,281 implicit color concepts using a foundation of 6,369 human annotations. Our evaluation of seven leading T2I models reveals that current models lack sensitivity to abstract semantics, and crucially, this limitation appears resistant to standard interventions (e.g., scaling and guidance). This demonstrates that achieving human-like color semantics requires more than larger models, but demands a fundamental shift in how models learn and represent implicit meaning.
Trade in Minutes! Rationality-Driven Agentic System for Quantitative Financial Trading
Oct 06, 2025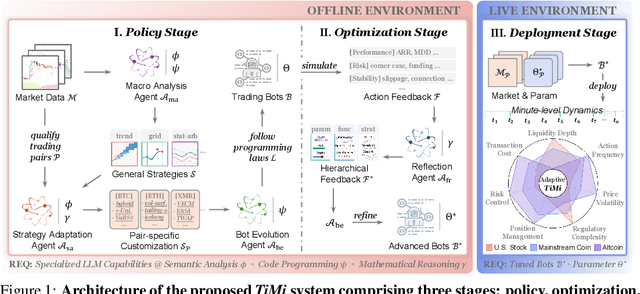
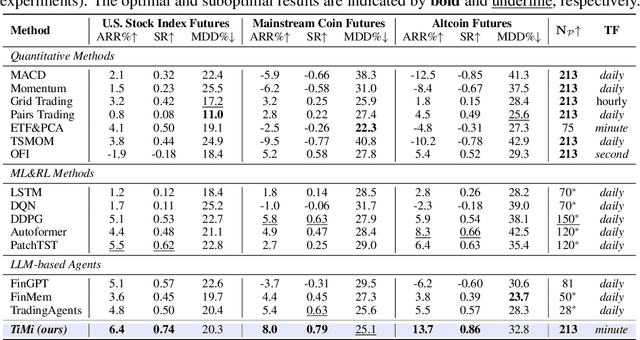
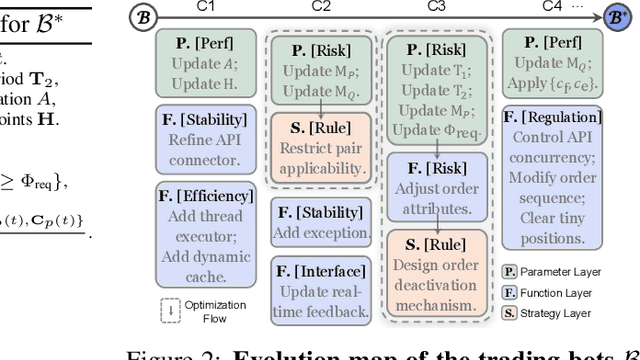
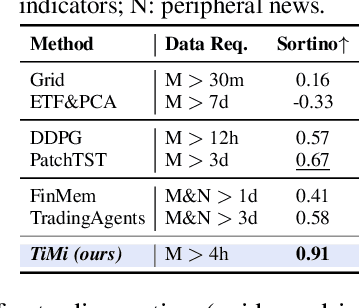
Recent advancements in large language models (LLMs) and agentic systems have shown exceptional decision-making capabilities, revealing significant potential for autonomic finance. Current financial trading agents predominantly simulate anthropomorphic roles that inadvertently introduce emotional biases and rely on peripheral information, while being constrained by the necessity for continuous inference during deployment. In this paper, we pioneer the harmonization of strategic depth in agents with the mechanical rationality essential for quantitative trading. Consequently, we present TiMi (Trade in Minutes), a rationality-driven multi-agent system that architecturally decouples strategy development from minute-level deployment. TiMi leverages specialized LLM capabilities of semantic analysis, code programming, and mathematical reasoning within a comprehensive policy-optimization-deployment chain. Specifically, we propose a two-tier analytical paradigm from macro patterns to micro customization, layered programming design for trading bot implementation, and closed-loop optimization driven by mathematical reflection. Extensive evaluations across 200+ trading pairs in stock and cryptocurrency markets empirically validate the efficacy of TiMi in stable profitability, action efficiency, and risk control under volatile market dynamics.
Unsupervised Exposure Correction
Jul 23, 2025Current exposure correction methods have three challenges, labor-intensive paired data annotation, limited generalizability, and performance degradation in low-level computer vision tasks. In this work, we introduce an innovative Unsupervised Exposure Correction (UEC) method that eliminates the need for manual annotations, offers improved generalizability, and enhances performance in low-level downstream tasks. Our model is trained using freely available paired data from an emulated Image Signal Processing (ISP) pipeline. This approach does not need expensive manual annotations, thereby minimizing individual style biases from the annotation and consequently improving its generalizability. Furthermore, we present a large-scale Radiometry Correction Dataset, specifically designed to emphasize exposure variations, to facilitate unsupervised learning. In addition, we develop a transformation function that preserves image details and outperforms state-of-the-art supervised methods [12], while utilizing only 0.01% of their parameters. Our work further investigates the broader impact of exposure correction on downstream tasks, including edge detection, demonstrating its effectiveness in mitigating the adverse effects of poor exposure on low-level features. The source code and dataset are publicly available at https://github.com/BeyondHeaven/uec_code.
A Comprehensive Evaluation on Quantization Techniques for Large Language Models
Jul 23, 2025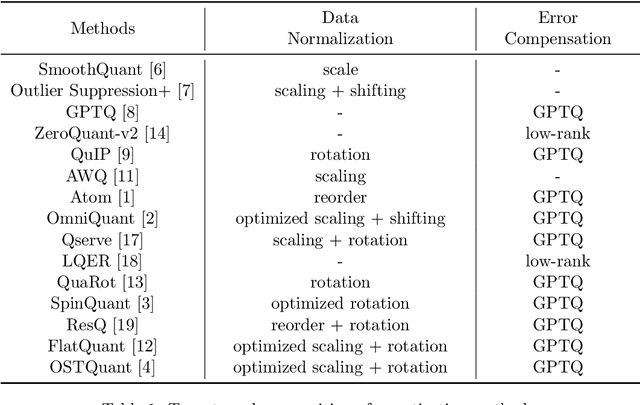
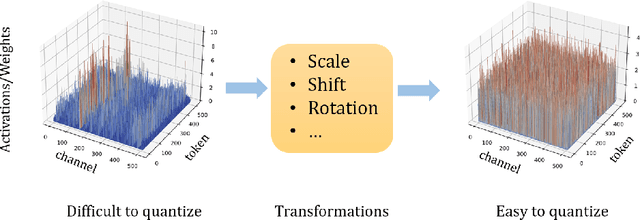
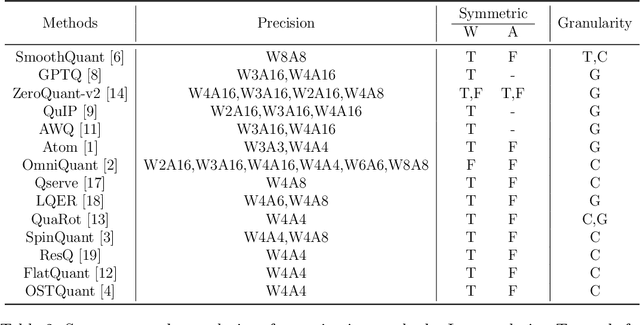
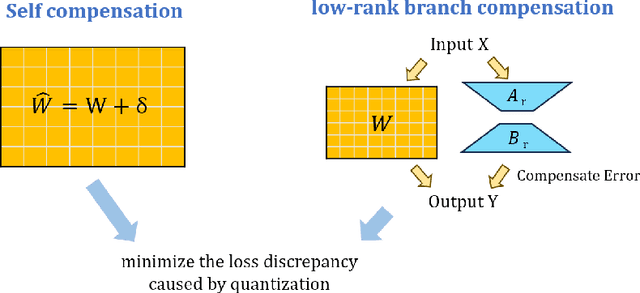
For large language models (LLMs), post-training quantization (PTQ) can significantly reduce memory footprint and computational overhead. Model quantization is a rapidly evolving research field. Though many papers have reported breakthrough performance, they may not conduct experiments on the same ground since one quantization method usually contains multiple components. In addition, analyzing the theoretical connections among existing methods is crucial for in-depth understanding. To bridge these gaps, we conduct an extensive review of state-of-the-art methods and perform comprehensive evaluations on the same ground to ensure fair comparisons. To our knowledge, this fair and extensive investigation remains critically important yet underexplored. To better understand the theoretical connections, we decouple the published quantization methods into two steps: pre-quantization transformation and quantization error mitigation. We define the former as a preprocessing step applied before quantization to reduce the impact of outliers, making the data distribution flatter and more suitable for quantization. Quantization error mitigation involves techniques that offset the errors introduced during quantization, thereby enhancing model performance. We evaluate and analyze the impact of different components of quantization methods. Additionally, we analyze and evaluate the latest MXFP4 data format and its performance. Our experimental results demonstrate that optimized rotation and scaling yield the best performance for pre-quantization transformation, and combining low-rank compensation with GPTQ occasionally outperforms using GPTQ alone for quantization error mitigation. Furthermore, we explore the potential of the latest MXFP4 quantization and reveal that the optimal pre-quantization transformation strategy for INT4 does not generalize well to MXFP4, inspiring further investigation.
Towards Extreme Pruning of LLMs with Plug-and-Play Mixed Sparsity
Mar 14, 2025N:M structured pruning is essential for large language models (LLMs) because it can remove less important network weights and reduce the memory and computation requirements. Existing pruning methods mainly focus on designing metrics to measure the importance of network components to guide pruning. Apart from the impact of these metrics, we observe that different layers have different sensitivities over the network performance. Thus, we propose an efficient method based on the trace of Fisher Information Matrix (FIM) to quantitatively measure and verify the different sensitivities across layers. Based on this, we propose Mixed Sparsity Pruning (MSP) which uses a pruning-oriented evolutionary algorithm (EA) to determine the optimal sparsity levels for different layers. To guarantee fast convergence and achieve promising performance, we utilize efficient FIM-inspired layer-wise sensitivity to initialize the population of EA. In addition, our MSP can work as a plug-and-play module, ready to be integrated into existing pruning methods. Extensive experiments on LLaMA and LLaMA-2 on language modeling and zero-shot tasks demonstrate our superior performance. In particular, in extreme pruning ratio (e.g. 75%), our method significantly outperforms existing methods in terms of perplexity (PPL) by orders of magnitude (Figure 1).
Revisiting Large Language Model Pruning using Neuron Semantic Attribution
Mar 03, 2025
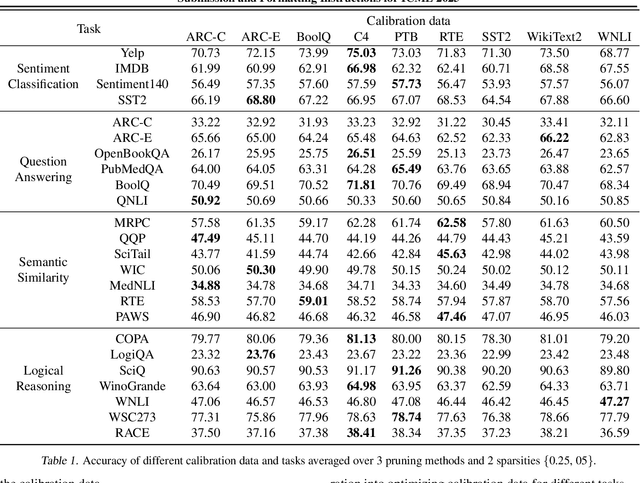

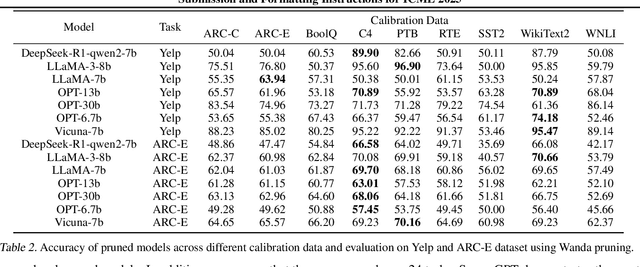
Model pruning technique is vital for accelerating large language models by reducing their size and computational requirements. However, the generalizability of existing pruning methods across diverse datasets and tasks remains unclear. Thus, we conduct extensive evaluations on 24 datasets and 4 tasks using popular pruning methods. Based on these evaluations, we find and then investigate that calibration set greatly affect the performance of pruning methods. In addition, we surprisingly find a significant performance drop of existing pruning methods in sentiment classification tasks. To understand the link between performance drop and pruned neurons, we propose Neuron Semantic Attribution, which learns to associate each neuron with specific semantics. This method first makes the unpruned neurons of LLMs explainable.
Object Pose Estimation via the Aggregation of Diffusion Features
Mar 27, 2024Estimating the pose of objects from images is a crucial task of 3D scene understanding, and recent approaches have shown promising results on very large benchmarks. However, these methods experience a significant performance drop when dealing with unseen objects. We believe that it results from the limited generalizability of image features. To address this problem, we have an in-depth analysis on the features of diffusion models, e.g. Stable Diffusion, which hold substantial potential for modeling unseen objects. Based on this analysis, we then innovatively introduce these diffusion features for object pose estimation. To achieve this, we propose three distinct architectures that can effectively capture and aggregate diffusion features of different granularity, greatly improving the generalizability of object pose estimation. Our approach outperforms the state-of-the-art methods by a considerable margin on three popular benchmark datasets, LM, O-LM, and T-LESS. In particular, our method achieves higher accuracy than the previous best arts on unseen objects: 98.2% vs. 93.5% on Unseen LM, 85.9% vs. 76.3% on Unseen O-LM, showing the strong generalizability of our method. Our code is released at https://github.com/Tianfu18/diff-feats-pose.
Gradient-Guided Modality Decoupling for Missing-Modality Robustness
Feb 26, 2024


Multimodal learning with incomplete input data (missing modality) is practical and challenging. In this work, we conduct an in-depth analysis of this challenge and find that modality dominance has a significant negative impact on the model training, greatly degrading the missing modality performance. Motivated by Grad-CAM, we introduce a novel indicator, gradients, to monitor and reduce modality dominance which widely exists in the missing-modality scenario. In aid of this indicator, we present a novel Gradient-guided Modality Decoupling (GMD) method to decouple the dependency on dominating modalities. Specifically, GMD removes the conflicted gradient components from different modalities to achieve this decoupling, significantly improving the performance. In addition, to flexibly handle modal-incomplete data, we design a parameter-efficient Dynamic Sharing (DS) framework which can adaptively switch on/off the network parameters based on whether one modality is available. We conduct extensive experiments on three popular multimodal benchmarks, including BraTS 2018 for medical segmentation, CMU-MOSI, and CMU-MOSEI for sentiment analysis. The results show that our method can significantly outperform the competitors, showing the effectiveness of the proposed solutions. Our code is released here: https://github.com/HaoWang420/Gradient-guided-Modality-Decoupling.
TDViT: Temporal Dilated Video Transformer for Dense Video Tasks
Feb 14, 2024Deep video models, for example, 3D CNNs or video transformers, have achieved promising performance on sparse video tasks, i.e., predicting one result per video. However, challenges arise when adapting existing deep video models to dense video tasks, i.e., predicting one result per frame. Specifically, these models are expensive for deployment, less effective when handling redundant frames, and difficult to capture long-range temporal correlations. To overcome these issues, we propose a Temporal Dilated Video Transformer (TDViT) that consists of carefully designed temporal dilated transformer blocks (TDTB). TDTB can efficiently extract spatiotemporal representations and effectively alleviate the negative effect of temporal redundancy. Furthermore, by using hierarchical TDTBs, our approach obtains an exponentially expanded temporal receptive field and therefore can model long-range dynamics. Extensive experiments are conducted on two different dense video benchmarks, i.e., ImageNet VID for video object detection and YouTube VIS for video instance segmentation. Excellent experimental results demonstrate the superior efficiency, effectiveness, and compatibility of our method. The code is available at https://github.com/guanxiongsun/vfe.pytorch.